This release brings a set of stability and compatibility improvements across
multiple platforms and components:
fruity: Fix PortableCoreDevice flush infinite loop, by reviving the call to
handle_events_completed during FLUSHING state so that pending_usb_ops can
get emptied eventually. Thanks to @mrmacete.
compiler: Rename conflictful Go symbols. Thanks to @NSEcho.
compiler: Load backend through memfd with fallback, so we retain the benefits
of avoiding temporary files when possible.
linux: Fix system session when memfd is restricted (observed in the Termux
environment on Android).
elf-module: Make {Section,Symbol}Details boxed, enabling bindings to pass/own
them safely by adding ref/copy/free semantics and updating Vala bindings.
process: Make ThreadDetails free func NULL-safe.
darwin-module: Make Image free function NULL-safe.
linux: Initialize variable to silence warning where the compiler can’t prove
the out-argument is initialized when returning TRUE.
linux: Handle interpreter-exec wrapper binaries (e.g. ld.so <program>), by
detecting AT_BASE == 0 and recovering the real program and interpreter
mappings from /proc/self/maps.
Small but important maintenance release fixing crashes in the recently
re-engineered Android Zygote instrumentation on BTI-enabled arm64 systems,
broadening compatibility across devices, alongside a GumJS crash fix and
improved out-of-the-box support for Termux environments.
android: Place the zymbiote payload in a safer address range, avoiding
conflicts with memory ranges used by Zygote (reverted before the forked
app/service gets a chance to care).
android: Fix crash in the new, minimally intrusive Zygote instrumentation on
BTI-enabled arm64 systems by ensuring the injected payload is built with BTI
enabled, so indirect branches into it do not fault.
android: Tweak the statically linked OpenSSL to automatically use Termux’s
ca-certificates, allowing Frida.PackageManager (frida-pm) to work
out-of-the-box on Termux without requiring SSL_CERT_FILE to be set.
compiler: Fix loading of the backend on Android by avoiding the memfd path,
which could fail due to reopening the same underlying file with more
restrictive permissions. We now use a temporary file even where memfd is
supported.
gumjs: Avoid freeing a NULL ffi_closure when NativeCallback construction fails
(e.g. invalid argument types), preventing libffi from crashing and allowing
the JavaScript exception to propagate instead.
Thanks to @leg1tsoul for the GumJS fix, and to @as0ler and
@ApkUnpacker for their help tracking down the Android Zygote instrumentation
issues.
Quite excited about this one. On Android, we’ve eliminated our two biggest
sources of system instability: our historically intrusive instrumentation of
Zygote and system_server. Thanks to @mrmacete, we also now have significantly
improved DebugSymbol performance on Apple platforms, along with several
stability fixes. And beyond that, there’s been a broad sweep of robustness
improvements across the board.
Android
Let’s take a closer look at the Android-side stability work.
Before diving into Zygote and system_server, it’s worth calling out an important
piece of groundwork: our SELinux userspace library has been rebased onto a much
newer upstream to support modern binary policy formats, while retaining Android
M–specific behavior, thanks to @AeonLucid.
Historically, our Zygote handling relied on injecting frida-agent in order to
observe fork() transitions via our child gating feature. We had to inject code
there because the system does not allow spawning an app in a suspended state
unless it is marked debuggable.
This injection was expensive: it required stopping and restarting threads,
left artifacts behind in all future child processes, and was brittle in a number
of ways.
For example, we had to carefully hide our file descriptors to prevent Zygote
from abort()ing. And if frida-core—typically as part of frida-server—performed
the injection at an unfortunate moment, such as during an app or service launch,
it could crash that process and bring down most of user space.
We mitigated this by ptrace()ing Zygote until it reached a syscall we deemed
indicative of idleness. I never got around to implementing the same logic for
teardown, though, so that part was always risky.
Worse still, the syscall-tracing machinery itself had bugs and would fail
randomly. I initially set out to fix those, but before shipping this release I
had a different idea: what if we could replace all of this complexity with
something lightweight and purpose-built?
I paired up with @hsorbo and got to work. The solution we landed on performs
all instrumentation from the outside and avoids ptrace() entirely, relying
instead on /proc/$pid/mem:
We open /proc/$pid/mem and scan relevant memory ranges to locate the
ArtMethod (or Dalvik equivalent) for
android.os.Process.setArgV0Native(). Since this is a native method
implemented in libandroid_runtime.so, we first identify the module’s base
address and then use Gum’s ELF parser (Gum.ElfModule) to compute the exact
function pointer. This method is also ideal for child gating: by the time it
runs, the SELinux transition has completed and the package name is known,
conveniently passed in as the new argv0.
Instead of inline hooking (as we did previously, and technically still
could), we simply swap out the function pointer inside the method struct.
We select a memory range containing executable code that has either already
run and will not run again, or will only run after the fork(), such as code
reached when the child uses certain multimedia APIs.
We write our “zymbiote” payload into that region. It’s small—currently
920 bytes on arm64—so we don’t need to clobber much.
The method struct’s function pointer is updated to point at the payload.
The payload restores the original function pointer, calls the real
implementation, and then connects to an abstract UNIX socket. It transmits
its PID, PPID, and package name, then waits for an ACK.
If there’s a pending spawn() request for that package, or spawn gating is
enabled, frida-core withholds the ACK until the application calls resume()
with the given PID. This gives the client a chance to attach() and apply
early instrumentation.
If connect() fails or a socket error occurs, the payload simply returns—so a
frida-core crash won’t take down user space.
If communication succeeds and an ACK is received, the payload tail-calls
raise(SIGSTOP). The tail-call is important to make the next step safe.
Once frida-core observes the process in a stopped state—meaning it is no
longer executing inside the payload—it rolls back all changes and sends
SIGCONT. Any children not instrumented by Frida are left completely
pristine. Previously, this was not the case, and some apps would crash due
to RASP systems detecting lingering (albeit inert) artifacts from a prior
frida-agent load.
That’s the approach we ended up with. Fairly straightforward in the end. The
entire payload is just 295 lines of C (including a small amount of inline
assembly for the tail-call). And since ptrace() is no longer involved at all,
interop with other tools is significantly improved.
The system_server side was a much smaller effort. We already had a tiny helper,
frida-helper.dex, used on non-rooted Android. We’d write it to a temporary
file, point app_process at it, and communicate with it to enumerate installed
apps, running processes, and so on.
This release generalizes that approach: the helper is now shared between the
Linux and Droidy backends and expanded to support additional request types,
such as launching activities and sending broadcasts.
Beyond the obvious stability benefits, this also means frida-core no longer
depends on frida-java-bridge. As a result, libart.so compatibility issues
introduced by future OS versions or Play Store updates won’t compromise
Frida’s core functionality.
The one downside of no longer injecting an internal agent into system_server is
that we lose the ability to disable the system’s default app launch timeout.
I consider this acceptable, as the same effect can still be achieved by
injecting a tiny script into system_server if needed.
EOF
This release also includes a slew of other goodies. Be sure to check out the
changelog below for the full details.
Enjoy!
Changelog
android: Rebase SELinux userspace library onto a newer upstream to support
modern binary policy formats while preserving Android M quirks.
(Thanks to @AeonLucid)
android: Move to lightweight Zygote hooking by patching
android.os.Process.setArgV0Native() to trampoline through a tiny payload and
connect back to frida-core for instrumentation. This replaces the previous
internal-agent-in-Zygote approach and removes the dependency on
frida-java-bridge. (Co-authored-by: @hsorbo)
android: Migrate to frida-helper.dex universally, eliminating code injection
into system_server.
libc-shim: Fix a long-standing Android SELinux getline() allocator mismatch
leading to heap corruption and undefined behavior.
darwin: Speed up Objective-C method lookup by address via a rewritten
resolver, and replace the symbolutil cache invalidator with
GumModuleRegistry signals. The latter fixes a SIGBUS in a swizzled dyld
notification scenario. (Thanks to @mrmacete)
fruity: Throw CLOSED on TCP writes performed in a closed state to avoid an
infinite polling loop. (Thanks to @mrmacete)
fruity: Fix a USB startup/shutdown race that could deadlock the USB worker,
making enumeration and shutdown deterministic.
linux: Fix ptrace signal waiter forwarding and syscall tracing desync, making
spawn/attach flows more robust in the presence of ptrace-internal stops and
real signals.
linux: Fix arm64 ucontext record parsing. (Thanks to @MarlinDiary)
android: Handle __pthread_start symbol suffixes on newer Android releases so
thread enumeration no longer spuriously treats the system as unsupported.
(Thanks to @MarlinDiary)
android: Handle APK libs in enumerateRanges(). (Thanks to @monkeywave)
arm64: Avoid attempting fast Interceptor patching when it is not feasible.
(Thanks to @Jiay1C)
interceptor: Add a FORCE attach flag to allow inline hooking even when the
function is too small to safely patch. This may overwrite bytes past the end
and should be used with care.
elf: Forcibly hook the RTLD notifier when needed, and improve ELF module hash
parsing and validation (including correct GNU hash parsing for ELF32).
frida-node: Use Symbol descriptions instead of coercion, avoiding
“Cannot convert a Symbol value to a string” errors in XPC-related usage.
(Thanks to @mrmacete)
This release improves module export accuracy on Windows, makes helper spawning
more robust on Darwin, and delivers major enhancements for Swift users via
SwiftPM and the new FridaCore xcframework:
windows: Fix Module export metadata so the type property accurately reflects
the real export type instead of always reporting functions. Thanks
@Ninja3047!
darwin: Use DO_NOT_REAP_CHILD when spawning helper, making helper launch more
robust on systems booted without -arm64e_preview_abi by insulating the host
process from signal-related side effects.
swift: Add SwiftPM package manifest and support; rename Frida_Private module
to FridaCore; implement LocalizedError (when Foundation is available) and add
error description; refine the RPC API and allow discarding call results;
deduplicate Device instances and fix a yield/finish race in AsyncEventSource.
swift: Add bindings for AuthenticationService, PortalService,
EndpointParameters, PackageManager, and Compiler; add minimal GLib bindings
(MainLoop, File, Uuid, TlsCertificate, DateTime/TimeZone) and move GLib and
JSONGLib into a sub-namespace.
ci: Publish frida-core releases with .xcframework.
darwin-mapper: Added validation for local shared cache lookups. Symbols
that appear to live in the cache can no longer resolve to a dylib lurking
outside it (e.g. an introspection build of libsystem_pthread.dylib). Huge
thanks to @hsorbo for pairing on the investigation!
Fresh cups of ☕ and a heap of commits later, we’re back with a feature-packed
release. Highlights include a smarter compiler, sturdier Darwin internals, and
a massive Swift overhaul — the bindings are now async/await-first,
delegate-free, and largely platform-agnostic.
Highlights
compiler: Added platform and externals options to CompilerOptions,
and plumbed them all the way down to the Go backend.
This lets frida-compile (and Frida.Compiler) tailor its output to your
target platform and treat selected modules as externals — e.g. when building
a plugin for a GumJS agent, where the agent’s exposed API should be linked
at runtime instead of bundled.
(Thanks @leonitousconforti)
darwin: Rewrote query_shared_cache_range() to parse the dyld shared
cache header instead of walking VM regions from the base address found in
AllImageInfos. This eliminates guesswork and ensures correct ranges even
once pages get copy-on-written.
(Thanks for the pair-programming, @hsorbo)
darwin: AllImageInfos now reports the Dyld Shared Cache UUID and slide.
(Thanks for the pair-programming, @hsorbo)
simmy: spawn() grew proper argv and env wiring, so simulators now
behave more like real devices.
frida-node: Generated from_value() helpers now include inherited
properties, so options like externals propagate correctly.
frida-python: Fixed a tiny but leaky corner in PackageManager specs
option parsing.
Swift bindings: a modern, cross-platform makeover 🍎
The Frida Swift bindings have been extensively refactored to be idiomatic
Swift, concurrency-first, and cross-platform.
Async/await everywhere — most APIs now use Swift Concurrency and support
Task cancellation via GCancellable.
Delegates removed — delegate-based callbacks have been replaced with
async event streams (AsyncStream), making event handling ergonomic and
composable.
Thread-friendly — api: Support invocation from any thread enables safe
invocation from non-main threads. (Thanks for the pair-programming,
@hsorbo.)
Pure Swift core + cross-platform — the core bindings are now
Foundation and Dispatch-free and use pure Swift types (binary data represented
as [UInt8]). Two small gaps remain: JSON encoding/decoding in the Marshal
helpers currently use Foundation; a non-Foundation fallback will be added
later.
SwiftUI-friendly — the new DeviceListModel, a
@MainActor ObservableObject that exposes @Published devices and
discoveryState for smooth SwiftUI integration.
Icon portability — platform-specific image handling replaced by a
portable Icon enum with platform adapters for CGImage, NSImage,
UIImage, and SwiftUI.Image.
API stability improvements — public enums are annotated with @frozen
and some complex reference types are marked @unchecked Sendable where
necessary.
Note: frida-swift prebuilt binaries are not included in this release; if
you use the Swift bindings you should git clone and build from main to
get the latest changes.
Also note that the Swift bindings are still experimental and evolving —
while the new APIs are a big leap forward, they may continue to change until
the Swift layer stabilizes in an upcoming release.
importFridaimportSwiftUIstructDevicesView:View{@StateObjectprivatevarmodel=DeviceListModel(manager:DeviceManager())@StateprivatevarselectedDevice:Device?@Stateprivatevarsession:Session?varbody:someView{NavigationStack{List(model.devices,id:\.id){deviceinButton{Task{selectedDevice=devicesession=try?awaitdevice.attach(to:12345)}}label:{VStack(alignment:.leading){Text(device.name).font(.headline)Text(device.kind.rawValue).font(.subheadline).foregroundStyle(.secondary)}}}.navigationTitle("Frida Devices").overlay{ifmodel.devices.isEmpty{ProgressView("Searching for devices…")}}}}}
darwin: Revive app listing/launching on iOS ≥ 16 when running on rootful
systems. This brings frida-core commit dccb612 back to life after 8108d4d
broke it while fixing two Interceptor singleton leaks. It turns out the
leak in springboard.m was intentional, acting as init-once logic with no
teardown expected; without it, the instrumentation we apply gets reverted
right away. Kudos to @alexhude for the heads-up.
Spooky season brought a small batch of fixes and improvements:
simmy: Gracefully degrade features that rely on injecting into SpringBoard
whenever System Integrity Protection (SIP) is enabled. This means that
get_frontmost_application() and icon retrieval now fall back rather than
exploding.
simmy: Fix enumeration of installed apps when a subset of bundle IDs was
requested. Hat-tip to @hsorbo for the assist!
docs: Update the README’s Apple-certificate section to reflect the current
reality. Thanks to @gemesa for spotting and fixing the outdated bits!
A small but tasty follow-up release to keep the momentum going:
android: Bump frida-java-bridge in system-server, bringing in the latest
stability improvements:
android: Handle static trampoline fixups, so we roll back each ArtMethod to
its previous entrypoint, to avoid hooks being bypassed.
android: Synchronize ArtMethod class field post GC, so our replacement
ArtMethod instances don’t go stale, and cause undefined behavior.
Thanks for the pair-programming, @hsorbo.
devkit-assets: Upgrade GumJS example to the new Frida 17 GumJS API. Thanks to
@Hexploitable for making this happen.
freebsd: Wire up PTY support so spawn/attach operations depending on a
controlling terminal now work out of the box.
Time for another feature-packed release! Highlights:
simmy: Brand-new backend for talking to Apple’s simulators through
CoreSimulator.framework. Spawn apps, instrument processes, and generally
treat simulators like any other device – all from the comfort of Frida.
darwin: Support early instrumentation of dyld_sim, so you can attach and
load your scripts even at a point before the dynamic loader has finished
boot-strapping the simulated process.
darwin: Fix sysroot detection on the latest iOS 18 simulator, where
dyld_sim is now hidden from _dyld_image_count and
TASK_DYLD_ALL_IMAGE_INFO_64. Thanks to @CodeColorist for tracking this
one down!
fruity: Automatically unpair whenever we encounter an InvalidHostID
error, allowing the next pairing attempt to succeed. Great work by
@mrmacete!
android: Update system-server to frida-java-bridge 7.0.9. Changes:
Fix Java.deoptimize*() and Java.backtrace() on Android 16. Thanks
@hsorbo!
Fresh bits are ready! This release focuses on squeezing even more performance
out of our Fruity backend:
fruity: Batch datagram delivery to make cross-thread hand-off more
deterministic and reduce context-switch overhead.
ncm: Rework host→device scheduling. We now keep a rolling window of OUT
transfers and refill as soon as any URB completes, keeping the bulk pipe
busy and bumping HS throughput from ~29 MB/s to ~34 MB/s in our tests.
ncm: Switch to a fixed-slot NDP layout, turning the O(k²) “shrink until it
fits” packer into an O(k) one. On a 256 MiB transfer this drops layout time
from ~1.1 s to the noise floor.
Fresh beans, new features! This release brings exciting capabilities to our
Barebone and Fruity back-ends, and smooths out a few rough edges:
barebone: Add basic support for XNU injection, successfully tested on iOS
14.0 in QEMU. Co-authored with @hsorbo.
barebone: Expose underscore-prefixed CModule symbols so they are usable from
Frida scripts.
fruity: Fall back to usbmux whenever a tunnel times out or hits other
transport errors. Thanks to @Xplo8E for the nudge.
fruity: Handle CoreDevice pairing events, and match pairing requests and
responses using a FIFO instead of the sequence number. Huge thanks to
@hsorbo.
fruity: Deal with a handful of edge-cases during teardown. Kudos to
@mrmacete.
Fresh maintenance release bringing a handful of fixes and quality-of-life
improvements across the board:
gumjs: Ensure that onLeave is only invoked after its matching onEnter
actually ran, eliminating unpredictable behaviour when hooks are attached
mid-call. Thanks @mrmacete!
darwin-module: Swap-hook the lldb_image_notifier pointer in dyld’s “all
image infos” to keep the module registry functional even on modern iOS
devices where the notifier is just one instruction long. Cheers
@mrmacete!
barebone: Add try_remap_writable_pages().
barebone: Allow overriding query_rwx_support() to tailor RWX capability
probing to exotic platforms.
frida-node: Honour package-lock.json during the TypeScript stage to keep the
JS dependency tree fully deterministic.
This release brings several improvements to the Cloak API and module handling,
along with some essential updates and bug fixes. A special shout-out to
@AeonLucid for contributing to the Android support.
android: Updated frida-java-bridge in system-server to include the
improved ART offset lookup by @AeonLucid. See frida-java-bridge#362
for details.
cloak: Added support for Art::GetOsThreadStat on Android, addressing an
issue similar to frida-core#500, where Zygote waits for the process to
become single-threaded before continuing, otherwise it crashes. This change
accommodates the new usage of art::GetOsThreadStat. (Thanks to
@AeonLucid)
cloak: Plugged a memory leak in ThreadCountCloaker.dispose(), where we
were failing to chain up to GObject.dispose().
module: Added an optional get_version() virtual function.
module: Made most interface methods optional to reduce the amount of
boilerplate required for Barebone integrations.
darwin: Implemented Module.get_version(), exposing the
LC_SOURCE_VERSION when available.
darwin-module: Added source-version property to expose
LC_SOURCE_VERSION if present.
darwin-module: Added support for non-Darwin in-memory usage, e.g., inside
XNU.
We’re excited to announce Frida 17.2.12, which brings preliminary support for
running Gum without an operating system, significant enhancements to our
Barebone backend, and various improvements and fixes.
android: Bumped frida-java-bridge in system-server to include a fix
for incorrect ART class spec offset detection. This prevents crashes caused
by libart.so being updated independently of the SDK version, which previously
led to offset mismatches. The fix now uses runtime detection via known classes
instead of SDK heuristics, improving reliability across Android updates.
Massive thanks to @AeonLucid for spearheading this work — a truly
heroic effort that brings rock-solid reliability to Frida’s Android support
in the face of ever-changing ART internals.
gum: Added preliminary support for running without an operating system,
enabling Frida to run on bare-metal targets. The integrator overrides the
needed weak symbols with target-/firmware-specific ones. We have a
work-in-progress agent for XNU that lets us run JavaScript in Apple’s
OS kernels.
barebone: Added support for APRR in the arm64 backend (thanks for the
pair-programming @hsorbo).
barebone: Added support for R_AARCH64_PREL32 relocations (thanks @hsorbo),
improving compatibility with more ARM64 binaries.
barebone: Implemented Memory.protect(), providing the ability to change
memory protection on bare-metal targets.
fruity: Sprayed Gadget’s r-x pages before uploading to turn them into
debugger mappings (thanks to @hsorbo, @mrmacete, and @as0ler),
fixing issues on newer hardware generations.
buffer: Added new methods: read_bytes(), write_bytes(), write_int64(),
write_uint32(), write_int32(), write_uint16(), write_int16(),
write_uint8(), write_int8(), extending Buffer’s API for handling various
data types.
gumjs: Avoided regex for inline source map parsing to reduce stack usage,
improving stability on platforms with constrained stack sizes.
build: Added support for ‘armv6kz-‘ prefixed toolchains (thanks
@zetierhg), improving compatibility with more toolchains.
build: Fixed typings for Python < 3.9 (thanks @oriori1703), ensuring
compatibility with older Python versions.
build: Special-cased ld script for FreeBSD linker to fix build issues
(thanks @grimler), improving FreeBSD support.
devkit: Made symbol prefixing optional (thanks @Hexploitable), allowing
consumers to choose whether to prefix third-party symbols to avoid clashes.
Just when we thought we had it all figured out, software reminded us how hard it
can be! Thanks to @mrmacete, @hsorbo, and [@0xmurphy][], we quickly
addressed the issues and present you with the following fixes:
frida-node: Fix fdn_keep_alive_until() TSFN lifetime issue. We were setting
the TSFN to NULL, which led to crashes when other reference-holders tried to
schedule cleanup.
fruity: Fix issue when killing prewarmed targets. Killing a prewarmed process
at spawn time resulted in a “connection closed” error. This change catches the
error so it’s possible to spawn a fresh instance.
Quick bug-fix release addressing two important issues:
frida-node: Fix keep-alive ThreadSafeFunction teardown. Use
napi_release_threadsafe_function() in keep-alive scenarios so that
pending microtasks have time to run before the libuv handle is dropped.
This prevents “unsettled top-level await” during teardown. Co-authored by
@as0ler, @hsorbo, and @mrmacete.
barebone: Ensure RustModule C ABI entrypoints survive garbage collection.
Newer Rust toolchains use --gc-sections, which strips unused sections.
We refactored make_linker_script() to scan the Rust source for symbols
intended to be visible, and emit KEEP(*(.text.<symbol>)) directives so
those entrypoints are retained.
This time we’re bringing you preliminary iOS 26 support, and a bug-fix for our
Node.js bindings:
fruity: Added support for injecting the gadget on iOS targets where
debugger mappings are enforced (iOS 26) and we can’t flip the memory
protection back to executable from inside the target process. In such cases,
the gadget configuration will have code_signing set to required until
Interceptor supports enforced debugger mappings. Thanks @mrmacete!
device: Fixed an issue where the stdio option wasn’t passed through
spawn(), causing child processes to always inherit stdio. Co-authored by
@hsorbo.
We’re excited to announce the release of Frida 17.2.7, featuring significant
improvements to our Package Manager.
package-manager: Improve resolution and hoisting to mimic npm’s behavior
more closely. Co-authored with @hsorbo. Thanks for your help!
package-manager: Add install() option for role, achieving the
equivalent of npm install’s --save-* switches.
package-manager: Add install() option for omits, to achieve the
equivalent of npm install’s --omit=x switch.
package-manager: Improve handling of optional packages.
package-manager: Handle file modes when extracting on non-Windows systems.
package-manager: Fix the has_install_script logic to also take
preinstall and postinstall scripts into account.
meson: Clarify Vala build system instructions. The Vala README only
mentioned autotools instructions, and when Vala is compiled that way the
-frida suffix is not added to the version string, causing the frida-core
check for Vala to fail. We now clarify that Vala needs to be built from source
with Meson. Thanks to @grimler for pointing this out!
Exceptor needs to hook signal() and sigaction(), but they are in libc.
This leads to gum_mprotect() aborting because it cannot change libc’s
read-only mapping. This fix prevents the crash observed when using
frida-server or frida-inject on Android 14 and 15 AVDs.
This release brings important fixes and improvements to Frida. Here are the
highlights:
frida-node: Keep TSFN alive until promise settles, preventing a race condition
that could cause Node.js to exit early with a “Detected unsettled top-level
await” warning. Kudos to @mrmacete and @hsorbo for helping track
this one down.
frida-node: Simplify findMatchingDevice() (co-authored by @hsorbo).
package-manager: Only bump if explicitly requested.
package-manager: Fix the dev logic.
docs: Fix Mapper URL in README (thanks to @cmdlinescan).
Another quick bug-fix release to improve our package manager, where @hsorbo
and I have been hard at work. Here’s what’s new:
package-manager: Fix dependency install deadlock. A deadlock could occur
when a package’s sub-dependency was also a dependency of another package
higher up in the installation stack. The sub-dependency would wait for the
higher-level package to be physically installed, but that package would not
complete its own installation until its sub-dependencies were resolved,
creating a circular wait.
package-manager: Improve manifest handling to get us closer to npm’s
behavior. (Co-authored by @hsorbo.)
package-manager: Fixed the lockfile up-to-date path.
package-manager: Only report installed packages. The top-level packages that
were left untouched are no longer included. Also simplified the install()
logic.
I’m thrilled to announce the release of Frida 17.2.0. This release focuses on
making package discovery dead-simple.
Here’s how easy it is to discover existing Frida-specific packages:
Consuming any of them is just as easy:
Highlights
🔍 frida-pm search – zero-noise results (filters by keywords:frida-gum).
📦 One-command install – frida-pm install <pkg> works even without
Node.js.
🧩 Programmatic API – identical surface from Python, C, etc.
What you see here is the frida-pm CLI tool, introduced in frida-tools 14.2.0.
It’s less than 300 lines of Python code, as it’s only a thin wrapper around the
underlying Frida.PackageManager implementation.
Power users and package maintainers will still typically use npm/yarn/etc., but
I feel like requiring first-time Frida users to also familiarize themselves with
the larger JavaScript ecosystem is likely to overwhelm and confuse.
What’s neat about frida-pm / Frida.PackageManager is that searches only surface
Frida-specific packages. This is implemented by baking keywords:frida-gum into
the search query.
For those of you maintaining Frida-specific packages, make sure you add
frida-gum into your package.json’s keywords field. If your package is a
language/runtime bridge, also make sure you add frida-gum-bridge as well.
So discoverability is one of the key features here. Another is that it can be
run on systems without Node.js + npm. While we do use npm’s registry as our
default backend, you can point it at any registry you like.
You also get programmatic access to all of the functionality. For example, if
you want to use the Python bindings to make a search:
$ python install.py
PackageInstallResult(packages=[<2 packages>])[Package(name="frida-java-bridge", version="7.0.4", description="Java runtime interop from Frida"),
Package(name="frida-il2cpp-bridge", version="0.12.0", description="A Frida module to dump, trace or hijack any Il2Cpp application at runtime, without needing the global-metadata.dat file.")]$
So now that we’ve looked at the PackageManager API being used from Python, I
should probably mention that it is (almost) just as easy to use this API from C:
(The top of frida-core-example.c has an example command-line tailored to the
specific OS/arch that the devkit is for.)
Note that opts can be omitted by passing NULL, in which case the packages
defined in package.json will be installed if they aren’t already, or their
versions don’t match. And just like with npm, if you don’t have a package.json
file and simply go ahead and install some packages, a package.json will be
created for you.
This release also includes some other improvements and fixes:
Critical bug-fix: restores compatibility with Android 14–15—accidentally broken
in the last release while adding Android 16 support. Thanks to
@tbodt for the fix.
Excited to announce Frida 17.1.4, which brings several important fixes and
improvements — most notably Android 16 support. Here’s what’s new:
Compiler: Switched esbuild’s platform to node, so package.jsonmain and exports are resolved the Node.js way, restoring compatibility for
packages that rely on it. Kudos to @hsorbo for helping track this down.
Plist: Fixed offsetIntSize for binary property lists, ensuring
compatibility with Core Foundation. Thanks to @mrmacete for helping track
this down.
Plist: Empty dicts and arrays in XML output now use self-closing tags
(e.g. <dict/>), matching Apple’s encoder.
Android: Bumped frida-java-bridge to 7.0.3 in the system_server
agent, adding Android 16 support. Thanks to @tbodt — and shout-out to
@thinhbuzz for contributing an error-handling patch that resolves
inoperability on some Android 12 devices.
Darwin: Bumped frida-objc-bridge to 8.0.5 in internal agents.
GumJS: Fixed big-endian handling of FFI arguments.
We recommend all users upgrade at their earliest convenience. Make sure you also
upgrade to frida-tools 14.1.2, also just released.
This release brings a series of improvements and bug fixes across various
components. Here are the highlights:
Renamed conflicting Go symbols in the Compiler backend to avoid conflicts
when linking into a Go binary. This ensures compatibility when integrating
with Go projects.
On Linux, fixed issues related to the thread list anchor to prevent false
positives. Previously, the anchor might be incorrectly added to the thread
list, leading to incorrect behavior.
Corrected the QuickJS big-endian bytecode check in both the gadget and
GumJS. The previous check was incorrect on big-endian systems.
Added version defines and macros to the API, providing more explicit version
information for developers.
Firstly, we’ve switched to ESBuild and typescript-go in the Compiler backend,
resulting in massively improved performance, and reduced our maintenance burden
by no longer having to maintain a bundler. We also added options to configure
the output and bundle format, and support disabling type checks.
Secondly, we now finally ship binaries for Windows/ARM64. This was unblocked by
GitHub making Windows ARM64 hosted runners available to the public.
Special thanks to @mrmacete for plugging Interceptor singleton leaks, and to
@fesily for implementing Module#enumerateSections() on Windows, as well as
improving Module#enumerateImports() so the slot is exposed.
Here’s the full list of changes:
Compiler improvements:
Switched to ESBuild and typescript-go in the Compiler backend.
Added options to configure the output and bundle format, and support
disabling type checks.
Windows/ARM64 support:
CI updated to publish binaries for Windows/arm64.
Contributions from our community:
Fixed 32-bit ARM breakpoint logic for Thumb addresses.
device: Allow agent sessions to detach before release, to be robust
against scenarios where an out-of-order detach could lead to an indefinite
hang at release time. Thanks @mrmacete!
darwin: Dispose module resolver indexes to avoid leaking native modules in
scenarios where short-lived resolvers are used (for example, on different
tasks). Thanks @mrmacete!
stalker: Handle blocks without inline cache entries.
Quick bug-fix release with an important contribution from @londek. In this
release, we’ve addressed the following issue:
darwin: Fixed the launchd agent, which was still using an old GumJS API
that has since been removed. This prevented the agent from functioning on
jailbroken iOS/iPadOS/tvOS systems.
Quick bug-fix release to fix agents generated by the latest frida-compile.
We need to explicitly declare internal agents as ESM now that the TypeScript
compiler is more conformant and ends up generating CommonJS glue code. This
fixes our Darwin and Android agents, as well as the Barebone backend’s script
runtime.
After countless cups of coffee and fun coding sessions, @hsorbo and I are
excited to bring you Frida 17.0.0. After nearly three years since the last major
bump, and struggling to find the right time to make breaking changes, we decided
it is finally time to do so.
Runtime Bridges
The main thing that’s been bothering us for quite some time was the fact that
our runtime bridges, i.e. frida-{objc,swift,java}-bridge, were bundled with
Frida’s GumJS runtime. This came with some major pain points:
Inertia: Being tied to Frida’s release cycle.
Bloat: For users who don’t need a particular runtime bridge.
Scalability: We’d like to see bridges for all kinds of runtimes, but the more
we add to Frida the more we’ll struggle with inertia and bloat.
Discoverability: Community-maintained bridges being harder to discover, as
they require a different workflow for consumption.
I’ve been hesitant to stop bundling them though, as requiring a build step for
custom agents seemed like it would add too much friction. And the thought of
breaking examples in books, blog posts, CodeShare etc. didn’t sit well with
me either.
The friction aspect is why we introduced the frida.Compiler API back in
15.2, along with frida-tools shipping a CLI tool, frida-compile, built on
top of it. Our REPL was also improved to support loading .ts (TypeScript)
directly, making use of frida.Compiler behind the scenes.
That’s still an extra step though, which is too much for one-off scripts and
early prototyping work using the Frida REPL or frida-trace. And, it would
break a lot of examples. To remedy this, the just-released frida-tools 14.0.0
bakes the three bridges into its REPL and frida-trace agents.
Our bridges have also been migrated to ESM, so they can be consumed by the
latest versions of frida-compile. (Shout-out to @yotamN for migrating
frida-java-bridge ♥️)
Those of you building Frida from source may also notice an improvement in build
times. Since we’re no longer bundling the bridges, we could finally get rid of
Gum’s frida-compile dependency, and stop depending on Node.js + npm for Gum
itself.
We still had GumJS’ own runtime, which implements built-ins such as
console.log(), but porting it to ESM and simply baking in each module
individually meant we no longer needed a JavaScript bundler. This means faster
build times for Gum itself: on a Linux-powered i9-12900K system, builds dropped
from ~24s → ~6s.
You can see a quick reference tutorial inside bridges.
Legacy-style enumeration APIs
Back in the day, our synchronous enumeration APIs all looked like this:
There was also an equivalent Sync-suffixed method, like
Process.enumerateModulesSync() for this particular example. The idea was that
the underlying implementation could become asynchronous, but for the time being
most of them weren’t, so the Sync-suffixed implementation was just a thin
wrapper around the asynchronous-looking API.
Later, as more and more platforms were supported, I realized that all of the
pretend asynchronous implementations turned out to always be quick and cheap
operations. So offering an asynchronous flavor was going to be pointless. And
for the few that were truly asynchronous from the beginning, like
Memory.scan(), it still made sense to have them stay that way.
I was hesitant to break the API though, so I opted to add a check to each
unsuffixed implementation, so it would behave like its Sync-suffixed counterpart
if the callbacks argument was omitted. Wanting to migrate users off the
old-style API, I made sure to update our TypeScript bindings so only the modern
flavors were included.
The equivalent in modern style would then look like this:
Where Process.enumerateModules() returns an array of Module objects.
These legacy-style APIs are now finally gone. Those of you writing your agents
in TypeScript won’t need to do anything, unless you’re using ancient versions of
our typings.
The legacy versions of these are now also gone, and have been gone from our
TypeScript bindings for as long as the legacy-style enumeration APIs. So this
change should also not be noticable to most of you.
Static Module APIs
Now for the breaking changes that also affect users who were current with the
TypeScript bindings, prior to 19.0.0, released together with Frida 17. The
following static Module methods are now gone:
Module.ensureInitialized()
Module.findBaseAddress()
Module.getBaseAddress()
Module.findExportByName()
Module.getExportByName()
Module.findSymbolByName()
Module.getSymbolByName()
These are all straight-forward to migrate away from.
But first, let’s cover the odd one out:
Module.getSymbolByName(null,'open')
This is now accomplished like this:
Module.getGlobalExportByName('open')
For the rest, you first need to look up the Module, and then access the desired
property or method on it. For example, instead of:
The equivalent for Module.getBaseAddress() is thus:
Process.getModuleByName('libc.so').base
This means there is now only one way to do Module introspection, and the API
design is such that we encourage you to write performant code. For example, in
the past you might have been tempted to do:
Last but not least, the static enumeration APIs, such as
Module.enumerateExports(), are now also gone. These were however removed from
the TypeScript bindings way back, so most of you shouldn’t need to deal with
these. But if you do, the migration looks exactly the same as above.
Back-to-back releases! Software is hard, and sometimes we need to push quick
fixes to keep things running smoothly. Here’s what’s new in this release:
frida-node Fixed a regression where the Device.openChannel() return type
had changed compared to before.
Fruity backend improvements: Use Apple’s CoreDeviceProxy as fallback, so
we can support systems where NCM is problematic. Also retransmit mDNS-SD
request every 250 ms, for added robustness.
This release brings several improvements and fixes to our Fruity backend,
enhancing compatibility and error handling across platforms. Below are the
changes included in this release:
fruity: Initiate pairing on macOS too, if needed.
fruity: Tweak macOS CreateAssertion error handling. So we provide a clean
error message when it fails.
fruity: Handle OPACK boolean and compact integers. Support for the latter is
needed during pairing on iOS 18.4.1.
fruity: Improve portable tunnel error-handling. When we use lockdown to
determine if the iDevice supports tunnels, and that fails due to lack of
lockdown-level pairing, simply assume that the OS supports it.
fruity: Add timeout to the Linux netif wait logic.
fruity: Handle NetworkManager DISCONNECTED+CARRIER. So we actually wait until
the device is ready when it quickly passes through state=DISCONNECTED with
reason=CARRIER.
Another quick bug-fix release, because software is hard! This release
addresses the following issue:
node: Fix module resolution when not built from source. Turns out the
package.json generated inside our build directory confused the module root
detection in the bindings package. This means that our search path was
actually wrong, and relied on this being misdetected.
We are excited to announce a major update to our Node.js bindings! They have
been rewritten from scratch. Instead of depending on Node.js and V8 APIs that
inevitably change between releases, requiring separate builds per ABI, our
bindings now target Node-API. This means that a single binary can be used across
all modern versions of Node.js, Electron, nw.js, etc. We only need to build one
binary per OS/arch/libc combo. Not only that, but our new bindings are also
auto-generated, ensuring that API changes in frida-core are instantly reflected,
with only customizations needing tweaking if applicable.
This release also contains some other goodies:
DeviceManager: Fixed crash on early close() in situations where
HostSessionServicestart() gets cancelled.
Web Service: Fixed handling of TLS connections, as the remote address
logic did not take them into account.
API: Fixed up FridaBase references in the .gir files.
Bus: Removed the device property, which wasn’t meant to be exposed.
As always, a big thank you to all contributors and users for your support.
This release brings improved support for Google’s latest ART runtime on 32-bit
ARM, better error-handling on Linux, and improved support for big-endian ARM
architectures.
Here are the highlights:
Improved frida-java-bridge to support Google’s latest 32-bit ARM binaries.
Thanks to @Rwkeith.
Propagated ptrace errors on failure in the Linux backend. Thanks to
@DoranekoSystems.
Improved support for big-endian ARM architectures (armbe8, arm64be,
arm64beilp32).
Removed redundant hardware breakpoint code in the Linux backend.
As always, we thank our contributors for their valuable efforts in making
Frida better.
Quick bug-fix release to address an issue in our ELF parser:
elf-module: Fix recursion in check_str_bounds() when falling back to live
memory. The function assumed a file-backed ELF; falling back to live memory
could trigger unbounded recursion. An explicit live-memory check has been
added to return an error instead.
This release brings several important improvements and fixes:
interceptor: Avoid heap allocation during suspend. By storing the suspended
thread IDs into a GumMetalArray instead of a GQueue, we prevent deadlocks
when a suspended thread is holding the dlmalloc lock. Thanks to
@mrmacete for this improvement.
linux: Fix ModuleRegistry initialization when ELF is missing. When
enumerating RTLD notifiers and loaded modules to find a DT_DEBUG entry, we
no longer assume the ELF file is present. This fixes issues when the program
was loaded from a memfd and spawned without a file.
elf-module: Use live memory if unable to map file. For modules backed by a
memfd, we now utilize the in-memory ELF rather than giving up if we cannot
map the file.
linux: Rework glibc pthread internals detection. Instead of parsing machine
code to determine internals, we now start threads to solve the puzzle in a
more robust fashion.
Quick bug-fix release bringing improvements to our Fruity backend, and basic
support for iOS 18.4:
darwin: Update injector dyld init detection for iOS 18.4.
fruity: Update injector dyld init detection for iOS 18.4 (#1154). Thanks to
@pachoo for this contribution.
network-stack: Reduce delay between writes. By flagging as writable as
soon as some space is available, without waiting for the low watermark.
Thanks to @mrmacete for this improvement.
network-stack: Fix TCP write chunk length (#1156). Another fix by
@mrmacete.
network-stack: Always send enqueued data. This change ensures pcb.output()
is called even when no more space is available on the queue, preventing stalls.
Credits to @mrmacete for preventing those pesky stalls.
We’re pleased to announce Frida 16.7.10, bringing several stability
improvements. Special thanks to @mrmacete for identifying the root cause of
all of them, and fixing a deadlock on Apple OSes.
The following changes are included in this release:
network-stack: Improved VirtualStream locking to enhance batching and
avoid unnecessary scheduling on Frida’s thread.
virtual-stream: Allowed update_pending_io() to be called without holding
a lock for convenience when a subclass doesn’t need to update any other state
before calling it. One of our subclasses was assuming this to be the case, as
that was its behavior before the commonalities were factored out into the
VirtualStream base-class. This means that this refactoring made in 16.7.4
introduced a race condition, and this change fixes it.
darwin: Optimized thread enumeration by avoiding flags. This eliminates
heap allocations, reducing the risk of deadlocks in use cases like the
Interceptor, where thread enumeration is used to suspend and resume threads
by ID. (Contributed by @mrmacete.)
Turns out software is hard! On the same day as our previous release, we’ve rolled
out another quick bug-fix release to address some issues that came up. Huge
thanks to @mrmacete for his contribution. Here’s what’s new:
channel: Break read loop on empty buffer. (Thanks @mrmacete!)
device-manager: Fix teardown logic, where we would also stop() the
HostSessionService in cases where it hadn’t been start()ed.
We’re excited to announce Frida 16.7.5, which brings improvements to our
build system and API, as well as critical fixes for Darwin platforms.
Here’s what’s new:
Darwin: Fix double free in find_module_by_address. (Thanks to
@mrmacete.)
Darwin: Update thread list pointer carving to support recent iOS
versions. On these versions, the thread list pointer within
pthread_from_mach_thread_np() is referenced via ADRP + LDR instead
of ADRP + ADD. (Thanks to @mrmacete for the contribution.)
API: Fix VAPI entries for sealed classes.
API: Remove some accidentally exposed types.
API: Seal classes not meant to be subclassed, preventing unintended
subclassing.
Build System: Provide Gio-2.0.gir for convenience, so users won’t
need any GObject Introspection packages installed when building language
bindings and consuming Frida as a subproject.
Build System: Fix frida_girdir for the uninstalled case. It now
correctly points to the directory containing the refined .gir files,
not the raw ones from the Vala compiler.
Well, sometimes software is hard. Here’s a quick update to fix our CI:
ci: Temporarily drop arm64beilp32 from the package-linux job. Since some
components haven’t been ported to this architecture yet, we are suspending its
inclusion in our Linux packages until the porting work is complete.
ci: Bump pypa/gh-action-pypi-publish to latest v1.
I am pleased to announce the release of Frida 16.7.1! In this release, we’ve
been busy improving support across various architectures and fixing some tricky
bugs. A big thank you to @jpstotz and @philippmao for their valuable
contributions!
Key highlights include:
fruity: Fixed Input/Output Error on Windows by skipping devices with an
empty UDID. (Thanks to @jpstotz)
droidy: Added support for more than ~8 ADB-connected devices by increasing
the message size limit. (Thanks to @philippmao)
thumb-relocator: Improved success rate when hooking tiny functions
produced by modern toolchains on Android by utilizing LLD alignment padding
in can_relocate().
thumb-relocator: Restricted padding detection by ensuring the last
instruction is on a four-byte boundary and is a two-byte instruction.
module-registry: Fixed hooking of tiny ELF notifiers by populating the
registry before hooking, allowing CodeAllocator to locate a nearby
ELF-header.
ci: Added arm64be, armbe8, and armhf-musl to the Linux CI.
env: Enabled generation of Thumb code on 32-bit ARM for smaller binaries.
linux: Added pthread probing for musl on 32-bit ARM.
build: Fixed armhf triplet parsing for musl.
devkit: Also defined GUM_STATIC for the Gum devkit so the consumer
doesn’t have to define it.
One challenging aspect when instrumenting software is to deal with the dynamic
nature of things, from threads starting and terminating, to modules being loaded
and unloaded.
For example, if you’re using Stalker to follow threads as they’re executing,
this presents a couple of basic challenges, before even considering the
instrumentation itself.
Which threads?
While you can use Interceptor to place an inline hook somewhere, so when a
thread does something interesting you then use Stalker to follow its execution,
there are times when you would rather call Process.enumerateThreads() and follow
the ones that you deem interesting.
Each thread may have a name you can use, but when it doesn’t, you’re typically
left with fuzzier options. You might look at its CPU registers provided by the
context property, or pass that to Thread.backtrace() to “fingerprint” it, or
perhaps you’d look at which threads spend the most CPU time during a certain
operation.
But what if you could figure out the thread’s entrypoint routine and parameter?
Now you can:
Next there’s the challenge of following threads that haven’t started yet. Up
until now this required hooking OS-specific internals. And that’s quite a lot of
complexity to maintain for cross-platform agents.
I’m excited to announce that we now provide an API for just this:
The onAdded callback gets called with all existing threads right away, so the
initial state vs. updates can be managed easily without worrying about race
conditions. When called with a brand new thread, the call happens synchronously
from that new thread. So that’s the perfect spot to Stalker.follow() it, so you
won’t miss out on any instructions being executed early on.
Conversely, the onRemoved callback tells you when a thread is about to
terminate. The call happens synchronously from that thread, so you still have a
chance to execute some final code in the context of the thread.
And last but not least, the onRenamed callback tells you when a thread’s
name just changed, along with its previous name, if it had one, or null if
not.
All of the callbacks are optional, but at least one must be provided.
Then, if you later want to stop observing, all you need to do is:
observer.detach();
Future modules
Just like threads come and go, so do modules/shared libraries. You might be
applying your instrumentation early, so you don’t miss out on early activity.
But the earlier you apply your instrumentation, the more likely it is that other
parts of the application haven’t been loaded yet.
While unloading may not actually happen, either because the application doesn’t
do it, or because the dynamic loader doesn’t support it, it’s another aspect
that you might have to deal with.
Handling all of this has up until now required hooking OS-specific internals,
with all of the complexity it entails to maintain such code for cross-platform
agents.
I’m so excited to share that we now provide an API for this as well:
Just like with Process.attachThreadObserver(), the onAdded callback gets
called with all existing modules right away, so the initial state vs. updates
can be managed easily without worrying about race conditions. When called with a
brand new module, the call happens synchronously right after that module has
been loaded, but before the application has had a chance to use it. This means
it’s a good time to apply your instrumentation, using e.g. Interceptor.
Conversely, the onRemoved callback tells you when a module is gone.
Both of the callbacks are optional, but at least one must be provided.
Then, just like with the thread observer API, if you later want to stop
observing, all you need to do is:
observer.detach();
Profiling code
One little known feature in Gum, the C library at the heart of Frida, is its
library called gum-prof. It provides some lightweight building blocks for
profiling code. As of this release, we have finally exposed them to JavaScript.
Let’s start with the main component, the Profiler API. It’s a simple worst-case
profiler built on top of Interceptor:
Unlike a conventional profiler, which samples call stacks at a certain
frequency, you decide the exact functions that you’re interested in profiling.
This is where things get interesting.
When any of those functions gets called, the profiler grabs a sample on entry,
and another one upon return. It then subtracts the two to compute how expensive
the call was. If the resulting value is greater than what it’s seen previously
for the specific function, that value becomes its new worst-case.
Whenever a new worst-case has been discovered, it isn’t necessarily enough to
know that most of the time/cycles/etc. was spent by a specific function. That
function may only be slow with certain input arguments, for example.
This is a situation where you can pass in a describe() callback for the
specific function when calling instrument(). Your callback should capture
relevant context from the argument list and/or other state, and return a string
that describes the new worst-case that was just discovered.
When you later decide to call generateReport(), you’ll find your computed
descriptions embedded in each worst-case entry.
Sampler
As you may have noticed in the Profiler example code that we just touched upon,
we now also have the notion of a “sampler”. We actually have six different
implementations. What they all have in common is that they implement one method,
sample(), which returns a bigint representing the latest measurement. What it
denotes depends on the specific sampler, but to the Profiler this doesn’t
matter, as it’s only concerned with the amount of change between two points.
However, these samplers are also intended to be used directly for other
purposes.
These are the brand new samplers:
CycleSampler: measures CPU cycles, e.g. using the RDTSC instruction on x86
BusyCycleSampler: measures CPU cycles only spent by the current thread,
e.g. using QueryThreadCycleTime() on Windows
WallClockSampler: measures passage of time
UserTimeSampler: measures time spent in user-space by a particular thread
MallocCountSampler: counts the number of calls to malloc(), calloc(), and
realloc()
CallCountSampler: counts the number of calls to functions of your choosing
One cool example of how you might use UserTimeSampler is constructing it with
a thread ID, which means it will measure the time spent in user-space by that
particular thread. By constructing one such sampler per thread, and collecting
one sample from each, you can then exercise the application in some particular
way, like making sure it’s fed a particular network packet. Then you’d collect
a second sample from each sampler, subtracting the previous sample to compute
the amount of change/delta. This tells you which thread spent the most time in
user-space, so you know which thread you might then want to Stalker.follow() to
study up close.
EOF
There’s also a slew of other exciting changes, so definitely check out the
changelog below.
Shot-out to @hsorbo for the fun and productive pair-programming on random
parts of the thread and module observer features! 🙌 Kudos to @mrmacete
and @as0ler for helping test and shake out bugs 🥳
Enjoy!
Changelog
Introduce Process.attachThreadObserver() and ThreadRegistry for monitoring
thread creation, termination, and renaming.
Introduce Process.attachModuleObserver() and ModuleRegistry for monitoring
module loading and unloading.
gumjs: Expose Gum’s Profiler and Sampler APIs to JavaScript.
This release brings important bug fixes and optimizes volatile memory writes on
Linux and Android. Big thanks to @DoranekoSystems for his contribution.
fruity: Fix regression in lockdown over CoreDevice introduced in the
previous release, where RSDCheckin now includes an EscrowBag to support
networked lockdown with services such as com.apple.crashreportmover. This
turned out to break support for certain services lacking the privilege to talk
to AppleKeyStoreUserClient. We now maintain a list of such services to omit
the EscrowBag for them. Thanks to @as0ler for reporting and helping
troubleshoot.
darwin: Fix sysroot detection on Apple Silicon so we can resolve modules
correctly inside Simulator processes. Kudos to @stacksmashing for
reporting.
linux: Optimize NativePointer#writeVolatile() (JS) /
gum_memory_write() (C) for Linux/Android (thanks to @DoranekoSystems).
By making use of process_vm_writev() if the kernel supports it, we can avoid
parsing memory maps. This means it is now thousands of times faster.
This release brings a set of improvements and fixes in our Linux and Android
support, with contributions from @kaftejiman and @DoranekoSystems. We’ve
also improved how we talk to Apple devices across the network.
Here’s what’s new:
linux: Improve injector to avoid risky code swaps with memfd regions
(thanks to @kaftejiman). Memfd regions may not be writable, and unlike
regular regions, ptrace() won’t help us in case of a missing writable bit.
linux: Relax injector’s libc matching for Android (thanks to
@kaftejiman). This means we can still match them with bind-mounted APEXes.
linux: Optimize NativePointer#readVolatile() (JS) / gum_memory_read()
(C) for Linux/Android (thanks to @DoranekoSystems). By making use of
process_vm_readv() if the kernel supports it, we can avoid parsing memory
maps. This means instead of being well above 1000x slower compared to direct
access, it is now only about 1.45x slower.
fruity: Support networked lockdown for CoreDevice. We need to provide
the remote unlock host key as part of the RSDCheckin. Kudos to @as0ler
and @mrmacete for reporting and helping get to the bottom of this one.
This release brings important fixes and improvements:
objc: Handle extended block type encoding (thanks to @mrmacete).
module: Reverted the previous optimization of NativeModule lifecycle,
as the underlying performance issue in our GLib patch has been addressed.
darwin: Fixed an issue where Module.load() could fail when provided
with an alias. On macOS >= 13, we now use _dyld_get_dlopen_image_header()
to resolve modules by address.
linux: Revived support for ARM BE8, restoring compatibility with
big-endian ARM systems.
The main change in this release is the revival of our Windows injector, which
was broken by the recent Gum.Module refactoring. Other than that we have also
improved the performance of low-level GLib primitives across platforms,
specifically in our patch that implements clean-up of static allocations. This
is needed due to how a Frida-injected payload may have a shorter lifespan than
the process it’s injected into.
Another round of improvements and fixes to enhance Frida’s stability and
performance, thanks to invaluable feedback from @mrmacete. Here’s what’s new
in this release:
gumjs: Fix crash in Module finalizers by deferring unref using an idle
source. This avoids issues caused by our QuickJS suspend/resume patch not
supporting usage from finalizers, and also avoids the overhead of
suspending/resuming JS execution during high-volume module destruction. A
better long-term solution will involve introducing a ModuleObserver to
manage Module lifecycles and emit signals when modules are added or removed.
module: Speed up NativeModule lifecycle by using a single lock for all
Module objects. This change improves performance and will be revisited once
the GLib static allocation cleanup patch is enhanced to use a more suitable
data structure for mutex tracking.
A fresh release with some important fixes and improvements:
gumjs: Relinquish JS lock while unreffing modules. To avoid deadlocking in
case dispose() releases a cached handle. Such an operation typically requires
acquiring a runtime linker lock. Another thread might already be holding that
lock while waiting for the JS lock. A common scenario for that to happen is that
the agent registers a callback with the runtime linker, called whenever a module
is loaded or unloaded.
agent: Exclude OS/arch symbols in version script. Newer toolchains, such as
the default toolchain on FreeBSD 14.2, don’t like references to symbols that
don’t exist. Instead of listing JNI_OnLoad, which is only defined for Android
builds, we use a separate version script for Android instead.
ci: Move CI to FreeBSD 14.2, up from 14.0 which has gone EOL. Our FreeBSD
CI broke at some point during the last few weeks, and this went unnoticed
until it caused the previous release to not make it out. Oops!
Pleased to announce Frida 16.6.0, featuring significant improvements to module
symbol handling, performance enhancements, and bug fixes.
Here are the highlights:
android: Improve ART compatibility:
Look for symbols when exports are missing, now that Frida supports parsing
.gnu_debugdata.
Handle change of signature of runFlip (thanks to @matbrik).
android: Fix overflow in enumerateLoadedClasses() (thanks to @123edi10).
Create and clean up global references incrementally instead of handling them
all at once at the beginning and the end.
android: Support static methods in registerClass() (thanks to
@5andr0).
java: Fix Java.choose() powered by JVMTI on 32-bit systems.
module: Turn Module APIs into instance methods, so multiple queries can be
performed efficiently. This was previously only modelled as such at the
JavaScript (GumJS) level, where such a JS object would have the module’s path
as a string, passed to each query, such as enumerateExports(). The
underlying C API is now also modelled the same way.
gumjs: Add findSymbolByName() and getSymbolByName() methods.
Provide direct, native lookups for symbols by name instead of enumerating
all symbols and filtering them in JavaScript.
module: Optimize find_symbol_by_name() fallback. When the Module
implementation lacks an optimized symbol lookup method, build a sorted index
and binary-search it.
elf-module: Use MiniDebugInfo if no symbols found. When
enumerate_symbols() encounters an ELF with no symbols in memory,
instantiate an offline ElfModule instance and parse the .gnu_debugdata
section. Decompress the embedded ELF and reuse its symbols as a fallback.
ncm: Improve performance of our userspace USB CDC-NCM driver by capping
the per-transfer datagram limit at 16 (thanks for the pair-programming,
@hsorbo!).
Port to the new Gum.Module API. Transitioned to instance methods to allow
multiple queries to be performed efficiently.
Drop support for running without GObject. The footprint savings were minimal
and didn’t justify the added complexity and reduced code readability.
gumjs: Fix V8 NativeCallback use-after-free (non-Interceptor), where
the CpuContext was too narrowly scoped.
Oops, software is hard! Here’s another quick release to address an issue we
missed earlier today.
We’ve fixed an issue with our Meson build scripts where the modulemap
dependencies were not correctly specified after the latest changes in
frida-core. Specifically, core_public_h is now a custom target index, so we
can’t use it directly anymore. Instead, we now depend on its parent,
core_api.
Special thanks to @hsorbo for co-authoring this fix.
Exciting new release packed with performance enhancements and bug fixes across
various components, especially in our Fruity backend. @hsorbo and I
collaborated to bring you the following improvements:
fruity: Boost NCM performance with multi-transfers, improving data
transfer efficiency.
fruity: Improve userspace NCM driver to perform batching, reducing packet
loss in bursty situations.
fruity: Enable lwIP TCP timestamps and SACK to align with the Linux IP
stack defaults, enhancing network performance.
fruity: Bump lwIP TCP Maximum Segment Size (MSS) to 4036 for better TCP
tunnel performance.
fruity: Account for frida-serverbind() delay to improve connection
establishment reliability.
fruity: Fix crash on USB operation creation during teardown.
fruity: Improve USB device handling on non-macOS systems by avoiding
unnecessary USB access when kernel NCM is available.
fruity: Fix direct channel reliability by ensuring connections are
established correctly even when conflicting services are running. Kudos to
@mrmacete for helping track this one down.
fruity: Improve TcpTunnelConnection teardown to ensure proper cleanup
upon the remote end closing the connection.
api: Generate a proper GObject Introspection Repository (GIR), including
necessary types and omitting internal ones.
api: Avoid exposing internal types in the API.
api: Omit APIs involving HostSession.
build: Modify output logic to avoid redundant writes to output files,
speeding up incremental builds.
build: Avoid parsing API multiple times by leveraging Meson’s
custom_target() support for multiple outputs.
compat: Create relative subproject symlinks so the source tree can be
moved without breaking builds.
compat: Fix error-handling in compat.symlink_to() for subprojects.
windows: Fix cpu_type_from_pid() for non-existent PIDs.
windows: Use GetProcessInformation() on Windows 11+ to ensure correct
usage of ProcessMachineTypeInfo.
As always, a huge thanks to @hsorbo and @mrmacete for their invaluable
contributions in making this release possible.
Exciting new release packed with improvements and new features across platforms.
Here’s what’s new:
Fruity Backend Improvements
@hsorbo and I have been working hard to enhance our Fruity backend, and
we’re excited to share the following improvements:
Added support for the TCP tunnel protocol and made it the default to match
Apple’s new behavior. The FRIDA_FRUITY_TUNNEL_PROTOCOL environment variable
can be used to revert back to QUIC.
Fixed edge-case in tunnel logic for older OS versions, ensuring reliable
operation even when usbmuxd is not available.
Gracefully closed TunnelConnection to improve stability.
Fixed a hang that could occur when a USB operation starts during teardown,
preventing transfers from getting stuck.
Fixed QuicTunnelConnection teardown logic, properly handling errors
during close operations.
Relaxed NCM interface presence check, requiring only one operational
network interface.
Adjusted to always try USB transport first, as network transport may be
slower or unavailable.
Improved handling of timeout cases when skipping jailed fallback.
Now expect networked devices to respond quickly when connecting to the
pairing service, improving the user experience when a device has gone to sleep.
Fixed CoreDevice UDID logic for modern devices.
Android
Gadget now supports loading assets from APKs when extractNativeLibs is set to
false, improving compatibility with modern Android apps (thanks to
@gergesh).
Revived injector’s handling of shared libc ranges, ensuring correct
behavior when the target process’s lowest libc.so range is a shared mapping
(thanks to @lx866).
Linux
Improved injector’s compatibility with MUSL, handling differences in the
loader string (thanks to @luckycat889).
Added support for overriding configuration when building helpers, allowing
for greater flexibility in builds (thanks to @luckycat889).
Allocated stack for injector’s remote calls, improving compatibility with
programs using small stacks, such as Go applications (thanks to
@ajwerner).
Added CI that rebuilds helper binaries to ensure consistency between
source and checked-in binaries (thanks to @ajwerner).
Picked alternative temporary directories when $TMPDIR is noexec
Cross-platform
Added support for non-UTF-8 locales in the build system, ensuring better
compatibility on systems with various locale settings (thanks to
@JunGe-Y).
Added support for the PowerPC architecture in the build system.
Added support for binary data handling in frida-inject and RpcClient
internals.
Quick bug-fix release to further improve our Fruity backend, where @hsorbo
and I filled up our coffee cups and hammered out the following fixes:
fruity: Fix use-after-free in TcpConnection. The error callback might be
called at a point where the PCB has already been freed. This meant that us
clearing its user data would result in a use-after-free where a NULL pointer
was written into the unknown.
fruity: Fix DTXArgumentList.parse() GValue init, where we were using the wrong
setter when encountering an object. This was caught by GLib’s runtime checks,
but went unnoticed because we usually build without them.
payload: Fix an AddressSanitizer build regression.
Turns out a serious stability regression made it into Frida 16.5.3, where
frida-server would crash on incoming connections not originating from a
CoreDevice tunnel. Kudos to @mrmacete for investigating and fixing
this only hours after the problematic releases made it out. 🎉 Enjoy!
Binaries for the previous release did not make it out due to frida-node’s NAN
dependency getting bumped by a script that wasn’t meant to bump it, and the
latest code breaking Electron support. This release rolls it back, and bumps
frida.Compiler’s @types/frida-gum to 18.7.1 while at it.
Excited to bring you another bug-fix release to further improve our Fruity
backend, iOS stability, and a fix for memory scanning with regexes.
The changes mentioned without specific attribution were authored by [@hsorbo][]
and I in a series of fun pair-programming sessions.
Here’s the long and short of it:
memory: Make memory scanning regex patterns raw, so searches are reliable
across binary regions that are not valid UTF-8. Thanks @mrmacete!
web-service: Close connections of removed dynamic interfaces, to avoid them
sticking around until we run out of file-descriptors.
network-stack: Handle abrupt disposal of TcpConnection, where we would free
the TCP PCB but fail to notify any live TcpIOSource instances and blocked
TcpInputStream.read() calls.
network-stack: Fix racy TCP data loss upon peer closure, where the closure
resulted in us letting go of the PCB, and the recv() logic would return early
because the PCB was gone. At that point there might still be data left in the
RX buffer, but the application wouldn’t see it.
network-stack: Fix race in TcpInputStream.read(), where the notify::pending-io
signal fires after the call to is_readable() but before our signal handler is
connected.
fruity: Use USB product string as transport name.
fruity: Fix USB mode parsing on iOS < 16, where the mode is a 3 byte blob.
fruity: Bubble up USB permission errors.
fruity: Bail on iOS tunnel service versions pre-17, instead of crashing.
control-service: Fix reliability on CoreDevice systems, where having a single
transport broker listening on all interfaces may result in an early TCP RST
when trying to communicate with it from inside a tunnel. The exact cause of
this is not known, but we have confirmed that having one broker per dynamic
interface/tunnel does resolve the issue. We also observed that listening on
all interfaces, but restricted to IPv6, also avoids the issue.
meson: Fix i/tvOS compilation with GLib as a subproject.
meson: Disable Fruity and friends on FreeBSD, as we now rely on a libusb API
that only exists in our libusb. If anyone’s interested in these backends on
FreeBSD it shouldn’t be too hard to fix this – PRs are most welcome.
Quick bug-fix release to further improve our Fruity backend, where @hsorbo
and I filled up our coffee cups and hammered out the following fixes and tweaks:
fruity: Reuse NCM peer when tunnel setup fails.
fruity: Handle iDevice not paired with anyone.
fruity: Handle USB TunnelConnection dropping.
fruity: Fix unreliable modeswitch activation.
fruity: Fix teardown when using our NCM driver.
fruity: Fix error marshaling in find_tunnel() for non-macOS.
Some of you may have found yourself in a situation where a piece of data in
memory looks interesting, and you want to locate the code responsible for it.
You may have tried Frida’s MemoryAccessMonitor API, but found the page
granularity hard to work with. That is, you might have to collect many samples
until you get lucky and catch the code that accesses those specific bytes on
the page that they’re on. This might be hard enough on systems with 4K pages,
and even worse on modern Apple systems with 16K pages.
To address this, @hsorbo and I filled up our coffee cups and got to work,
implementing support for hardware breakpoints and watchpoints. The long story
short is that thread objects returned by Process.enumerateThreads() now have
setHardwareBreakpoint(), setHardwareWatchpoint(), and corresponding methods
to unset them at a later point. These are then combined with
Process.setExceptionHandler() where you call the unset method and return true
to signal that the exception was handled, and execution should be resumed.
Demo time
Let’s take these new APIs for a spin. As our target we’ll pick id Software’s
brand new 2024 re-release of DOOM + DOOM II.
The first thing we might want to do is figure out where in memory the number of
bullets is stored. Let’s cook up a tiny agent to help us achieve this:
letmatches=[];functionscan(pattern){constlocations=newSet();for(constrofProcess.enumerateMallocRanges()){for(constmatchofMemory.scanSync(r.base,r.size,pattern)){locations.add(match.address.toString());}}matches=Array.from(locations).map(ptr);console.log('Found',matches.length,'matches');}functionreduce(val){matches=matches.filter(location=>location.readU32()===val);console.log('Filtered down to:');console.log(JSON.stringify(matches));}functionpatternFromU32(val){returnnewMatchPattern(ptr(val).toMatchPattern().substr(0,11));}
We know that we have 50 bullets currently, so let’s find all heap allocations
containing the value 50, encoded as a native uint32:
[Local::doom.exe ]-> scan(patternFromU32(50))
Found 6947 matches
That’s quite a few. Let’s narrow it down by firing one bullet, and checking
which of those locations now contain the value 49:
[Local::doom.exe ]-> reduce(49)
Filtered down to:
["0x1fbf5191884"]
Bingo! Now that we know where in memory the number of bullets is stored, our
next step is to find the code that updates the number of bullets when one is
fired. Let’s add another helper function to our agent:
functioninstallWatchpoint(address,size,conditions){constthread=Process.enumerateThreads()[0];Process.setExceptionHandler(e=>{console.log(`\n=== Handler got ${e.type} exception at ${e.context.pc}`);if(Process.getCurrentThreadId()===thread.id&&['breakpoint','single-step'].includes(e.type)){thread.unsetHardwareWatchpoint(0);console.log('\tDisabled hardware watchpoint');returntrue;}console.log('\tPassing to application');returnfalse;});thread.setHardwareWatchpoint(0,address,size,conditions);console.log('Ready');}
We can see that the program counter that we observed in our exception handler is
on the instruction right after the sub that triggered our watchpoint.
So from here we can set up an inline hook that gets fired whenever a bullet is
fired:
Interceptor.attach(Module.getBaseAddress('doom.exe').add(0x2f1010),function(){constammoLeft=this.context.rax.add(4).readU32();console.log(`Shots fired! Ammo left: ${ammoLeft}`);});
[Local::doom.exe ]-> Shots fired! Ammo left: 42
Shots fired! Ammo left: 41
Shots fired! Ammo left: 40
Shots fired! Ammo left: 39
Shots fired! Ammo left: 38
We can just as easily make ourselves a cheat for infinite ammo:
Interceptor.attach(Module.getBaseAddress('doom.exe').add(0x2f100d),function(){this.context.rbx=ptr(0);console.log(`Shots fired! Pretending no ammo was actually used`);});
[Local::doom.exe ]-> Shots fired! Pretending no ammo was actually used
Shots fired! Pretending no ammo was actually used
Shots fired! Pretending no ammo was actually used
Shots fired! Pretending no ammo was actually used
Shots fired! Pretending no ammo was actually used
Look ma, infinite ammo!
Note that we could also have achieved this by using Memory.patchCode() to
replace the sub with a 3-byte nop, which X86Writer can do for us through
putNopPadding(3). The Interceptor hook has the advantage of automatically
being rolled back when our script is unloaded, and makes it easy to execute
arbitrary code.
Windows on ARM
Another highlight of this release is that we now support Windows on ARM. This
means that an arm64 version of Frida can inject into native arm64 processes, as
well as emulated x86_64 and x86 processes.
We don’t yet provide binaries however, as we’re waiting for GitHub to provide
arm64 runners to OSS projects, which for now is limited to their Team and
Enterprise Cloud customers. While it is technically feasible to cross-compile
from an x86_64 build machine, we decided to punt on this as we quickly ran into
issues with Meson’s MSVC support.
EOF
There’s also a slew of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changelog
thread: Support hardware breakpoints and watchpoints.
fruity: Fix deadlock in perform_on_lwip_thread().
windows: Add support for arm64.
windows: Migrate Exceptor to Microsoft’s VEH API.
linux: Handle process gone when detaching. Thanks @ajwerner!
linux: Fix the clone() wrapper on MIPS.
java: Handle Android GC cycle handlers not being exported. Thanks
@thinhbuzz!
java: Add preliminary support for OpenJDK 17 on Windows. Thanks
@FrankSpierings!
meson: Add frida-netif to the public frida-core, so frida-core devkits include
all needed symbols.
Quick bug-fix release to further improve our Fruity backend, where @hsorbo
and I filled up our coffee cups and hammered out the following fixes:
tunnel-connection: Wire up missing stream close logic.
tunnel-connection: Ensure JSON request ends up in its own UDP packet. When
opening the tunnel, it seems problematic if a datagram and stream data end up
in the same UDP packet. We make our dummy-datagram larger to avoid this.
tunnel-connection: Consistently avoid writes after connection is gone, which
would result in a crash.
network-stack: Handle perform_on_lwip_thread() from the lwIP thread instead of
deadlocking.
This release is packing a whole slew of improvements:
darwin: Handle dyld restart on macOS Sequoia and iOS 18.
darwin: Await ObjC init on macOS Sequoia and iOS 18, by making use of
notifyObjCInit() if available.
fruity: Improve CoreDevice pairing support:
Fix support for multiple pairing relationships.
Keep the in-memory peer store up-to-date, so new pairing relationships
don’t require a process restart to be able to match them up with pairing
services on the network.
ncm: Detach all drivers before changing configuration.
ncm: Avoid using a broken kernel NCM driver.
darwin: Fix sysroot on simulator. Thanks @CodeColorist!
darwin-mapper: Locally resolve shared cache symbols, to avoid resolver
functions when possible, side-stepping our existing issue where the generated
constructor function tries to write the result to a read-only page.
gumjs: Fix race in recv().wait() on application thread. Thanks
@HexKitchen!
python: Eliminate usage of unstable ref-counting APIs, so extensions built
with newer Python headers still work on older Python runtimes.
This release is packing some exciting new things. Let’s dive right in.
CoreDevice
As mentioned in the 16.3.0 release notes, @hsorbo and I were working on
submitting a patch for the Linux kernel’s CDC-NCM driver to make it compatible
with Apple’s private network interface. This has since gone upstream, and
will be part of Linux 6.11.
In the meantime, and for those of you using Frida on Windows, we have just
implemented a minimal user-mode driver that Frida now uses when it detects
that the kernel doesn’t provide one. We leveraged lwIP to also do Ethernet
and IPv6 entirely in user space. The result is that Frida can support CoreDevice
on any platform supported by libusb.
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changelog
fruity: Rework to support userspace CDC-NCM.
fruity: Add support for dyld restart on iOS >= 18.
fruity: Await ObjC runtime initialization on iOS >= 18.
fruity: Fix gadget upload when no usbmux connection is available.
fruity: Improve open_channel() to support tcp:service-name.
The previous release didn’t make it out due to a CI issue. The only change in
this release is the CI fix needed. (One of the FreeBSD runner images had just
been removed by the CI provider, so we had to bump to a newer one.)
It’s time for another bug-fix release. Quite a few goodies in this one:
darwin: Avoid thread_set_state() during injection, so we don’t get killed by
the system on e.g. macOS >= 14.5. Thanks @_saagarjha for contributing the
first draft of the fix!
fruity: Perform RSDCheckin on services that need it. In this way we retain
backwards-compatibility for open_channel() of lockdown services when a
CoreDevice tunnel is available.
fruity: Stop caching the LockdownClient, to avoid issues with multiple
consumers. Reproducible using frida-ps with a jailed iOS device connected.
python: Fix the open_service() plist example.
node: Fix spawn() options logic for undefined values. Kudos to @as0ler for
reporting and helping track this one down!
node: Skip undefined when marshaling aux options to GVariant.
node: Skip undefined when marshaling object to GVariant.
node: Handle errors when marshaling to GVariant.
node: Fix the openService() plist example.
Kudos to @hsorbo for the fun and productive pair-programming on all of the
above! 🙌
Note: This release never made it out due to a CI issue, addressed in 16.3.3.
Just a quick bug-fix release to address a packaging issue with our Node.js
bindings. The uploaded prebuilds weren’t stripped and exported symbols they
weren’t meant to export. Kudos to 0xDC00 for reporting.
This release is packing some exciting new things. Let’s dive right in.
CoreDevice
Starting with iOS 17, Apple moved to a new way of communicating with services
on the iDevice side, including their Developer Disk Image (DDI) services. Their
new way of doing things unifies how Apple software talks to other Apple devices,
and is known as CoreDevice. It seems to have originated back when Apple
introduced their T2 coprocessor. Cisco’s DUO team published some excellent
research on this back in 2019.
Like with the T2, the new stack used for iOS also uses RemoteXPC for talking to
services. Things are a bit more complex though, because unlike the T2, mobile
devices don’t have a persistent connection to macOS, and also have the notion of
pairing. Luckily for us, @doronz88 had already done an amazing job reversing
and documenting most of what we needed to implement the new protocols, so
that saved us a lot of time.
Even so, it was a massive undertaking, but tons of fun – @hsorbo and I had
a blast pair-programming on it. Quite a few moving parts are involved, so let’s
take a quick walk through them.
With an iDevice plugged in, it exposes a USB CDC-NCM network interface, known as
the “private” interface. It also exposes an interface used for tethering, just
like it did in the past – except back then it was using a proprietary Apple
protocol instead of CDC-NCM.
This is where we hit the first challenges trying to talk to it from a Linux
host. First off, the iOS device needs a USB vendor request to mode-switch it
into exposing the new interfaces. This part is easy, as the usbmuxd daemon can
do this for us if we set the environment variable USBMUXD_DEFAULT_DEVICE_MODE
to 3. So far so good.
The next challenge was that the Linux kernel’s CDC-NCM driver failed to bind to
the device. After a bit of debugging we discovered that it was due to the
private network interface lacking a status endpoint. The status endpoint is how
the driver gets notified about whether a network cable is plugged in. Apple’s
tethering network interface has such an endpoint, and it makes sense there – if
tethering is disabled it’s just as if the cable is unplugged. But the private
interface is always there, so understandably Apple chose not to include a status
endpoint for it.
We quickly developed a kernel driver patch to lift the requirement for a
status endpoint, and this got it working. Later we realized that we should still
require a status endpoint for the tethering interface, so we ended up refining
our patch a bit further. The plan is to submit that in the next few days.
Anyway, with the network interface up, the host side uses mDNS to locate the
IPv6 address where a RemoteServiceDiscovery (RSD) service is listening. The host
connects to it and speaks HTTP/2 with RemoteXPC messages going back and forth.
This particular service, RSD, tells the host which services are available on
the private interface, the port numbers they’re listening on, and details like
the protocol each uses to communicate.
Then, knowing which services are listening on which ports, the host looks up the
Tunnel service. This service lets the host establish a tunnel to the device,
acting as a VPN to allow it to communicate with the services inside that tunnel.
Since setting up such a tunnel requires a pairing relationship between the host
and the device, it means that the services inside the tunnel allow the host to
do a lot more things than the services outside the tunnel.
The base protocol is the same as with RSD, and after some back and forth
involving a pairing parameters binary blob and some cryptography, a pairing
relationship is either created or verified. At this point the two endpoints are
using encrypted communications, and the host asks the Tunnel service to set up a
tunnel listener.
Now, assuming the host asked for the default transport, QUIC, the host goes
ahead and connects to it. We should note that the the Tunnel service also
supports plain TCP. Presumably that is there for older macOS versions that
don’t come with a QUIC stack. Another thing worth mentioning is that the Tunnel
service provides the host with a keypair, so it uses that as part of the
connection setup.
Once connected, the device sends the host some data across a reliable stream.
The data starts with an 8 byte magic, “CDTunnel”, followed by a big-endian
uint16 that specifies the size of the payload following it. The payload is JSON,
and tells the host which IPv6 address the host’s endpoint inside the tunnel has,
along with the netmask and MTU. It also tells the host its own IPv6 address
inside the tunnel, and the port that the RSD service is listening on.
The host then sets up a TUN device configured as it was just told, and starts
feeding it unreliable datagrams as they’re received from the QUIC connection.
And for data in the other direction, whenever there’s a new packet from the
TUN device, the host feeds that into the QUIC connection.
So at this point the host connects to the RSD endpoint inside the tunnel, and
from there it can access all of the services that the device has to offer. The
beauty of this new approach is that clients communicating with device-side
services don’t have to worry about crypto, nor provide proof of a pairing
relationship. They can simply make plaintext TCP connections on the tunnel
interface, and QUIC handles the rest transparently.
What’s even cooler is that the host can establish tunnels across both USB and
WiFi, and because of QUIC’s native support for multipath, the device can
seamlessly move between wired and wireless without disrupting connections to
services inside the tunnel.
So, once we got all of this implemented we were feeling excited and optimistic.
Only part left was to do the platform integrations. And uhh yeah, that’s where
things got a lot harder. The part that got us stuck for a while was on macOS,
where we realized we had to piggyback on Apple’s existing tunnel. We discovered
that the Tunnel service would refuse to talk to us when there’s already a tunnel
open, so we couldn’t simply open up a tunnel next to Apple’s.
While we could ask the user to send SIGSTOP to remoted, allowing us to set up
our own tunnel, it wouldn’t be a great user experience. Especially since any
Apple software wanting to talk to the device then wouldn’t be able to, making
Xcode, Console, etc. a lot less useful.
It didn’t take us long to find private APIs that would allow us to determine
the device-side address inside Apple’s tunnel, and also create a so-called
“assertion” so that the tunnel is kept open for as long as we need it. But the
part we couldn’t figure out was how to discover the device-side RSD port inside
the tunnel.
We knew that remotepairingd, running as the local user, knows the RSD port,
but we couldn’t find a way to get it to tell us what it is. After lots of
brainstorming we could only think of impractical solutions:
Port-scan the device-side address: Potentially slow, and faster
implementations would require root for raw socket access.
Scan remotepairingd’s address space for the device-side tunnel address, and
locate the port stored near it: Wouldn’t work with SIP enabled.
Rely on a device-side frida-server to figure things out for us: This wouldn’t
work on jailed iOS, and would be complex and potentially fragile.
Grab it from the syslog: Could take a while or require a manual user
action, and forcing a reconnection by killing a system daemon would result in
disruption.
Give up on using the tunnel, and move to a higher level abstraction, e.g. use
MobileDevice.framework whenever we need to open a service: Would require us to
possess entitlements. Exactly which depend on the particular service. So for
example if we’d want to talk to com.apple.coredevice.appservice, we’d need
the com.apple.private.CoreDevice.canInstallCustomerContent entitlement. But,
trying to give ourselves a com.apple.private.* entitlement just wouldn’t fly,
as the system would kill us as only Apple-signed programs can use such
entitlements.
This was where we decided to take a break and focus on other things for a while,
until we finally found a way: The remoted process has a connection to the RSD
service inside the tunnel. We finally arrived at a simple solution, using the
same API that Apple’s netstat is using:
The Linux side of the story was a lot easier though, as there we are in control
and can set up a tunnel ourselves. There was one challenge however: We didn’t
want to require elevated privileges to be able to create a tun device. The
solution we came up with was to use lwIP to do IPv6 in user-mode. As we had
already designed our other building blocks to work with GLib.IOStream, decoupled
from sockets and networking, all we had to do was implement an IOStream that
uses lwIP to do the heavy lifting. Datagrams from the QUIC connection get fed
into an lwIP network interface, and packets emitted by that network interface
are fed into the QUIC connection as datagrams.
Next up was the Windows side of things. We did some digging and quickly realized
that Apple’s software doesn’t currently set up a tunnel. The official driver
also appears to keep the USB device busy, meaning we can’t easily trigger a
mode-switch and do things ourselves. There’s probably an elegant solution to the
Windows part of the puzzle, but we realized we were already so deep inside the
rabbit-hole that it would be wise to leave this for later. So if anyone reading
this is interested in helping out, please do get in touch.
Another area that needs future improvement is that we only support cabled
connectivity on macOS. This should be easy to improve on once we have updated
frida-server and frida-gadget so they listen on tunnel interfaces whenever they
appear.
Jailed iOS 17
With the new CoreDevice infrastructure in place, we have also restored support
for jailed instrumentation on iOS 17. This means we can once again spawn
(debuggable) apps on latest iOS, which is 17.5.1 at the time of writing. We
still have the issue where attach() without spawn() doesn’t work, as our jailed
injector doesn’t yet support the restartable dyld case when attaching to an
already running app. This will be addressed in a future release.
Device.open_service() and the Service API
Given that Frida needs to speak quite a few protocols to interact with Apple’s
device-side services, and applications also sometimes need other such services,
this presents a challenge. Applications could speak these protocols themselves,
e.g. after using the Device.open_channel() API to open an IOStream to a specific
service. But this means they have to duplicate the effort of implementing and
maintaining the protocol stacks, and for protocols such as DTX they may be
wasting time establishing a connection that Frida already established for its
own needs.
One possible solution would be to make these service clients public API and
expose them in our language bindings. We would also have to implement clients
for all of the Apple services that applications might want to talk to. That’s
quite a few, and would result in the Frida API becoming massive. It would also
make Frida a kitchen sink of sorts, and that’s clearly not a direction we want
to be heading in.
After thinking about this for a while, it occurred to me that we could provide
a generic abstraction that lets the application talk to any service that they
want. So last week @hsorbo and I filled up our coffee cups and got started
on just that.
Here’s how easy it is to talk to a RemoteXPC service from Python:
So now that we’ve looked at the new open_service() API being used from Python
and Node.js, we should probably mention that it is (almost) just as easy to use
this API from C:
The string passed into open_service() is the address where the service can be
reached, which starts with a protocol identifier followed by colon and the
service name. This returns an implementation of the Service interface, which
looks like this:
Here, request() is what you call with a Variant, which can be “anything”,
a dictionary, array, string, etc. It is up to the specific protocol what is
expected. Our language bindings take care of turning a native value, for example
a dict in case of Python, into a Variant. Once request() returns, it gives you
a Variant with the response. This is then turned into a native value, e.g. a
Python dict.
For protocols that support notifications, the message signal is emitted
whenever a notification is received. Since Frida’s APIs also offer synchronous
versions of all methods, allowing them to be called from an arbitrary thread,
this presents a challenge: If a message is emitted as soon as you open a
specific service, you might be too late in registering the handler. This is
where activate() comes into play. The service object starts out in the
inactive state, allowing signal handlers to be registered. Then, once you’re
ready for events, you can either call activate(), or make a request(), which
moves the service object into active state.
Then, later, to shut things down, cancel() may be called. The close signal
is useful to know when a Service is no longer available, e.g. because the
device was unplugged or you sent it an invalid message causing it to close the
connection.
It’s also easy to talk to DTX services, which is RemoteXPC’s predecessor, still
used by many DDI services.
As you might have already guessed, this example puts the connected iDevice to
sleep.
RPC Binary Passing
Those of you using Gum’s JavaScript bindings might be familiar with our RPC API,
which makes it easy for an application to call functions on its agent.
One long-standing limitation with this feature was that you couldn’t pass binary
data into an exported function – you would have to serialize it somehow. This
is now finally supported.
Note that only one binary parameter can be passed, and it needs to be the last
parameter.
Another improvement in the same area is that you can now return binary data
alongside a JSON-serializable JavaScript value. We previously only supported
returning one or the other. This is now also finally supported.
ci: Fix the frida-node prebuild loop for macOS, so we generate prebuilds for
all targets, not just the first one.
node: Avoid relying on package-lock.json, to support fallback build when
prebuild is missing.
android: Set DexFile to read-only in Java.registerClass(). As of Android 14,
apps with targetSdk >= 34 are not allowed to have writable permissions on
dynamically loaded Dex files. Thanks @pandasauce!
Just a quick bug-fix release to fix a regression in the DebugSymbol API on
Windows, where we failed to bundle the DbgHelp and SymSrv libraries. Kudos to
0xDC00 for reporting this so quickly.
It’s release o’clock, and this one comes jam-packed with improvements! 🎉
Build System
After years of being dissatisfied with our build system situation, I have
finally worked up the courage to restructure it — in a big way.
User Experience
One of the things that bothered me was that our build system felt very eccentric
and complex. You would invoke make and see a menu of things you could build.
But that menu would be different depending on the OS you’re running this on.
Changing build options meant either editing config.mk or overriding them on the
command-line. And if you were on Windows you’d have to use Visual Studio (MSVS).
The MSVS build system is now gone, and you can build Frida the same way you’d
build many other OSS projects:
$ ./configure
$ make
The configure step can be skipped if you don’t need to pass any options, such
as –prefix. This script is really just a thin wrapper around Meson’s setup
command, and you can pass options straight to Meson by adding -- followed by
the options. You can also run make install to install things, which supports
the DESTDIR environment variable to change where the output goes.
Cross-compilation is easy too; for example if you want to build for iOS/arm64,
invoke configure with –host=ios-arm64. If you have a toolchain for an embedded
system, pass –host=$triplet, which will look for $triplet-gcc, $triplet-g++,
etc. on your PATH. You can also add CFLAGS, LDFLAGS, etc. to the environment to
pass in extra flags, just like you’d expect from other build systems.
What’s cool is that our different repos can now be built standalone. You can
clone the frida-gum repo and build it, just like you can do with frida-python,
frida-tools, etc. The frida repo is no longer as important, it’s only kept
around to be able to version a collection of repos, and host the CI used for
rolling new releases.
Each repo contains any needed subprojects/*.wrap files that tell Meson where it
can find the dependencies. This means if you grab frida-core and try to build it
without already having frida-gum on your PKG_CONFIG_PATH, it will grab and build
that for you automatically. What’s also neat is that our Python and Node.js
bindings now make use of this to build from source if a .whl or prebuild can’t
be found or downloaded.
So now that our different components work well as subprojects, this also means
anyone can integrate Frida components into their own projects just as easily.
All you need to do is add a .wrap-file to subprojects/ in your project’s top
source dir, and call dependency() from your meson.build. Meson then looks on
your system first, and if it fails to find the dependency it will clone the git
repo in subprojects/ and build it as part of your project. It is also possible
to tell Meson to force such a fallback without looking on your system.
Here’s what such a .wrap-file could look like for Gum:
Our thin Meson wrapper is also easy to get started with, and you can read more
about it here.
A bit of history
The reason I chose to maintain a separate build system for Windows was that I
previously worked with quite a few experienced Windows developers, and noticed
they’d be a lot more excited about an OSS project if they could work on it using
their favorite IDE. It was important to them that they could look at a crash in
the debugger, jump to a frame belonging to an OSS library, and be able to add
some temporary logging code. And then hit the “Run” hotkey to have the IDE
incrementally compile and relink everything, for a short and sweet feedback
loop.
At the time, Frida’s non-Windows build system was autotools. We later moved to
Meson. Although Meson has a backend for MSVS, meaning we could have it generate
MSVS project files for us, there was one issue blocking us from doing that.
Unlike MSVS, where you can mix projects targeting different machines in the same
“solution” (workspace), Meson only supports compiling for one machine at a time,
in addition to the build machine. Due to how Frida supports injecting code into
e.g. both 32- and 64-bit targets on Windows, we would introduce a usability
regression if we were to remove our MSVS build system. So because of this I
hesitated to drop the MSVS build system.
We also had the same challenge on non-Windows. I ended up solving it by writing
a Makefile that invokes Meson for each architecture, to glue it all together.
While this did work, I never got it to the point where incremental builds would
also work reliably. However, late March this year I finally settled on a way to
solve this locally in frida-core – the only component where we need this kind
of multi-arch madness. By recursively invoking Meson from a custom_target() we
can build the needed components for the other architectures.
This took a lot of work to get working right, but once there it made things so
much more pleasant to work with in the rest of the stack. The frida repo’s
Makefiles and shell-scripts could be dropped and replaced with Meson. The CI
became simpler and more uniform. Anyone can just clone the frida-core repo and
run make, and the resulting binaries would support cross-arch. (Unless
explicitly disabled through –disable-compat / -Dfrida-core:compat=disabled.)
Now you might be wondering why we’re still running make, if we’re now only
using Meson. I ended up writing a thin wrapper around Meson that automates the
downloading of prebuilt dependencies, choosing sensible linker flags for smaller
binaries, etc. The new configure and Makefile files in each repo take care
of invoking releng/meson_configure.py and releng/meson_make.py, which constitute
the thin wrapper around Meson. The releng directory is a submodule, shared by
Frida’s repos. The other thing done before invoking the wrapper, is to also make
sure the releng submodule has been initialized and updated.
Maintenance
Before this release we were maintaining seven different build systems:
Meson (main components, on non-Windows)
Visual Studio (main components, on Windows)
GNU Make (main components meta build system, on non-Windows)
setuptools (Python bindings)
GYP (Node.js bindings)
Xcode (Swift bindings)
QMake (QML bindings)
As of this release, I am excited to announce that we are down to just one build
system: Meson.
The main pain point with the previous situation was having to deal with both 1)
and 2), since they were involved in all of the main components. This meant that
something as simple as adding a source file would require knowledge of two
different build systems. Not only that, but contributors on Linux for example,
would typically have a hard time testing their Visual Studio build system
changes.
Another aspect was that developers would be less inclined to refactor their code
if something as simple as adding a new file involves dealing with two build
systems. The long-term consequence of this was that it fostered bad habits.
“Hmm, I should split this out into a separate file, but uhh… no, that’s too
painful, I’m gonna add that code here for now.”
As for the remaining build systems, only used in bindings, it may not seem that
bad to maintain those – they’re typically familiar to the folks touching that
code anyway. The challenge there was the lack of pkg-config integration in all
but one of them (QMake). This meant that include paths, library paths, and
libraries to link with would end up being duplicated in multiple places. This is
particularly gnarly when linking with a static library that uses other libraries
internally, which is how our language bindings typically consume frida-core.
New Features
Quite a few new things to be excited about in this release:
gumjs: Add Process.runOnThread(), to make it easy to run arbitrary code on a
specific thread. Must be used with care to avoid deadlocks/reentrancy issues.
gumjs: Add limit option to Thread.backtrace(). Thanks @davinci-tech!
gumjs: Expand CModule glib.h with alternatives to deprecated APIs.
memory: Fix patch_code() protection flipping on RWX systems.
swift-api-resolver: Fix handling of indirect type entries.
swift: Work around Module.load() issue on iOS Simulator. Thanks @zydeco!
base: Fix racy crash in custom GSource implementations.
base: Fix the p2p AgentSession registration logic.
buffer: Fix the read_string() size logic. Thanks @hsorbo!
linux: Fix early instrumentation on certain 32-bit systems.
linux: Fix inject_library_blob() on modern Android.
linux: Fix unreliable exec transition logic.
linux: Fix unreliable injection when libc is absent.
agent: Fix hang in child-gating fork() scenarios. Reproducible in situations
where pidfd_getfd() is available but not permitted, such as inside Docker
containers.
windows: Use RW/RX permissions for injection. This makes Frida injection
compatible with more software. In particular, Mozilla Firefox rejects thread
startup if the start address is RWX. Thanks @yjugl!
darwin: Massage libunwind around Frida hooks, to avoid breaking code making
use of exceptions, such as through @try/@catch in Objective-C. Thanks
@mrmacete!
darwin: Take Interceptor and Cloak locks in ThreadSuspendMonitor, to extend
its scope to prevent deadlock scenarios where threads holding the Cloak or
Interceptor lock get suspended. Thanks @mrmacete!
darwin: Fix racy teardown of InjectInstance dispatch source.
darwin: Fix racy teardown of SpawnInstance dispatch source.
Just a quick bug-fix release to deal with an iOS packaging bug affecting users
on palera1n (rootless) and Dopamine. Kudos to @miticollo for reporting this
so quickly.
This release also contains the latest QuickJS, released last month. This means
there’s almost complete ES2023 support, and even some features from the upcoming
ES2024 specification. Plus, quite a few bug-fixes as well. It’s also worth
mentioning that top-level await is now supported, making it easier to write
portable scripts that work on both of our JavaScript runtimes.
Cloaking
Frida keeps track of its own memory ranges, threads, etc., to keep you from
seeing yourself during process introspection. Introspection APIs such as
Process.enumerateThreads() ensure that Frida’s own resources are hidden, and
things appear as if you were not inside the process being instrumented.
For those of you using Stalker, or other things that expose you to raw memory
locations, you might see code not belonging to any loaded module, and wonder
where it came from. For example, if you use Stalker.follow() to follow execution
into or out of a hooked function, it’s going to execute some trampoline code
generated by Interceptor.
Agents using Gum’s C APIs could already query whether a given memory address,
thread, etc., is owned by Frida, but this hadn’t yet been exposed to our
JavaScript bindings. But now, thanks to another awesome contribution by
@mrmacete, this is now supported. For example:
One little known and fairly recent feature, now also available from JavaScript,
is Interceptor.replaceFast(). What’s different about it is that the target is
modified to vector directly to your replacement, which means there is less
overhead compared to Interceptor.replace(). This also means that you need to
use the returned pointer if you want to call the original implementation. It is
also not possible to combine it with Interceptor.attach() for the same target.
However, if you’re dealing with a hot target it’s definitely something you want
to have in your toolbox, especially when combined with CModule.
ELF Exports Regression
We discovered way late that Frida 16.1.0 broke Module#enumerateExports() on some
ELF binaries, and this is now finally fixed. It turned out to be a bug in the
bounds-checking that I added when making Gum.ElfModule a cross-platform API,
when it got support for offline use-cases like that of our Barebone backend.
(Where we use it to dynamically inject Rust code into OS kernels and bare-metal
targets.)
ELF Import Slots
Those of you using Frida on Apple platforms may have noticed that
Module#enumerateImports() provides you with import objects that always have a
slot property. One way you can use this is to write a new pointer to that
address, letting you rebind imports on a per-module basis. Super-handy if
Interceptor is unable to hook a function, or for scenarios where you want to
avoid inline hooks.
As of this release, we now provide the slot property on ELF-based platforms
too, so you can also use this feature on Linux, Android, FreeBSD, and QNX. Yay!
Android Stability
Avid users on recent versions of Android may have experienced “soft-loops”,
where Frida randomly crashes Zygote and causes a big chunk of user-space to
restart. This turned out to be caused by the runtime preparing itself to
fork() by polling /proc/self/stat while waiting for the thread count to drop
to one, i.e. waiting for the process to become single-threaded.
This has now been solved by subtracting the threads owned by Frida, which we
determine by internally using the Cloak API, touched upon earlier in this post.
We also make use of the new ELF Import Slots feature, so we can hook read() only
for callers in libart.so. Inserting an inline hook in libc.so’s read() is
not a great idea in this case, as the process we’re in might use it for a
blocking read that blocks indefinitely. This becomes a challenge when wanting to
unload, and getting stuck waiting for the chance to roll back our inline hook.
Anyway, quite an interesting bug. Shout-out to @enovella_ for reporting and
helping track this one down 🙌
While on the topic of Android, this release also improves Java hooking on
Android 14, where a new ART quick entrypoint is being used in case of
–enable-optimizations. Kudos to @cr4zyserb for this neat contribution.
Better iOS 16 support
If you ever got hit by Service cannot load in requested session when trying
to install Frida on iOS, this is now finally fixed. Kudos to @as0ler for the
assist on fixing this.
Jailbroken tvOS
Another exciting development is that we now support jailbroken tvOS, and you
can grab a .deb straight from our repo at https://build.frida.re/. Special
thanks to @tmm1 for the pull-requests that made this happen.
Misc
This release also has a lot more to offer. The remaining changes are:
symbolutil-libdwarf: Fix handling of DW_AT_ranges in DWARF 5. This means the
DebugSymbol API works properly on binaries built by newer toolchains.
elf-module: Fix relocation address when online.
interceptor: Check module prefix when claiming grafts on arm64, for
compatibility with Xcode’s new libLogRedirect.dylib interposing on iOS 17.
Thanks @mrmacete!
interceptor: Cloak thunks on arm64. Thanks @mrmacete!
windows: Ensure that the MSVC source-charset is set to UTF-8, so embedded
JavaScript can be parsed correctly at runtime. Thanks @Qfrost911!
freebsd: Improve allocate-near strategy.
gumjs: Plug leak during QJS load() w/ ESM.
objc: Ensure block structure is writable in implementation setter. Thanks
@mrmacete!
stalker: Improve stability on multiple fronts. Kudos to @as0ler,
@hsorbo, and @mrmacete for the fun and productive mob programming
sessions that resulted in these wonderful improvements:
stalker: Copy BLR for excluded calls on arm64, instead of replacing them with
functionally-equivalent ones, so that any pointer authentication context is
used as expected. Thanks @mrmacete!
stalker: Abort when allocate_near() fails on arm64, instead of crashing due
to the subsequent NULL pointer dereference.
gumjs: Fix crash in Stalker.flush() on a stopped sink. This happens if
Stalker.garbageCollect() was just called.
gumjs: Fix use-after-free in Stalker QuickJS callback logic. We need to keep
the callback values alive in case Stalker.garbageCollect() happens in the
middle and releases them.
interceptor: Pause cloaked threads too. This prevents random SIGBUS crashes on
our own threads while using Interceptor to hook functions residing on the same
page as any of the ones potentially used internally. Thanks @mrmacete!
darwin: Move to our POSIX Exceptor backend. Mach exception handling APIs have
become increasingly restrictive in recent Apple OS versions.
darwin: Resolve import trampolines on arm64, allowing us to hook targets such
as sigaction().
linux: Improve spawn() to handle r_brk being hit again.
linker: Improve spawn() to consider on-disk ELF for RTLD symbols. This means
we might find r_debug on additional Android systems, for example.
linux: Fix spawn() when DT_INIT_ARRAY contains sentinel values.
linux: Improve spawn() to use DT_PREINIT_ARRAY if present.
process: Add get_main_module(), exposed to JavaScript as
Process.mainModule. Useful when needing to know which module represents the
main executable of the process. In the past this was typically accomplished
by enumerating the loaded modules and assuming that the first one in the list
is the one. This is no longer the case on the latest Apple OSes, so we now
provide an efficient and portable solution with this new API. Thanks
@mrmacete!
compiler: Bump @types/frida-gum to 18.5.0, now with typings for recent API
additions.
barebone: Fix compatibility with latest Corellium.
Just a quick bug-fix release to roll back two of the Interceptor/Relocator arm64
changes that went into the previous release. Turns out that these need some more
refinement before they can land, so we will roll them back for now.
Changelog
Revert “relocator: Improve scratch register strategy on arm64”.
Revert “interceptor: Relocate tiny targets on arm64”.
stalker: Allow transformer to skip calls on arm64.
Our Module API now also provides enumerateSections() and
enumerateDependencies(). And for when you want to scan loaded modules for
specific section names, our existing module ApiResolver now lets you do
this with ease:
server: Use sysroot for temporary files on rootless iOS. Thanks
@fabianfreyer!
gumjs: Fix crash in File and Database when Interceptor is absent. Thanks
@mrmacete!
gumjs: Fix NativePointer from number for 32-bit BE (#752). Thanks @forky2!
gumjs: Bump frida-swift-bridge to 2.0.7.
ci: Publish prebuilds for Node.js 20 & 21, and Electron 27.
ci: Do not publish Swift bindings for now. There’s a long-standing heisenbug
that causes the x86_64 slice to randomly end up corrupted, in turn resulting
in CI release jobs failing. As I’m not too keen on sinking time into this
anytime soon, considering how easy it is to build these bindings locally using
a downloaded core devkit, simply dropping the release asset seems like the
best solution.
ios: Add support for rootless systems. Thanks for the pair-programming,
@hsorbo!
android: Fix dynamic linker compatibility regression. Thanks for the
pair-programming, @hsorbo! Kudo to @getorix for reporting.
gumjs: Add Worker API, so heavy processing can be moved to a background
thread, allowing hooks to be handled in a timely manner. Only implemented in
the QuickJS runtime for now. Kudos to @mrmacete for tracking down and
fixing last-minute bugs in the implementation.
linux: Improve error-handling when trying to attach to processes that are
near death.
Time for a new release, just in time for the weekend:
server: Add missing entitlement for iOS >= 17. Kudos to @alexhude for
helping get to the bottom of this one.
stalker: Improve exclusive store handling on arm and arm64. Instead of
potentially expanding the current block to include instructions beyond where
the block would naturally end, we move to a safer approach: Once we encounter
an exclusive store, we look back at the previously generated blocks to see if
we can find one with an exclusive load. If we do, we mark this range of blocks
as using exclusive access. We also invalidate the blocks, so that problematic
instrumentation can be omitted upon recompilation. To also allow custom
transformers to adapt their generated code, we introduce
StalkerIterator.get_memory_access(). Thanks for the fun and productive
pair-programming, @hsorbo!
gumjs: Add StalkerIterator.memoryAccess, allowing a custom transformer to
determine what kind of instrumentation is safe to add without disturbing an
exclusive store operation. Set to either ‘open’, when “noisy” instrumentation
such as callouts are safe, or ‘exclusive’, when such instrumentation is risky
and may lead to infinite loops. (Due to an exclusive store failing, and every
subsequent retry also failing.)
gumjs: Fix CModule bindings for Stalker on arm.
stalker: Fix crash on invalidation in added slabs.
arm64-writer: Add put_eor_reg_reg_reg(). Thanks for the fun and productive
pair-programming, @hsorbo!
darwin: Fix Stalker.follow() regression where ongoing system calls would get
brutally interrupted, typically resulting in the target crashing. Thanks for
the pair-programming, @hsorbo!
compiler: Bump frida-compile to 16.3.0, now with TypeScript 5.1.5 and other
improvements. Among them is a fix by @hsorbo that changes the default
moduleResolution to Node16.
stalker: Add Iterator.get_capstone(), so transformers can use Capstone APIs
that require the Capstone handle.
For quite some years I’ve been dreaming of taking Frida beyond user-space
software, to also support instrumenting OS kernels as well as barebone systems.
Perhaps even microcontrollers…
Microcontrollers
Earlier this year my family’s cat door broke down. After some back and forth
with the retailer, double-checking the installation and such, it would work
for a little while before it eventually started malfunctioning.
This was obviously not much fun for our cats:
It’s also no surprise that they’d end up making a lot of noise, in turn making
it hard to get a good night’s sleep when having to get up to let them back in
manually.
I ended up buying a second cat door and, lo and behold, no more issues. The old
one ended up collecting dust for a while. Something I kept thinking of was
whether I could debug it, and perhaps even extend the software to do more useful
things.
Feeling the urge to open it up to poke at the electronics inside of it, I
eventually gave in:
That looked like an STM32F030C6T6, which is an ARM Cortex M0-based MCU. My first
thought was whether I could dump the flash memory to do some static analysis.
After quickly skimming MCU docs, and a little bit of multimeter probing, I
figured out the JP12 pads:
PAD 1/2
PAD 7/8
BOOT0
USART1 RX
SWDIO
GND
VDD
USART1 TX
SWCLK
This made it easy to pull BOOT0 high, so the MCU boots into its internal
bootloader instead of user code.
By hooking up a USB to 3.3V TTL device to the USART1 pads, I could dump the
flash:
$ ./stm32flash -r firmware.bin /dev/ttyUSB0
stm32flash 0.7
http://stm32flash.sourceforge.net/
Interface serial_posix: 57600 8E1
Version : 0x31
Option 1 : 0x00
Option 2 : 0x00
Device ID : 0x0444 (STM32F03xx4/6)
- RAM : Up to 4KiB (2048b reserved by bootloader)
- Flash : Up to 32KiB (size first sector: 4x1024)
- Option bytes : 16b
- System memory : 3KiB
Memory read
Read address 0x08008000 (100.00%) Done.
And perform some static analysis:
Seeing as two of the other pads are connected to SWDIO and SWCLK, used for
Serial Wire Debug (SWD), the natural next step was to hook up a Raspberry Pi
Debug Probe to those. After getting that set up, I fired up OpenOCD:
$ openocd -f interface/cmsis-dap.cfg -f target/stm32f0x.cfg
Open On-Chip Debugger 0.11.0-g8e3c38f7-dirty (2023-05-05-14:25)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : auto-selecting first available session transport "swd". To override use 'transport select <transport>'.
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
Info : Using CMSIS-DAPv2 interface with VID:PID=0x2e8a:0x000c, serial=E6614103E78B482F
Info : CMSIS-DAP: SWD Supported
Info : CMSIS-DAP: FW Version = 2.0.0
Info : CMSIS-DAP: Interface Initialised (SWD)
Info : SWCLK/TCK = 0 SWDIO/TMS = 0 TDI = 0 TDO = 0 nTRST = 0 nRESET = 0
Info : CMSIS-DAP: Interface ready
Info : clock speed 1000 kHz
Info : SWD DPIDR 0x0bb11477
Info : stm32f0x.cpu: hardware has 4 breakpoints, 2 watchpoints
Info : starting gdb server for stm32f0x.cpu on 3333
Info : Listening on port 3333 for gdb connections
The idea I had been thinking about for a long time was to add a new Frida
backend where the only process you can attach to is PID 0. Any scripts loaded
there would actually be run locally, and implement the familiar
JavaScript API. Any API that accesses memory, such as when dereferencing an
int * by doing e.g. ptr(‘0x80000’).readInt(), would end up querying the
target, through SWD in the above case.
I initially started sketching this where the backend would talk to the OpenOCD
daemon through its telnet interface. But I quickly realized that it would be
better to talk to its GDB-compatible remote stub. In this way, Frida will be
able to instrument any target with an available remote stub. Whether that’s
OpenOCD, Corellium (iOS kernel instrumentation!), QEMU, etc.
As for Interceptor, my thinking was that basic functionality would be
implemented using breakpoints. But, only if the user supplies JavaScript
callbacks. If function pointers are supplied instead, we could perform inline
hooking so the target can run without any traps/ping-pongs with the host. This
means it could even be used for observing and modifying hot code inside an OS
kernel or MCU firmware.
After some initial sketching, I was able to run the following script:
$ frida -D barebone -p 0 -l demo.js
____
/ _ | Frida 16.1.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to GDB Remote Stub (id=barebone)[Remote::SystemSession ]-> $gdb.continue()[Remote::SystemSession ]-> >>> init_rest(){"r7": "0xffffffff",
"pc": "0x800306a",
"r8": "0xffffffff",
"xPSR": "0x41000000",
"r9": "0xffffffff",
"sp": "0x20000578",
"r0": "0x0",
"r10": "0xffffffff",
"lr": "0x8003069",
"r1": "0x40021008",
"r11": "0xffffffff",
"r2": "0xffffffff",
"r12": "0xffffffff",
"r3": "0xffffffff",
"r4": "0xffffffff",
"r5": "0xffffffff",
"r6": "0xffffffff"}<<< init_rest()retval=0x1
A few things to note here:
We set Interceptor.breakpointKind to hard, as our target’s code resides
in flash, which means software-breakpoints won’t work. This would not have
been necessary if I was using a J-Link or similar SWD interface, which
transparently reflashes as software-breakpoints are added.
The backend does not yet automatically resume, so we are doing that manually
through $gdb.continue(), part of this internal API, which exposes most
of GDB.Client to JavaScript. This is meant to become an internal
implementation detail, but will be needed while this new backend matures –
it should not yet be considered stable API.
We set the least significant bit to indicate to Interceptor that the target
function uses Thumb instruction encoding. This part may already be familiar to
you if you have previously used Frida’s conventional backends on 32-bit ARM.
The new Barebone backend connects to the GDB-compatible remote stub at
127.0.0.1:3333 by default. This matches what OpenOCD typically defaults to,
but can be overridden by setting the FRIDA_BAREBONE_ADDRESS environment
variable.
OS kernels
While my fun little cat door side-quest is a great test case for the tiny part
of the spectrum, there’s also a lot of potential in supporting larger systems.
One of the cooler use-cases there is definitely Corellium, as it means we can
instrument the iOS kernel. Using a Tamarin Cable it should even be possible
to get this working on a checkm8-exploitable physical device.
Before we touch on that though, let’s see if we can get things going with QEMU
and a live Linux kernel.
You might wonder how we’ve implemented Process.enumerateRanges(). This part is
for now only implemented on arm64, and it is accomplished by parsing the page
tables. (And if we’re talking to Corellium’s remote stub we use a
vendor-specific monitor command to save ourselves a lot of network roundtrips.)
So now that we’re peeking into a running kernel, one of the things we might want
to do is find internal functions and data structures. This is where the memory-
scanning API comes handy:
Here we’re looking for the Linux kernel’s arm64 syscall handler, matching on
its first three instructions. We use the masking feature to mask out the
immediates of the ADRP and MOV instructions (first and third instruction).
Let’s take it for a spin:
$ frida -D barebone -p 0 -l scan.js
____
/ _ | Frida 16.1.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to GDB Remote Stub (id=barebone)
Attaching...
{"base": "0xffffff8008080000",
"size": 4259840,
"protection": "r-x"}
Matches: [{"address": "0xffffff8008082f00",
"size": 12
}][Remote::SystemSession ]->
So now we’ve dynamically detected the kernel’s internal syscall handler! 🚀
Re-implementing the memory scanning feature was one of the highlights for me
personally, as @hsorbo and I had a lot of fun pair-programming on it. The
implementation is conceptually very similar to what we’re doing in our Fruity
backend for jailed iOS, and our new Linux injector: instead of transferring data
to the host, and searching that, we can get away with transferring only the
search algorithm, to run that on the target.
The memory scanner implementation is written in Rust, and helped prepare
the groundwork for a new cool feature I’m going to cover a bit later in this
post.
So, now that we know where the Linux kernel’s syscall handler is, we can use
Interceptor to install an instruction-level hook:
$ frida -D barebone -p 0 -l kernhook.js
____
/ _ | Frida 16.1.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to GDB Remote Stub (id=barebone)[Remote::SystemSession ]-> $gdb.continue()[Remote::SystemSession ]-> syscall! scno=63
syscall! scno=64
syscall! scno=73
syscall! scno=63
syscall! scno=64
syscall! scno=73
syscall! scno=63
syscall! scno=64
syscall! scno=56
syscall! scno=62
syscall! scno=64
syscall! scno=57
syscall! scno=29
syscall! scno=134
...
And that’s it – we are monitoring system calls across the entire system! 💥
Rust
One of the first things you’ll probably notice if you try the previous example
is that we slow down the system quite a bit. This is because Interceptor uses
breakpoints when a JavaScript function is specified as the callback.
Not to worry though. If we write our callback in machine code and pass a
NativePointer instead, Interceptor will pick a different strategy: it will
modify the target’s machine code to redirect execution to a trampoline, which in
turn calls the function at the address that we specify.
So that’s great. We only need to get our machine code into memory. Some of you
may be familiar with our CModule API. We don’t yet implement that one in
this new Barebone backend (and we will, eventually!), but we have something even
better. Enter RustModule:
constkernBase=ptr('0xffffff8008080000');constprocPidStatus=kernBase.add(0x15e600);constm=newRustModule(`
#[no_mangle]
pub unsafe extern "C" fn hook(ic: &mut gum::InvocationContext) -> () {
let regs = &mut ic.cpu_context;
println!("proc_pid_status() was called with x0={:#x} x1={:#x}",
regs.x[0],
regs.x[1],
);
}
`);Interceptor.attach(procPidStatus,m.hook);
The RustModule implementation uses a local Rust toolchain, assumed to be on your
PATH, to compile the code you provide it into a no_std self-contained ELF. It
relocates this ELF and writes it into the target’s memory. As part of this it
will also parse the MMU’s page tables and insert new entries there so the
uploaded code becomes part of the virtual address space, where the pages are
read/write/execute.
In this example we’re hooking proc_pid_status() in our live Linux kernel.
Note that File.readAllText() can be used to avoid having to inline Rust code
inside your JavaScript. Here we’re using inline code for the sake of brevity.
Now, with our Rust-powered agent, let’s take it for a spin:
$ frida -D barebone -p 0 -l kernhook2.js
____
/ _ | Frida 16.1.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to GDB Remote Stub (id=barebone)
Error: to enable this feature, set FRIDA_BAREBONE_HEAP_BASE to the physical base address to use, e.g. 0x48000000
at <eval>(/home/oleavr/src/demo/kernhook2.js:13)
at evaluate (native)
at <anonymous> (/frida/repl-2.js:1)[Remote::SystemSession ]->
Oops! That didn’t quite work. There is still one piece missing in our new
backend: we don’t yet have any “kernel bridges” in place that automatically
fingerprint the internals of known kernels in order to find a suitable internal
memory allocator we can use. This will also be needed to implement APIs such as
Process.enumerateModules(), which will allow listing the loaded kernel
modules/kexts. We could also locate the kernel’s process list and implement
enumerate_processes(), so frida-ps works. And those are only a couple of
examples… How about injecting frida-gadget into a user-space process? That
would be super-useful for an embedded system where we want to avoid modifying
the flash. Anyway, I digress 😊
So, on MCUs and unknown kernels you will have to tell Frida where, in physical
memory, we may clobber if you want to use intrusive features such as RustModule,
Interceptor in its inline hooking mode, Memory.alloc(), etc.
With that in mind, let’s retry our example, but this time we’ll set the
FRIDA_BAREBONE_HEAP_BASE environment variable:
$ export FRIDA_BAREBONE_HEAP_BASE=0x48000000
$ frida -D barebone -p 0 -l kernhook2.js
____
/ _ | Frida 16.1.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to GDB Remote Stub (id=barebone)[Remote::SystemSession ]-> m
{"hook": "0xffffff80080103e0"}[Remote::SystemSession ]-> $gdb.continue()
Yay! 🎉 So now, in the terminal where we have QEMU running, let’s try accessing
/proc/$pid/status three times, so the hooked function gets called:
# head -3 /proc/self/status
Name: head
Umask: 0022
State: R (running)# head -3 /proc/self/status
Name: head
Umask: 0022
State: R (running)# head -3 /proc/self/status
Name: head
Umask: 0022
State: R (running)
Over in our REPL, we should see our hook() getting hit three times:
proc_pid_status() was called with x0=0xffffffc00d4bca00 x1=0xffffff8008608758
proc_pid_status() was called with x0=0xffffffc00d4bc780 x1=0xffffff8008608758
proc_pid_status() was called with x0=0xffffffc00d4bc780 x1=0xffffff8008608758
It works! 🥳
There’s one important thing to note though: In our example we’re using
println!(), and this actually causes the target to hit a breakpoint, so the
host can read out the message passed to it, and bubble that up just like a
console.log() from JavaScript. This means you should only use this feature for
temporary debugging purposes, and throttle how often it’s called if on a hot
code-path.
The next thing you might want to do is pass external symbols into your
RustModule. For example if you want to call internal kernel functions from your
Rust code. This is accomplished by declaring them like this:
extern"C"{fnfrobnicate(data:*constu8,len:usize);}
Then when constructing the RustModule, pass it in through the second argument:
For those of you familiar with our CModule API, this part is exactly the same.
You can also use NativeCallback to implement portions host-side, in JavaScript,
but this needs to be handled with care to avoid performance bottlenecks. Going
in the opposite direction there is also NativeFunction, which you can use to
call into your Rust code from JavaScript.
Last but not least, you may also want to import existing Rust crates from
crates.io. This is also supported:
constm=newRustModule(source,{},{dependencies:['cstr_core = { version = "0.2.6", default-features = false }',]});
Corellium
What’s so exciting is that all of the Linux bits above all “just work” on
Corellium as well. All you need to do is point FRIDA_BAREBONE_ADDRESS at the
endpoint shown in Corellium’s UI under “Advanced Options” -> “gdb”.
Shout-out to the awesome folks at Corellium for their support while doing this.
They even implemented new protocol features to improve interoperability 🔥
Future
This new backend should be considered alpha quality for now, but I think it’s
already capable of so many useful things that it would be a shame to keep it
sitting on a branch.
You may notice that the JS APIs implemented only cover a subset, and not all
features are available on non-arm64 targets yet. But all of this will improve as
the backend matures. (Pull-requests are super-welcome!)
And as a fun aside, here’s Frida attached to the BeOS kernel:
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
objc: Handle modifiers. This makes type parsing more reliable, especially when
dealing with ivars which often times have the “atomic” modifier: exceptions
were thrown because the modifiers ended up being treated as unknown types.
Thanks @mrmacete!
android: Fix support for Android 14. Thanks @gsingh93! Also thanks
@jayluxferro for contributing a follow-up fix for a mistake I made while
merging @gsingh93’s PR.
gum-graft: Add support for chained imports. Thanks @mrmacete!
gumjs: Add NativePointer#readVolatile(), to provide a safe way to read from
memory that may become unmapped or have its memory protection changed midway
through. Thanks @hsorbo!
darwin: Improve tvOS support to also cover frida-server. Thanks @tmm1!
darwin: Plug memory leak in fallback kill() logic. Thanks @tmm1!
fruity: Handle failure to fetch dyld symbols.
compiler: Bump frida-compile to 16.2.2. Dependencies’ source maps are now also
bundled – thanks @vfsfitvnm!
compiler: Bump @types/frida-gum to 18.3.2, now with improved typings for
hexdump().
gdb: Add GDB.Client, by factoring out the guts of Fruity’s LLDB.Client, with
many protocol enhancements and interoperability fixes added on top.
elf-module: Improve API and make it cross-platform. Support loading from a
blob, expose relocations, and improve overall robustness.
capstone: Fix crash on x86 when building with MSVC.
Some exciting stability improvements this time around:
darwin: Make spawn() aware of the prewarm feature used on iOS >= 15. What
happens is that the most frequently used apps are being spawned ahead of time
by dasd and kept suspended until the user attempts to launch them, in order
to save some startup time. This was in the way of Frida’s spawn mechanism
because:
apps launched this way won’t be going through launchd when expected, causing
a “timeout was reached” error, or more complex race conditions
Frida needs to spawn a fresh process to ensure early instrumentation
We solve these problems by:
ignoring prewarm spawns from the launchd agent (though they’re still emitted
as spawn if spawn gating is enabled)
killing existing prewarmed apps before attempting to spawn them
Thanks @mrmacete!
glib: Ensure {Input,Output}Stream only g_poll() if pollable. This is essential on
Apple OSes and BSDs, where GLib uses kqueue to implement GMainContext, as it
may otherwise end up waiting forever when the file-descriptor represents an
ordinary file. Thanks @hsorbo!
android: Fix x86 devkits by improving libffi to avoid problematic relocations.
gadget: Fix deadlock during Windows process termination. Kudos to
@Palacee-hun for reporting!
Just a quick bug-fix release reviving support for Android x86/x86_64 systems
with ARM emulation. This is still a blind spot in our CI, and I forgot all about
it while working on the new Linux injector. Kudos to @stopmosk for promptly
reporting and helping triage this regression.
Time for a bug-fix release with only one change: turns out the ARMv8 BTI interop
introduced in 16.0.14 is problematic on Apple A12+ SoCs when running in
arm64e mode, i.e. with pointer authentication enabled.
Kudos to @miticollo for reporting and helping triage the cause, and
@mrmacete for digging further into it, brainstorming potential fixes, and
implementing the fix. You guys rock! ❤️
Seeing as TypeScript 5.0 was released last month, and frida.Compiler was still
at 4.9, we figured it’s time to upgrade it. So with this release we’re now
shipping 5.0.4. The upgrade also revealed a couple of bugs in our V8-based
runtime, and that our embedded frida-gum typings were slightly outdated.
Enjoy!
Changelog
gumjs: Fix task deadlock during V8 Isolate teardown.
gumjs: Fix undefined behavior during V8 snapshot creation.
Here’s a release fixing two stability issues affecting users on Apple platforms:
interceptor: Keep thread ports alive between suspend and resume on Darwin. We
were borrowing the Mach thread port right names released by
enumerate_threads(), assuming that another reference existed to keep each of
them alive. When this wasn’t the case we would at best pass an invalid Mach
port right name to thread_resume(), and worst-case we would use a totally
unrelated port. Regardless, we would leave such threads suspended forever.
Thanks @mrmacete!
agent: Dispose ThreadSuspendMonitor in its own transaction. Since Interceptor
relies on ThreadSuspendMonitor passthrough, disposing of it in its own
transaction and after all the other components which use Interceptor at
destruction time makes sure no Frida thread will attempt executing code on
non-executable pages at teardown time. Thanks @mrmacete!
Lots of goodies this time around. One of them is our brand new Linux injector.
This was a lot of fun, especially as it involved lots of pair-programming with
@hsorbo.
We’re quite excited about this one. Frida now supports injecting into Linux
containers, such as Flatpak apps. Not just that, it can finally inject code into
processes without a dynamic linker present.
Another neat improvement is if you’re running Frida on Linux >= 3.17, you may
notice that it no longer writes out any temporary files. This is accomplished
through memfd and a reworked injector signaling mechanism.
Our new Linux injector has a fully asynchronous design, without any dangerous
blocking operations that can result in deadlocks. It is also the first injector
to support providing a control channel to the injected payload.
Down the road the plan is to implement this in our other backends as well, and
make it part of our cross-platform Injector API. The thinking there is to make
it easier to implement custom payloads.
There are also many other goodies in this release, so definitely check out the
changelog below.
Enjoy!
Changelog
linux: Re-engineer injector. Thanks for the productive pair-programming,
@hsorbo!
linux: Fix the libc-based module enumeration.
linux: Fix query_libc_name() on musl.
linux: Fix module handle resolver logic on musl.
linux: Fix Module.ensure_initialized() on musl.
darwin: Make ThreadSuspendMonitor passthrough if called by Frida, to
avoid deadlock scenarios. Thanks @mrmacete!
darwin: During spawn(), always use PTYs for piped stdio, and enable
close-on-exec.
windows: Use existing DbgHelp instance if present. Thanks @fesily!
This time we’re bringing you additional iOS 15 improvements, an even better
frida.Compiler, brand new support for musl libc, and more. Do check out the
changelog below for more details.
Enjoy!
Changelog
ios: Fix spawn() on lower versions of iOS 15. Thanks @as0ler and
@mrmacete!
ios: Ensure launchd prioritizes our daemon. Kudos to @getorix for
investigating and suggesting this fix.
compiler: Bump frida-compile, frida-fs, and Gum typings. This means that
frida.Compiler now also works properly on linux-arm64 and linux-x86.
linux: Add support for musl libc, including CI that publishes release assets
for x86_64 and arm64.
gumjs: Add console.debug() and console.info(). Thanks @oriori1703!
gumjs: Fix build when node_modules/@types exists above us.
gumjs: Ignore tcclib.h symbols when generating runtime. Thanks @milahu!
build: Improve support for shared builds. Thanks @milahu!
The main theme of this release is improved support for jailbroken iOS. We now
support iOS 16.3, including app listing and launching. Also included is improved
support for iOS 15, and some regression fixes for older iOS versions.
There are also some other goodies in this release, so definitely check out the
changelog below.
Enjoy!
Changelog
darwin: Fix app listing and launching on iOS >= 16. Thanks for the productive
pair-programming, @hsorbo!
darwin: Fix crash during early instrumentation of modern dylds.
darwin: Fix breakpoint conflict in early instrumentation, a regression
introduced in 16.0.8 as part of improving spawn() performance.
Thanks @mrmacete!
package-server-ios: Force xz compression.
darwin-grafter: Create multiple segments if needed. Thanks @mrmacete!
interceptor: Flip page protection on Darwin grafted import activation.
Thanks @mrmacete!
stalker: Fix handling of ARM LDMIA without writeback.
This time we’ve focused on polishing up our macOS and iOS support. For those of
you using spawn() and spawn-gating for early instrumentation, things are now
in much better shape.
i/macOS spawn() performance
The most exciting change in this release is all about performance. Programs that
would previously take a while to start when launched using Frida should now be a
lot quicker to start. This long-standing bottleneck was so bad that an app with
a lot of libraries could fail to launch due to Frida slowing down its startup
too much.
i/macOS and SIGPIPE
Next up we have a fix for a long-standing reliability issue. Turns out our
file-descriptors used for IPC did not have SO_NOSIGPIPE set, so we could
sometimes end up in a situation where either Frida or the target process
terminated abruptly, and the other side would end up getting zapped by SIGPIPE
while trying to write().
Sandboxed environments, part two
The previous release introduced some bold new changes to support injecting into
hardened targets. Since then @hsorbo and me dug back into our recent GLib
kqueue() patch and fixed some rough edges. We also fixed a regression where
attaching to hardened processes through usbmuxd would fail with “connection
closed”.
Linux
On the Linux and Android side of things, some of you may have noticed that
thread enumeration could fail randomly, especially inside busy processes. That
issue has now finally been dealt with.
Also, thanks to @drosseau we also have an error-handling improvement that
should avoid some confusion when things fail in 32-/64-bit cross-arch builds.
This week @hsorbo and me spent some days trying to get Frida working better
in sandboxed environments. Our goal was to be able to get Frida into Apple’s
SpringBoard process on iOS. But to make things a little interesting, we figured
we’d start with imagent, the daemon that handles the iMessage protocol. It has
been hardened quite a bit in recent OS versions, and Frida was no longer able to
attach to it.
So we first started out with this daemon on macOS, just to make things easier to
debug. After finding the daemon’s sandbox profile at
/System/Library/Sandbox/Profiles/com.apple.imagent.sb, it was hard to miss the
syscall policy. It disallows all syscalls by default, and carefully enables some
groups of syscalls, plus some specific ones that it also needs.
We then discovered that Frida’s use of the pipe() syscall was the first hurdle.
This code is not actually in Frida itself, but in GLib, the excellent library
that Frida uses for data structures, cross-platform threading primitives, event
loop, etc. It uses pipe() to implement a primitive needed for its event loop.
More precisely, it uses this primitive to wake up the event loop’s thread in
case it is blocking in a poll()-style syscall.
Anyway, we noticed that kqueue() is part of the groups of syscalls explicitly
allowed. Given that Apple’s kqueue() supports polling file-descriptors and Mach
ports at the same time, among other things, it’s likely to be needed in a lot of
places, and thus allowed by a broad range of sandbox profiles. It is also a
great fit for us, since EVFILT_USER means there is a way to wake up the event
loop’s thread. Not just that, but it doesn’t cost us a single file-descriptor.
After lots of coffee and fun pair-programming, we arrived at a patch that
switches GLib’s event loop over to kqueue() on OSes that support it. This got
us to the next hurdle: Frida is using socket APIs for file-descriptor passing,
part of the child-gating feature used for instrumenting children of the current
process. However, since hardened system services aren’t likely to be allowed to
do things like fork() and execve(), it is fine to simply degrade this part of
our functionality. That was tackled next, and boom… Frida is finally able
to attach to imagent. 🎉 Yay!
Next up we moved over to iOS and took it for a spin there. Much to our surprise,
Frida could attach to SpringBoard right out of the gate. Later we tried
notifyd and profiled, and could attach to those too. Even on latest iOS 16.
But, there’s still work to do, as Frida cannot yet attach to imagent and
WebContent on iOS. This is exciting progress, though.
Injection on iOS >= 15
While doing all of this we also tracked down a crash on iOS where frida-server
would get killed due to EXC_GUARD during injection on iOS >= 15. That has now
also been fixed, just in time for the release!
DebugSymbol API
Another exciting piece of news is that @mrmacete improved our DebugSymbol
API to consistently provide the full path instead of only the filename. This was
a long-standing inconsistency across our different platform backends. While at
it he also exposed the column, so you also get that in addition to the line
number.
Interceptor.replace(), but fast
Last but not least it’s worth mentioning an exciting new improvement in
Interceptor. For those of you using it from C, there’s now replace_fast()
to complement replace(). This new fast variant emits an inline hook that
vectors directly to your replacement. You can still call the original if you
want to, but it has to be called through the function pointer that Interceptor
gives you as an optional out-parameter. It also cannot be combined with
attach() for the same target. It is a lot faster though, so definitely good to
be aware of when needing to hook functions in hot code-paths.
EOF
That’s all this time. Enjoy!
Changelog
darwin: Disable advanced features in hardened processes.
darwin: Port GLib’s MainContext to use kqueue() instead of poll().
darwin: Fix EXC_GUARD during injection on iOS >= 15.
package-server-ios: Port launchd plist to iOS 16.
gadget: Do not cloak main thread while loading.
debug-symbol: Ensure path is absolute and add column field. Thanks
@mrmacete!
Turns out a serious stability regression made it into Frida 16.0.3, where our
out-of-process dynamic linker for Apple OSes could end up crashing the target
process. This is especially disastrous when the target process is launchd, as it
results in a kernel panic. Thanks to the amazing work of @mrmacete, this
embarrassing regression is now fixed. 🎉 Enjoy!
Some cool new things this time. Let’s dive right in.
tvOS and watchOS
One of the exciting contributions this time around came from @tmm1, who
opened a whole bunch of pull-requests adding support for tvOS. Yay! As part of
landing these I took the opportunity to add support for watchOS as well.
This also turned out to be a great time to simplify the build system, getting
rid of complexity introduced to support non-Meson build systems such as
autotools. So as part of this clean-up we now have separate binaries for
Simulator targets such as the iOS Simulator, tvOS Simulator, etc. Previously we
only supported the x86_64 iOS Simulator, and now arm64 is covered as well.
macOS 13 and iOS 16
Earlier this week, @hsorbo and I did some fun and productive
pair-programming where we tackled the dynamic linker changes in Apple’s latest
OSes. Those of you using Frida on i/macOS may have noticed that spawn() stopped
working on macOS 13 and iOS 16.
This was a fun one. It turns out that the dyld binary on the filesystem now
looks in the dyld_shared_cache for a dyld with the same UUID as itself, and
if found vectors execution there instead. Explaining why this broke Frida’s
spawn() functionality needs a little context though, so bear with me.
Part of what Frida does when you call attach() is to inject its agent, if it
hasn’t already done this. Before performing the injection however, we check if
the process is sufficiently initialized, i.e. whether libSystem has been
initialized.
When this isn’t the case, such as after spawn(), where the target is suspended
at dyld’s entrypoint, Frida basically advances the main thread’s execution until
it reaches a point where libSystem is ready. This is typically accomplished
using a hardware breakpoint.
So because the new dyld now chains to another copy of itself, inside the
dyld_shared_cache, Frida was placing a breakpoint in the version mapped in from
the filesystem, instead of the one in the cache. Obviously that never got hit,
so we would end up timing out while waiting for this to happen.
The fix was reasonably straight-forward though, so we managed to squeeze
this one into the release in the last minute.
Compiler improvements
The frida.Compiler just got a whole lot better, and now supports additional
configuration through tsconfig.json, as well as using local frida-gum typings.
V8 debugger
The V8 debugger integration was knocked out by the move to having one V8
Isolate per script, which was a delicate refactoring needed for V8 snapshot
support. This is now back in working order.
Dependency upgrades
One of the heavier lifts this time around was clearly dependency upgrades, where
most of our dependencies have now been upgraded: from Capstone supporting
ARMv9.2 to latest GLib using PCRE2, etc.
The move to PCRE2 means our Memory.scan() regex support just got upgraded, since
GLib was previously using PCRE1. We don’t yet enable PCRE2’s JIT on any
platforms though, but this would be an easy thing to improve down the road.
Cross-post: frida-tools 12.0.2
We also have a brand new release of frida-tools, which thanks to @tmm1 has a
new and exciting feature. The frida-ls-devices tool now displays higher
fidelity device names, with OS name and version displayed in a fourth column:
To upgrade:
$ pip3 install-U frida frida-tools
EOF
There are also some other goodies in this release, so definitely check out the
changelog below.
Enjoy!
Changelog
darwin: Add support for watchOS and tvOS. Thanks @tmm1!
darwin: Fix early instrumentation on macOS 13 and iOS 16. (Thanks for the
pair-programming on this one, @hsorbo!)
interceptor: Suspend threads while mutating pages on W^X systems such
as iOS. This improves stability when instrumenting busy processes.
system-session: Re-enable Exceptor for now.
compiler: Allow configuring target, lib, and strict.
compiler: Fix support for local frida-gum typings.
compiler: Use latest @types/frida-gum from git.
ci: Drop prebuilds for Node.js 10.
ci: Publish prebuilds for Node.js 19.
ci: Publish prebuilds for Electron 21 instead of 20.
unw-backtracer: Improve accuracy on 32-bit ARM.
thread: Add suspend() and resume() to the Gum C API.
darwin: Improve handling of chained fixups.
darwin: Fix Objective-C symbol synthesis on arm64e.
linux: Detect noxsave on Linux.
linux: Improve injector to handle faux .so mappings. Thanks @lx866!
module-map: Support lookups with ptrauth bits set.
It’s Friday! Here’s a brand new release with lots of improvements:
macOS: Fix support for attaching to arm64e system apps and services on
macOS >= 12.
i/macOS: Upgrade support for chained fixups.
iOS: Fix system session on arm64e devices running iOS < 14.
system-session: Disable Exceptor and monitors.
Exceptor interferes with the signal handling of the hosting process, which
is risky and prone to conflict.
Monitors aren’t really useful for the system session.
interceptor: Fix trampolines used in grafted mode on iOS/arm64. Thanks @mrmacete!
compiler: Fix stability issues on multiple platforms.
compiler: Fix the @frida/path shim.
compiler: Speed things up by also making use of snapshot on non-x86/64 Linux.
devkit: Fix regressions in the Windows, macOS, and Linux devkits.
v8: Fix heap corruptions caused by our libc-shim failing to implement
malloc_usable_size() APIs, which V8 relies on.
v8: Fix support for scripts using different snapshots, which was broken due to
V8 previously being configured to share read-only space across isolates. That
option conflicts with multiple snapshots.
v8: Improve teardown.
v8: Fix v8::External API contract violations.
v8: Upgrade to 10.9.42.
zlib: Upgrade to 1.2.13.
gum: Fix subproject build for ELF-based OSes.
python: Fix tags of published Linux wheels.
Add legacy platform tags so older versions of pip recognize them.
Pretend some of the wheels require glibc >= 2.17, as lower versions
aren’t recognized on certain architectures.
Hope some of you are enjoying frida.Compiler! In case you have no idea what that
is, check out the 15.2.0 release notes.
Performance
Back in 15.2.0 there was something that bothered me about frida.Compiler: it
would take a few seconds just to compile a tiny “Hello World”, even on my
i9-12900K Linux workstation:
$ time frida-compile explore.ts -o _agent.js
real 0m1.491s
user 0m3.016s
sys 0m0.115s
After a lot of profiling and insane amounts of yak shaving, I finally
arrived at this:
$ time frida-compile explore.ts -o _agent.js
real 0m0.325s
user 0m0.244s
sys 0m0.109s
That’s quite a difference! This means on-the-fly compilation use-cases such as
frida -l explore.ts are now a lot smoother. More importantly though, it means
Frida-based tools can load user scripts this way without making their users
suffer through seconds of startup delay.
Snapshots
You might be wondering how we made our compiler so quick to start. If you take
a peek under the hood, you’ll see that it uses the TypeScript compiler. This is
quite a bit of code to parse and run at startup. Also, loading and processing
the .d.ts files that define all of the types involved is actually even more
expensive.
The first optimization that we implemented back in 15.2 was to simply use our
V8 runtime if it’s available. That alone gave us a nice speed boost. However,
after a bit of profiling it was clear that V8 realized that it’s dealing with
a heavy workload once we start processing the .d.ts files, and that resulted in
it spending a big chunk of time just optimizing the TypeScript compiler’s code.
This reminded me of a really cool V8 feature that I’d noticed a long time ago:
custom startup snapshots. Basically if we could warm up the TypeScript
compiler ahead of time and also pre-create all of the .d.ts source files when
building Frida, we could snapshot the VM’s state at that point and embed the
resulting startup snapshot. Then at runtime we can boot from the snapshot and
hit the ground running.
As part of implementing this, I extended GumJS so a snapshot can be passed to
create_script(), together with the source code of the agent. There is also
snapshot_script(), used to create the snapshot in the first place.
For example:
importfridasession=frida.attach(0)snapshot=session.snapshot_script("const example = { magic: 42 };",warmup_script="true",runtime="v8")print("Snapshot created! Size:",len(snapshot))
This snapshot could then be saved to a file and later loaded like this:
Note that snapshots need to be created on the same OS/architecture/V8 version
as they’re later going to be loaded on.
V8 10.x
Another exciting bit of news is that we’ve upgraded V8 to 10.x, which means we
get to enjoy the latest VM refinements and JavaScript language features.
Considering that our last upgrade was more than two years ago, it’s definitely a
solid upgrade this time around.
The curse of multiple build systems, part two
As you may recall from the 15.1.15 release notes, we were closer than ever
to reaching the milestone where all of Frida can be built with a single build
system. The only component left at that point was V8, which we used to build
using Google’s GN build system. I’m happy to report that we have finally reached
that milestone. We now have a brand new Meson build system for V8. Yay!
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changelog
compiler: Use snapshot to reduce startup time.
compiler: Bump frida-compile and other dependencies.
Add support for JavaScript VM snapshots. This is only implemented by the V8
backend, as QuickJS does not currently support this.
Move debugger API from Session to Script. This is necessary since V8’s
debugger works on a per-Isolate basis, and we now need one Isolate per Script
in order to support snapshots.
Two more improvements, just in time for the weekend:
darwin: Always host system session locally. In this way we avoid needing to
write our frida-helper to a temporary file and spawn it just to use the system
session (PID 0).
darwin: Rework frida-helper IPC to avoid Mach ports. This means we avoid
crashing on recent versions of macOS. Kudos to co-author @hsorbo for the
productive pair-programming on this one!
Two small but significant bugfixes this time around:
compiler: Ignore irrelevant changes during watch().
darwin: Improve accuracy of memory range file info. By using
PROC_PIDREGIONPATHINFO2 when available, so the query is constrained to
vnode-backed mappings. Kudos to @i0n1c for discovering and tracking
down this long-standing issue.
Super-excited about this one. What I’ve been wanting to do for years is to
streamline Frida’s JavaScript developer experience. As a developer I may start
out with a really simple agent, but as it grows I start to feel the pain.
Early on I may want to split up the agent into multiple files. I may also want
to use some off-the-shelf packages from npm, such as frida-remote-stream.
Later I’d want code completion, inline docs, type checking, etc., so I move the
agent to TypeScript and fire up VS Code.
Since we’ve been piggybacking on the amazing frontend web tooling that’s already
out there, we already have all the pieces of the puzzle. We can use a bundler
such as Rollup to combine our source files into a single .js, we can use
@frida/rollup-plugin-node-polyfills for interop with packages from npm, and
we can plug in @rollup/plugin-typescript for TypeScript support.
That is quite a bit of plumbing to set up over and over though, so I eventually
created frida-compile as a simple tool that does the plumbing for you, with
configuration defaults optimized for what makes sense in a Frida context. Still
though, this does require some boilerplate such as package.json, tsconfig.json,
and so forth.
To solve that, I published frida-agent-example, a repo that can be cloned
and used as a starting point. That is still a bit of friction, so later
frida-tools got a new CLI tool called frida-create. Anyway, even with all of
that, we’re still asking the user to install Node.js and deal with npm, and
potentially also feel confused by the .json files just sitting there.
Then it struck me. What if we could use frida-compile to compile frida-compile
into a self-contained .js that we can run on Frida’s system session? The system
session is a somewhat obscure feature where you can load scripts inside of the
process hosting frida-core. For example if you’re using our Python bindings,
that process would be the Python interpreter.
Once we are able to run that frida-compile agent inside of GumJS, we can
communicate with it and turn that into an API. This API can then be exposed
by language bindings, and frida-tools can consume it to give the user a
frida-compile CLI tool that doesn’t require Node.js/npm to be installed. Tools
such as our REPL can seamlessly use this API too if the user asks it to load a
script with a .ts extension.
on_diagnostics: [{'category': 'error', 'code': 6053,
'text': "File '/home/oleavr/src/agent.ts' not ""found.\n The file is in the program ""because:\n Root file specified for"" compilation"}]
…
We forgot to actually create the file! Ok, let’s create agent.ts:
This weird-looking format is how GumJS’ allows us to opt into the new ECMAScript
Module (ESM) format where code is confined to the module it belongs to instead
of being evaluated in the global scope. What this also means is we can load
multiple modules that import/export values. The .map files are optional and can
be omitted, but if left in they allow GumJS to map the generated JavaScript line
numbers back to TypeScript in stack traces.
Anyway, let’s take _agent.js for a spin:
$ frida -p 0 -l _agent.js
____
/ _ | Frida 15.2.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to Local System (id=local)
Attaching...
Hello 15.2.0!
[Local::SystemSession ]->
It works! Now let’s try refactoring it to split the code into two files:
agent.ts
import{log}from"./log.js";log("Hello from Frida:",Frida.version);
If we now run our example compiler script again, it should produce a slightly
more interesting-looking _agent.js:
📦
204 /agent.js.map
72 /agent.js
199 /log.js.map
58 /log.js
✄
{"version":3,"file":"agent.js","sourceRoot":"/home/oleavr/src/","sources":["agent.ts"],"names":[],"mappings":"AAAA,OAAO,EAAE,GAAG,EAAE,MAAM,UAAU,CAAC;AAE/B,GAAG,CAAC,mBAAmB,EAAE,KAAK,CAAC,OAAO,CAAC,CAAC"}
✄
import { log } from "./log.js";
log("Hello from Frida:", Frida.version);
✄
{"version":3,"file":"log.js","sourceRoot":"/home/oleavr/src/","sources":["log.ts"],"names":[],"mappings":"AAAA,MAAM,UAAU,GAAG,CAAC,GAAG,IAAW;IAC9B,OAAO,CAAC,GAAG,CAAC,GAAG,IAAI,CAAC,CAAC;AACzB,CAAC"}
✄
export function log(...args){
console.log(...args);}
Loading that into the REPL should yield the exact same result as before.
watch()
Let’s turn our toy compiler into a tool that loads the compiled script, and
recompiles whenever a source file changes on disk:
importfridaimportsyssession=frida.attach(0)script=Nonedefon_output(bundle):globalscriptifscriptisnotNone:print("Unloading old bundle...")script.unload()script=Noneprint("Loading bundle...")script=session.create_script(bundle)script.on("message",on_message)script.load()defon_diagnostics(diag):print("on_diagnostics:",diag)defon_message(message,data):print("on_message:",message)compiler=frida.Compiler()compiler.on("output",on_output)compiler.on("diagnostics",on_diagnostics)compiler.watch("agent.ts")sys.stdin.read()
And off we go:
$ python3 explore.py
Loading bundle...
Hello from Frida: 15.2.0
If we leave that running and then edit the source code on disk we should see
some new output:
Unloading old bundle...
Loading bundle...
Hello from Frida version: 15.2.0
Yay!
frida-compile
We can also use frida-tools’ new frida-compile CLI tool:
$ frida-compile agent.ts -o _agent.js
It also supports watch mode:
$ frida-compile agent.ts -o _agent.js -w
REPL
Our REPL is also powered by the new frida.Compiler:
$ frida -p 0 -l agent.ts
____
/ _ | Frida 15.2.0 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
.... object? -> Display information about 'object'....exit/quit -> Exit
........ More info at https://frida.re/docs/home/
........ Connected to Local System (id=local)
Compiled agent.ts (1428 ms)
Hello from Frida version: 15.2.0
[Local::SystemSession ]->
Shoutout
Shoutout to @hsorbo for the fun and productive pair-programming sessions
where we were working on frida.Compiler together! 🙌
EOF
There are also quite a few other goodies in this release, so definitely check
out the changelog below.
Enjoy!
Changelog
core: Add Compiler API. Only exposed by Python bindings for now, but available
from C/Vala.
interceptor: Improve replace() to support returning original. Thanks
@aviramha!
gumjs: Fix typing for pc in the writer options.
gumjs: Fix V8 ESM crash with circular dependencies.
gumjs: Handle ESM bundles with multiple aliases per module.
gumjs: Tighten up the Checksum data argument parsing.
android: Fix null pointer deref in crash delivery. Thanks @muhzii!
fruity: Use env variables to find usbmuxd. Thanks @0x3c3e!
ios: Make Substrate detection logic a bit more resilient. Thanks
@lemon4ex!
meson: Only try to use V8 if available. Thanks @muhzii!
windows: Add support for building without V8.
devkit: Fix library dependency hints on Windows. Thanks @nblog!
Those of you using our JavaScript File API may have noticed that it supports
writing to the given file, but there was no way to read from it. This is now
supported.
For example, to read each line of a text-file as a string:
Going back to the example earlier, seek() also supports relative offsets:
f.seek(7,File.SEEK_CUR);f.seek(-3,File.SEEK_END);
Retrieving the current file offset is just as easy:
constoffset=f.tell();
Checksum API
The other JavaScript API addition this time around is for when you want to
compute checksums. While this could be implemented in JavaScript entirely in
“userland”, we do get it fairly cheap since Frida depends on GLib, and it
already provides a Checksum API out of the box. All we needed to do was
expose it.
Putting it all together, this means we can read a file and compute its SHA-256:
It appears I should have had some more coffee this morning, so here’s another
release to actually fix this broken fix back in 15.1.25:
java: (android) Prevent ART from compiling replaced methods
Turns out the kAccCompileDontBother constant changed in Android 8.1. It also
didn’t exist before 7.0. Oops! This release fixes it, for real this time 😊
Quite a few exciting bits in this release. Let’s dive right in.
FPU/vector register access
Some great news for those of you using Frida on 32- and 64-bit ARM. Up until
now, we have only exposed the CPU’s integer registers, but as of this release,
FPU/vector registers are also available! 🎉
For 32-bit ARM this means q0 through q15, d0 through d31, and s0
through s31. As for 64-bit ARM they’re q0 through q31, d0 through d31,
and s0 through s31. If you’re accessing these from JavaScript, the vector
properties are represented using ArrayBuffer, whereas for the others we’re
using the number type.
Java.backtrace()
Our existing Java.backtrace() API now provides a couple of new properties in the
returned frames, which now also expose methodFlags and origin.
Quality
I finally plugged a memory leak in our RPC server-side code. This was
introduced by me in 15.1.10 when implementing an optimization in the Vala
compiler’s code generation for DBus reply handling. Shoutout to @rev1si0n
for reporting and helping track down this regression!
EOF
There are also some other goodies in this release, so definitely check out the
changelog below.
Enjoy!
Changelog
vala: Plug leak in server-side GDBus reply handling. This affected all
server-side implementations in Frida.
glib: Disable support for “charset.alias”. This means we no longer try to
open this file, which could cause sandbox violations on some systems, such
as iOS.
java: (android) Add methodFlags to Java.backtrace() frames.
java: (android) Add origin to Java.backtrace() frames.
java: (android) Prevent ART from compiling replaced methods. Kudos to
@s1341 for figuring this one out!
cpu-context: Add ARM FPU/vector registers and NZCV.
cpu-features: Add VFPD32 flag and detection logic.
stalker: Fix VFP D32 detection in the arm backend.
gumjs: Add vector regs to arm_reg bindings.
x86-writer: Add put_fx{save,rstor}_reg_ptr().
arm-writer: Add load/store variants without offset.
arm-writer: Add put_v{push,pop}_range().
arm-writer: Remove noop check from put_ands_reg_reg_imm().
arm-writer: Rename *_registers() to *_regs().
arm-writer: Support vector push/pop with Q regs.
thumb-writer: Add put_v{push,pop}_range().
thumb-writer: Support vector push/pop with Q regs.
arm64-writer: Add load/store variants without offset.
arm64-writer: Add put_mov_{reg_nzcv,nzcv_reg}().
libc-shim: Support old system headers on Linux/ARM.
node: Bump dependencies.
node: Publish prebuilds for Electron 19 instead of 18.
Only one change this time, but it’s an important one for those of you using
Frida on Android: Our Java method hooking implementation was crashing in some
cases, where we would pick a scratch register that conflicted with the generated
code. This is now fixed.
The main theme of this release is OS support, where we’ve fixed some rough edges
on Android 12, and introduced preliminary support for Android 13. While working
on frida-java-bridge I also found myself needing some of the JVMTI code in the
JVM-specific backend. Those bits are now shared, and the JVM-specific code is
in better shape, with brand new support for JDK 17.
We have also improved stability in several places, and made it easier to use the
CodeWriter APIs safely. Portability has also been improved, where our
QuickJS-based JavaScript runtime finally works when cross-compiled for
big-endian from a little-endian build machine, and vice versa.
To learn more, be sure to check out the changelog below.
Enjoy!
Changelog
linux: Handle spurious signals during ptrace().
android: Add missing SELinux rule for system_server on Android 12+.
android: Fix Android 13 detection on real devices.
android: Handle new linker internals in Android 13.
java: Improve the Java.enumerateMethods() error message. Thanks @jpstotz!
gumjs: Disable the CodeWriter flush_on_destroy option. In this way, the
writers are safer to use as they won’t be writing to memory once they’re
garbage-collected. At that point the target memory may no longer be writable,
or might be owned by other code.
gumjs: Embed byteswapped QuickJS bytecode when needed. This means GumJS can be
cross-compiled across endians.
gumjs: Fix double free in the Instruction copy logic.
gumjs: Fix Relocator instruction accessors.
gumjs: Flush CodeWriter on reset() and dispose().
gumjs: Improve NativePointer#strip() to support ARM TBI.
gumjs: Make Instruction wrapper safer in zero-copy mode.
gumjs: Plug Relocator leak in the QuickJS runtime.
quickjs: Fix support for byteswapped output. Also upgrade QuickJS to latest
upstream version with Unicode 14 updates.
Turns out the major surgery that Gum went through in 15.1.15 introduced some
error-handling regressions. Errors thrown vs. actually expected by the Vala code
in frida-core did not match, which resulted in the process crashing instead of a
friendly error bubbling up to e.g. the Python bindings. That is now finally
taken care of. I wish we had noticed it sooner, though — we’re clearly lacking
test coverage in this area.
Beside the error-handling fixes, we’re also including a build system fix for
incremental build issues. Kudos to Londek for this nice contribution.
It was discovered that 15.1.10 broke inline hooking in frida-java-bridge on
Android/x86_64. This release fixes it.
This time we’re also moving to shipping Node.js prebuilds for v18 instead of
v17. (Sigh, should port frida-node to Node-API so we can stop this madness!)
Turns out 15.1.18 had a release automation bug that resulted in stale Python
binding artifacts getting uploaded.
To make this release a little happier, I also threw in a Stalker improvement
for x86/64, where the clone3 syscall is now handled as well. This was
caught by Stalker’s test-suite on some systems.
Lots of improvements all over the place this time. Many stability improvements.
I have continued improving our CI and build system infrastructure. QNX and MIPS
support are back from the dead, after long-standing regressions. These went
unnoticed due to lack of CI coverage. We now have CI in place to ensure that
won’t happen again.
Do check out the changelog below for a full overview of what’s new.
Enjoy!
Changelog
gadget: Fix deadlock when Gadget is blocking the dynamic linker with its
internal lock(s) held while waiting for resume(). In that case we are
processing the JS MainContext while blocking, with network I/O handled by the
Gadget thread. Because Stalker may interact with the dynamic linker during its
class_init(), we must ensure that it happens from the JS thread and not the
network I/O thread.
exit-monitor: Fix deadlock when a fork() goes unnoticed.
darwin: Skip pseudo-signing when running on Corellium.
python: Fix index URL retrieval on Python < 3.6. Thanks @serfend!
node: Publish prebuilds for Electron 18 instead of 16.
ci: Add Linux/MIPS, FreeBSD/x86_64, FreeBSD/arm64, and QNX/armeabi. For Gum,
also add Windows/x86_64, macOS/x86_64, Linux/x86, Linux/x86_64, iOS/arm64,
Android/x86, Android/arm, and Android/arm64.
One notable improvement in this release is that Java.backtrace() got a major
overhaul. It is now lazy and >10x faster. I have also refined its API,
which is now considered stable.
While working on frida-java-bridge, I optimized how Env objects are handled,
so we can recycle an existing instance if we already have one for the current
thread.
The remaining goodies are covered by the changelog below, so definitely check
it out.
Enjoy!
Changelog
Fix devkits for i/macOS, Android, and QNX, where parts of libiconv were
missing.
Improve devkit packaging on LLVM toolchains.
Improve diet mode support in GLib.
cmodule: Expose g_strndup().
cmodule: Expose Gum’s Thread Local Storage API.
java: Rework Java.backtrace() to be lazy and >10x faster.
Move thread transition and stack walking logic to CModule.
Return a Backtrace object instead of an array with the frames.
Provide a cheap id property that can be used for deduplication.
Lazily compute the frames when accessing the frames property.
java: Avoid expensive Env creation when possible.
python: Improve index URL handling. Thanks @GalaxySnail!
This time we’re bringing you two bugfixes and one new feature, just in time for
the weekend.
Gum used to depend on GIO, but that dependency was removed in the previous
release. The unfortunate result of that change was that agent and gadget no
longer tore down GIO, as they were relying on Gum’s teardown code doing that.
What this meant was that we were leaving threads behind, and that is never a
good thing. So that’s the first bugfix.
Also in the previous release, over in our Python bindings, setup.py went through
some heavy changes. We improved the .egg download logic, but managed to break
the local .egg logic. That’s the second bugfix.
Onto the new feature. For those of you using Gum’s JavaScript bindings, GumJS,
we now support console.count() and console.countReset(). These are
implemented by browsers and Node.js, and make it easy to count the number of
times a given label has been seen. Kudos to @yotamN for this nice
contribution.
Quite a few exciting bits in this release. Let’s dive right in.
FreeBSD
Our ambition is to support all platforms that our users care about. In this
release I wanted to plant the first seed in expanding that to BSDs. So now I’m
thrilled to announce that Frida finally also supports FreeBSD! 🎉
For now we only support x86_64 and arm64, but expanding to the remaining
architectures is straight-forward in case anybody is interested in helping out.
The porting effort resulted in several architectural refinements and improved
robustness for ELF-based OSes in general. It also gave me some ideas on how to
improve our Linux injector to support injecting into containers, which is
something I’d like to do down the road.
Stalker Performance
Back in 15.1.10, Stalker got a massive performance boost on x86/64. In this
release those same ideas have been applied to our arm64 backend. This includes
improved locality, better inline caches, etc. I’m told we were able to beat or
match QEMU in FuzzBench back then, and now we should be in good shape on arm64
as well. We also managed to improve stability while at it. Exciting!
GObject Introspection
Back in 14.1, @meme wired up build system support for
GObject Introspection. This means we have a machine-readable description of
all of our APIs, which lets us piggyback on existing language binding
infrastructure, and even get auto-generated reference docs for free.
This release adds a lot of annotations and doc-strings to Gum, and we are now
closer than ever to having auto-generated reference docs. Still some work left
to do before it makes sense to publish the generated documentation, but it’s not
far off. If anyone is interested in pitching in, check out Gum’s CI and have
a look at the warnings output by GObject Introspection.
Meson subproject support
One thing I really like about the Meson build system is its support for
subprojects. Gum now supports being used as a subproject. Some of you may
already be consuming Gum through its devkit binaries, and now you have a
brand new option that is even easier.
The main advantage over using a devkit is that everything is built from source,
so it’s easy to experiment with the code.
We put a lot of effort into making sure that Frida can scale from desktops all
the way down to embedded systems. In this release I spent some time profiling
our binary footprint, and based on this I ended up making a slew of tweaks and
build options to reduce our footprint.
I was curious how small I could make a Gum Hello World program that only
uses Interceptor. The end result was measured on 32-bit ARM w/ Thumb
instructions, where Gum and its dependencies are statically linked, and the only
external dependency is the system’s libc.
The result was as small as 55K (!), and that made me really excited. What I did
was to introduce new build options in Gum, GLib, and Capstone. For Gum we now
support a “diet” mode where we don’t make use of GObject and only offer a plain
C API. This means it won’t support GObject Introspection and fancy language
bindings. It also means we don’t offer the full Gum API, but that is something
that can be expanded on in the future.
Similarly for GLib there is also a new “diet” mode, and boils down to disabling
its slice allocator, debugging features, and a few other minor tweaks like that.
As for Capstone, I ended up introducing a new “profile” option that can be set
to “tiny”. The result of doing so is that Capstone only understands enough of
the instruction set to determine each instruction’s length, and provide some
details on position-dependent instructions. The idea is to only support what
our Relocator implementations need, as those do most of the heavy lifting
behind Interceptor and Stalker.
While I wouldn’t recommend using these build options unless you really need a
footprint that small, it’s good to be aware of what’s possible. We also offer
other, less extreme options. Read more in our footprint docs.
The curse of multiple build systems
Something that has been bothering me for as long as Frida has existed, is that
building Frida involves dealing with multiple build systems. While we do of
course try to hide that complexity behind scripts/makefiles, we are inevitably
going to have unhappy users who find themselves trying to figure out why Frida
is not building for them.
Some are also interested in cross-compiling Frida for a slightly different libc,
toolchain, or what have you. They may even be looking to add support for an OS
we don’t yet support. Chances are that we’re going to demotivate them the moment
they realize they need to deal with four different build-systems: Meson,
autotools, custom Perl scripts (OpenSSL), and GN (V8).
As we are happy users of Meson, my goal is to “Mesonify all the things!”. With
this release, we have now finally reached the point where virtually all of our
required dependencies are built using Meson. The only exception is V8, but we
will hopefully also build that with Meson someday. (Spoiler from the future:
Frida 16 will get us there!)
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changelog
Add support for FreeBSD.
Add support for ARMv4, for instrumenting old embedded systems.
Add build options for binary footprint reductions (see config.mk).
Tweak Capstone and GLib to enable much smaller binary footprints.
windows: Fix dbghelp backtracer support for libffi-frames.
linux: Fix compatibility with new glibc versions.
linux: Only use one frida-helper when assets are installed.
qnx: Remove tempfiles when injector is closed.
core: Plug leak when agent teardown is cancelled.
gumjs: Fix handling of RPC invocations returning null.
interceptor: Use a “jumbo”-JMP on x86 when needed, when impossible to allocate
memory reachable from a “JMP ".
interceptor: Generate variable size x86 NOP padding.
stalker: Improve performance of the arm64 backend, by applying ideas recently
used to optimize the x86/64 backend – e.g. improved locality, better inline
caches, etc.
stalker: Fix handling of zero-sized freeze/thaw().
stalker: Rework x86 PLT exclusion code to avoid reentrancy-issues during
stalking.
stalker: Don’t require a C++ runtime to be present.
arm-writer: Add put_bl_reg(), put_call_reg().
arm-writer: Fix register clobbering in put_call_address*().
Introducing the brand new Swift bridge! Now that Swift has been
ABI-stable since version 5, this long-awaited bridge allows Frida to play nicely
with binaries written in Swift. Whether you consider Swift a static or a
dynamic language, one thing is for sure, it just got a lot more dynamic with
this Frida release.
Metadata
Probably the first thing a reverser does when they start reversing a binary is
getting to know the different data structures that the binary defines. So it
made most sense to start by building the Swift equivalent of the ObjC.classes
and ObjC.protocols APIs. But since Swift has other first-class types,
i.e. structs and enums, and since the Swift runtime doesn’t offer reflection
primitives, at least not in the sense that Objective-C does, it meant we had to
dig a little deeper.
Luckily for us, the Swift compiler emits metadata for each type
defined by the binary. This metadata is bundled in a
TargetTypeContextDescriptor C++ struct, defined in
include/swift/ABI/Metadata.h at the time of writing. This data structure
includes the type name, its fields, its methods (if applicable,) and other useful
data depending on the type at hand. These data structures are pointed to by
relative pointers (defined in include/swift/Basic/RelativePointer.h.) In
Mach-O binaries, these are stored in the __swift5_types section.
So to dump types, Frida basically iterates over these data structures and
parses them along the way, very similar to what dsdump does, except that you
don’t have to build the Swift compiler in order to tinker with it.
Frida also has the advantage of being able to probe into
internal Apple dylibs written in Swift, and that’s because we don’t need to
parse the dyld_shared_cache thanks to the private getsectiondata API, which
gives us section offsets hassle-free.
Once we have the metadata, we’re able to easily create JavaScript wrappers for
object instances and values of different types.
Conventions
To be on par with the Objective-C bridge, the Swift bridge has to support
calling Swift functions, which also proved to be not as straight forward.
Swift defines its own calling convention, swiftcall, which, to put it
succinctly, tries to be as efficient as possible. That means, not wasting load
and store instructions on structs that are smaller than 4 registers-worth of
size. That is, to pass those kinds of structs directly in registers. And since
that could quickly over-book our precious 8 argument registers
(on AARCH64 x0-x7), it doesn’t use the first register for the self
argument. It also defines an error register where callees can store errors
which they throw.
What we just described above is termed “physical lowering” in the Swift compiler
docs, and it’s implemented by the back-end, LLVM.
The process that precedes physical lowering is termed “semantic lowering,” which
is the compiler front-end figuring out who “owns” a value and whether
it’s direct or indirect. Some structs, even though they might be smaller than
4 registers, have to be passed indirectly, because, for example, they are
generic and thus their exact memory layout is not known at compile time, or
because they include a weak reference that has to be in-memory at all times.
We had to implement both semantic and physical lowering in order to be able
to call Swift functions. Physical lowering is implemented using JIT-compiled
adapter functions (thanks to the Arm64Writer API) that does the necessary
SystemV-swiftcall translation. Semantic lowering is implemented by utilizing
the type’s metadata to figure out whether we should pass a value directly or
not.
The compiler docs are a great resource to learn more about the calling
convention.
Interception
Because Swift passes structs directly in registers, there isn’t a 1-to-1 mapping
between registers and actual arguments.
And now that we have JavaScript wrappers for types, and are able to call Swift
functions from the JS runtime, a good next step would be extending Interceptor
to support Swift functions.
For functions that are not stripped, we use a simple regex to parse argument
types and names, same for return values. After parsing them we retrieve the
type metadata, figure out the type’s layout, then simply construct JS wrappers
for each argument, which we pass the Swift argument value, however many
registers it occupies.
EOF
Note that the bridge is still very early in development, and so:
Currently supports Darwin arm64(e) only.
Performance is not yet in tip-top shape, some edge case might not be handled
properly and some bugs are to be expected.
There’s a chance the API might change in breaking ways in the
short-to-medium term.
PRs and issues are very welcome!
Refer to the documentation for an up-to-date resource on the current API.
Enjoy!
Changes in 15.1.0
Implement the Swift bridge, which allows Frida to:
Explore Swift modules along with types implemented in them, i.e. classes,
structs, enums and protocols.
Create JavaScript wrappers for object instances and values.
Invoke functions that use the swiftcall calling convention from the
JavaScript runtime.
Intercept Swift functions and automatically parse their arguments and return
values.
Fix i/macOS regression where changes related to iOS 15 support ended up
breaking support for attaching to Apple system daemons.
gadget: Add interaction.parameters in connect mode. These parameters are then
“reflected” into app’s info under parameters.config. Thanks @mrmacete!
Changes in 15.1.1
gumjs: Fix Swift lifetime logic in the V8 runtime.
Changes in 15.1.2
control-service: Fix signal wiring, so signals such as Device.output get
emitted correctly by a remote frida-server. Thanks @mrmacete!
gadget: Fix the “runtime” option, which was forgotten during the refactorings
leading up to Frida 15.
relocator: Optimize handling of x86 RIP relative code, by simply adjusting the
offset where possible.
gumjs: Add ESM support, so tools like frida-compile can output better code.
gumjs: Throw away source code after parsing it.
gumjs: Plug leak when compiling to QuickJS bytecode.
objc: Fix the Proxy respondsToSelector implementation. Thanks @hot3eed!
gumjs: Fix V8 runtime crash when module is missing.
gumjs: Emit V8 exceptions thrown by ESM entrypoints.
Changes in 15.1.4
gumjs: Fix double-free related to weak ref callbacks in the QuickJS runtime.
Thanks @mrmacete!
gumjs: Ignore Interceptor context in unrelated NativeCallback invokes. In this
way invalid Interceptor contexts from higher up the call stack will be safely
ignored in favor of the minimal but correct callback context. Thanks
@mrmacete!
gumjs: Fix ESM module name normalization logic.
gumjs: Add Process getters for cwd, home, and tmp dirs.
swift: Improve metadata caching performance by ~3x. Thanks @hot3eed!
node: Publish Electron prebuilds for v15 instead of v13.
Changes in 15.1.5
gumjs: Fix crash when QuickJS stringifies large numbers. Thanks
@vfsfitvnm!
gumjs: Expose GError and GIConv to CModule. Thanks @0xDC00!
droidy: Support ADB server host/port environment variables. Thanks
@amirpeles90!
swift: Improve load behavior on non-Darwin.
Changes in 15.1.6
swift: Fix crash during load on non-Darwin. Thanks @hot3eed!
Changes in 15.1.7
swift: Fix CoreSymbolication integration on older OS versions. Thanks
@hot3eed!
python: Add setup.py download logic for Android/ARM. Our CI doesn’t yet build
and upload such a binary, though.
Changes in 15.1.8
darwin: Add support for working in the SRD environment. Thanks @Nessphoro!
darwin: Add support for building with newer iOS SDKs.
Changes in 15.1.9
x86-relocator: Fix patching of RIP relative instructions. This was a
regression introduced in 15.1.2, resulting in Stalker becoming unreliable.
portal-service: Always remove ClusterNode sessions whenever a session ID is
unset from PortalService. This avoids both NULL dereferences and leaks.
Thanks @mrmacete!
agent: Fix hang on unload w/ NO_REPLY_EXPECTED calls, where we would wait for
a reply to be sent. Due to the server-side DBus code being generated by the
Vala compiler, and it previously (in Frida <= 15.1.9) ignoring
NO_REPLY_EXPECTED, this bug went unnoticed.
android: Move to NDK r24 Beta 1.
Changes in 15.1.13
linux: Improve module resolution on glibc systems.
fruity: Fix spawn on dyld v4 case (jailed iOS 15.x). Thanks @mrmacete!
objc-api-resolver: Protect against objc_disposeClassPair() via mutex. Thanks
@mrmacete!
gumjs: Update Kernel.scan*() to match Memory.scan*(). Thanks @hot3eed!
stalker: Fix emitted branch op-code on x86.
stalker: Fix handling of Thumb IT AL.
stalker: Handle excluded Linux calls through PLT on x86.
stalker: Fix Linux exception handling on x86.
java: Add Java.backtrace(), without any API stability guarantees for now.
Changes in 15.1.14
backtracer: Improve fuzzy backtracers to also include the immediate caller,
and avoid walking past stack end when known.
windows: Implement Thread.try_get_ranges().
linux: Implement Thread.try_get_ranges().
ios: Check in with launchd on SRD systems.
stalker: Fix accidental clobbery in call depth code on x86.
So much has changed. Let’s kick things off with the big new feature that guided
most of the other changes in this release:
Portals
Part I: Conception
Earlier this year @insitusec and I were brainstorming ways we could simplify
distributed instrumentation use-cases. Essentially ship a Frida Gadget that’s
“hollow”, where application-specific instrumentation is provided by a backend.
One way one could implement this is by using the Socket.connect() JavaScript
API, and then define an application-specific signaling protocol over which the
code is loaded, before handing it off to the JavaScript runtime.
But this way of doing things does quickly end up with quite a bit of boring glue
code, and existing tools such as frida-trace won’t actually be usable in such a
setup.
That’s when @insitusec suggested that perhaps Frida’s Gadget could offer an
inverse counterpart to its Listen interaction. So instead of it being a
server that exposes a frida-server compatible interface, it could be configured
to act as a client that connects to a Portal.
Such a Portal then aggregates all of the connected gadgets, and also exposes a
frida-server compatible interface where all of them appear as processes. To the
outside it appears as if they’re processes on the same machine as where the
Portal is running: they all have unique process IDs if you use
enumerate_processes() or frida-ps, and one can attach() to them seamlessly.
In this way, existing Frida tools work exactly the same way – and by enabling
spawn-gating on the Portal, any Gadget connecting could be instructed to wait
for somebody to resume() it after applying the desired instrumentation. This
is the same way spawn-gating works in other situations.
Part II: Implementation
Implementing this was a lot of fun, and it wasn’t long until the first PoC was
up and running. It took some time before all the details were clear, though, but
this eventually crystallized into the following:
The Portal should expose two different interfaces:
The cluster interface that Gadgets can connect to, allowing them to join
the cluster.
Optionally also a control interface that controllers can talk to. E.g.
frida-trace -H my.portal.com -n Twitter -i open
To a user this would be pretty simple: just grab the frida-portal binary from
our releases, and run it on some machine that the Gadget is able to
reach. Then point tools at that – as if it was a regular frida-server.
That is however only one part of the story – how it would be used for simple
use-cases. The frida-portal CLI program is actually nothing more than a thin CLI
wrapper around the underlying PortalService. This CLI program is just a bit
north of 200 lines of code, of which very little is actual logic.
One can also use our frida-core language bindings, for e.g. Python or Node.js,
to instantiate the PortalService. This allows configuring it to not provide
any control interface, and instead access its device property. This is a
standard Frida Device object, on which one can enumerate_processes(), attach(),
etc. Or one can do both at the same time.
Using the API also offers other features, but we will get back to those.
Part III: TLS
Given how useful it might be to run a frida-portal on the public Internet, it
was also clear that we should support TLS. As we already had glib-networking
among our dependencies for other features, this made it really cheap to add,
footprint-wise.
And implementation-wise it’s a tiny bit of logic on the client side, and
similarly straight-forward for the server side of the story.
For the CLI tools it’s only a matter of passing --certificate=/path/to/pem.
If it’s a server it expects a PEM-encoded file with a public + private key,
where it will accept any certificate from incoming clients. For a client it’s
also expecting a PEM-encoded file, but only with the public key of a trusted CA,
which the server’s certificate must match or be derived from.
The next fairly obvious feature that goes hand in hand with running a
frida-portal on the public Internet, is authentication. In this case our server
CLI programs now support --token=secret, and so do our CLI tools.
But this gets a lot more interesting if you instantiate the PortalService
through the API, as it makes it easy to plug in your own custom authentication
backend:
importfridadefauthenticate(token):# Where `token` might be an OAuth access token
# that is used to grab user details from e.g.
# GitHub, Twitter, etc.
user=…# Attach some application-specific state to the connection.
return{'name':user.name,}cluster_params=frida.EndpointParameters(authentication=('token',"wow-such-secret"))control_params=frida.EndpointParameters(authentication=('callback',authenticate))service=frida.PortalService(cluster_params,control_params)
The EndpointParameters constructor also supports other options such as
address, port, certificate, etc.
Part V: Offline Mode
That leads us to our next challenge, which is how to deal with transient
connectivity issues. I did make sure to implement automatic reconnect logic in
PortalClient, which is what Gadget uses to connect to the PortalService.
But even if the Gadget reconnects to the Portal, what should happen to loaded
scripts in the meantime? And what if the controller gets disconnected from the
Portal?
We now have a solution that handles both situations. But it’s opt-in, so the old
behavior is still the default.
Now, once some connectivity glitch occurs, scripts will stay loaded on the
remote end, but any messages emitted will get queued. In the example above, the
client has 30 seconds to reconnect before scripts get unloaded and data is lost.
The controller would then subscribe to the Session.detached signal to be able
to handle this situation:
Once session.resume() succeeds, any buffered messages will be delivered and
life is good again.
The above example does gloss over a few details such as our current Python
bindings’ finicky threading constraints, but have a look at the full example
here. (This will become a lot simpler once we port our Python bindings off
our synchronous APIs and onto async/await.)
Part VI: Latency and Bottlenecks
Alright, so next up we’ve got a Portal running in a data center in the US, but
the Gadget is at my friend’s place in Spain, and I’m trying to control it from
Norway using frida-trace. It would be a shame if the script messages coming from
Spain would have to cross the Atlantic twice, not just because of the latency,
but also the AWS bill I’ll have to pay next month. Because I’m dumping memory
right now, and that’s quite a bit of traffic right there.
This one’s a bit harder, but thanks to libnice, a lightweight and mature ICE
implementation built on GLib, we can go ahead and use that. Given that GLib
is already part of our stack – as it’s our standard library for C programming
(and our Vala code compiles to C code that depends on GLib) – it’s a perfect
fit. And this is very good news footprint-wise.
As a user it’s only a matter of passing --p2p along with a STUN server:
$ frida-trace \-H my.portal.com \--p2p\--stun-server=my.stunserver.com \-n Twitter \-i open
You may have noticed that our Gadget has been a recurring theme so far. I’m not
very excited about adding features that only apply to one mode, such as
only Injected mode but not Embedded mode. So this was something that came to
mind quite early on, that Portals had to be a universally available feature.
So say my buddy is reversing a target on his iPhone from his living room in
Italy, and I’d like to join in on the fun, he can go ahead and run:
Something I’ve been wanting to build since before Frida was born, is an online
collaborative reversing app. Back in the very beginning of Frida, I built a
desktop GUI that had integrated chat, console, etc. My not-so-ample spare-time
was a challenge, however, so I eventually got rid of the GUI code and decided to
focus on the API instead.
Now we’re in 2021, and single-page apps (SPAs) can be a really appealing option
in many cases. I’ve also noticed that there’s been quite a few SPAs built on top
of Frida, and that’s super-exciting! But what I’ve noticed when toying with SPAs
on my own, is that it’s quite tedious to have to write the middleware.
Well, with Frida 15 I had to make some protocol changes to accomodate the
features that I’ve covered so far, so it also seemed like the right time to
really break the protocol and go ahead with a major-bump. This is something
I’ve been trying to avoid for a long time, as I know how painful they are to
everyone, myself included.
So now browsers can finally join in on the fun, without any middleware needed:
asyncfunctionstart(){constws=wrapEventStream(newWebSocket(`ws://${location.host}/ws`));constbus=dbus.peerBus(ws,{authMethods:[],});consthostSessionObj=awaitbus.getProxyObject('re.frida.HostSession15','/re/frida/HostSession');consthostSession=hostSessionObj.getInterface('re.frida.HostSession15');constprocesses:HostProcessInfo[]=awaithostSession.enumerateProcesses({});console.log('Got processes:',processes);consttarget=processes.find(([,name])=>name==='hello2');if(target===undefined){thrownewError('Target process not found');}const[pid]=target;console.log('Got PID:',pid);constsessionId=awaithostSession.attach(pid,{'persist-timeout':newVariant('u',30)});…}
This means that Frida’s network protocol is now WebSocket-based, so browsers can
finally talk directly to a running Portal/frida-server, without any middleware
or gateways in between.
I didn’t want this to be a half-baked story though, so I made sure that the
peer-to-peer implementation is built on WebRTC data channels – this way
even browsers can communicate with minimal latency and help keep the AWS bill
low.
Part IX: Assets
Once we’ve built a web app to go with our Portal, which is speaking WebSocket
natively, and thus also HTTP, we can also make it super-easy to serve that SPA
from the same server:
A natural next step once we have a controller, say a web app, is that we might
want collaboration features where multiple running instances of that SPA are
able to communicate with each other.
Given that we already have a TCP connection between the controller and the
PortalService, it’s practically free to also let the developer use that channel.
For many use-cases, needing an additional signaling channel brings a lot of
complexity that could be avoided.
This is where the new Bus API comes into play:
importfridadefon_message(message,data):# TODO: Handle incoming message.
passmanager=frida.get_device_manager()device=manager.add_remote_device("my.portal.com")bus=device.busbus.on('message',on_message)bus.attach()bus.post({'type':'rename','address':"0x1234",'name':"EncryptPacket"})bus.post({'type':'chat','text':"Hey, check out EncryptPacket everybody"})
Here we’re first attaching a message handler so we can receive messages from the
Portal.
Then we’re calling attach() so that the Portal knows we’re interested
in communicating with it. (We wouldn’t want it sending messages to controllers
that don’t make use of the Bus, such as frida-trace.)
Finally, we post() two different message types. It is up to the PortalService
to decide what to do with them.
So this means that the remote PortalService needs to be instantiated through the
API, as incoming messages need to be handled – the Portal won’t forward them to
other controllers on its own.
This means any controller connection tagged with #reversing will receive that
message. Tagging is done like this:
service.tag(connection_id,"#reversing")
Such tags could then be added based on actions, like a controller sending a
“join” message to join a channel. They could also be applied based on
authentication, so that only connections belonging to a certain GitHub
organization receive that message – just as an example.
Lastly, on the cluster side, it is also possible to specify an Access Control
List (ACL) when joining the Portal. The ACL is an array of strings that specify
tags which will grant controllers access to discover and interact with the given
process. This means that service.tag() needs to be used for each controller
that should be granted access to a certain node/group of nodes.
Back in May I had a chat with @Hexploitable, who was working on a tool
where he needed to pick a Device object based on whether it’s running iOS vs
Android. This is a feature that’s been requested in the past, and it felt like
it might be time to finally address it.
While one could do device.attach(0) and load a script in the system session, in
order to run code inside Frida itself (e.g. in a remote frida-server), it is
somewhat tedious. It also doesn’t work if the Device represents a
jailed/non-rooted device, where code execution is a lot more constrained.
So after brainstorming this a bit, @Hexploitable started working on implementing
it, and quickly got to the point where he had the first draft working. This was
later refined by me, and got merged shortly after the Portals feature had
finally landed.
The API is simple, and easy to extend in the future:
An important detail to note here is access: 'jailed'. This is how you can
determine whether you’re accessing the device through our support for jailed
iOS/Android systems, i.e. limited to debuggable apps, or actually talking to
a remote frida-server – which is what access: 'full' means.
Things are not quite as juicy for Android yet (PRs welcome, btw!), but there are
still plenty of useful details:
We’re also able to identify the specific Linux distro if it’s LSB-compliant:
And last but not least, Windows:
Application and Process Parameters
Another cool idea that started taking shape after some impromptu chats, was when
@pancake told me it would be useful to know the particular version of an
installed iOS app.
As I had just broken the protocol in so many ways working on the Portals
feature, it also seemed like a great time to break it some more, and avoid
another painful major bump down the road.
Fast forward a bit, and here’s how it turned out: Our Application and
Process objects no longer have any small_icon or large_icon properties,
but they now have a parameters dict.
By default, with enumerate_applications(), things look familiar:
But by changing that to enumerate_applications(scope='metadata'), things get a
lot more interesting:
Here we can see the iOS Twitter app’s version and build number, where its app
bundle is on the filesystem, the containers that it owns, that it is currently
the frontmost app, how long ago it was started, etc.
We can also crank that up to enumerate_applications(scope='full') and get
icons as well:
The debuggable: true parameter is very useful if query_system_parameters()
reported access: 'jailed', as that means your application may want to filter
the list of apps to only show the ones it is able to spawn() and/or attach() to,
or perhaps show debuggable apps more prominently to provide a better UX.
It’s probably also worth mentioning that get_frontmost_application() now
supports passing a scope as well.
Those of you familiar with the old API may have noticed that icons may now be
delivered in compressed form, as PNGs. Previously this was always uncompressed
RGBA data, and the iOS side would do the PNG decoding and downscaling to two
fixed resolutions (16x16 and 32x32).
All of this meant that we would waste a lot of CPU time, memory and bandwidth to
include icons, even if all of that data would end up in a CLI tool that doesn’t
make use of it. So now with Frida 15 you might notice that application and
process listing is a lot faster. And even if you do request icons, it should
also be faster than before as we don’t do any decompression and downscaling.
That was application listing. All of the above is also true for process listing,
and this is what enumerate_applications(scope='full') might look like now:
Here it is also clear that the Twitter app is currently frontmost, that its
parent PID is launchd (PID 1), the user it is running as, when it was started,
etc.
You might be wondering why applications is an array though, and the answer is
probably best illustrated by an example from Android:
The “com.android.phone” process actually hosts six different “applications”!
And once again, last but not least, I didn’t forget about Windows:
So that’s the “scope” option. There’s also another one, meant for UIs. The idea
is that a UI might want to grab the list of applications/processes quickly, and
may not actually need metadata/icons until the user interacts with a particular
entry, or scrolls a subset of entries into view. So we now provide an option to
support such use-cases.
Say we only want to grab the metadata for two specific apps, we can now do:
Now that we have covered application parameters and portals, there’s an
important detail that’s worth mentioning: Given that it doesn’t make much sense
to implement query_system_parameters() in the case of a PortalService, as it’s
surfacing processes from any number of (potentially remote) systems, we can use
application/process parameters to fill this void.
This means that any Application and Process coming from a PortalService will,
if scope is set to metadata or full, provide one parameter named system,
which contains the system parameters for that particular application/process.
This way an application can still know ahead of time if it’s interested in a
particular process.
Jailed iOS and Android Improvements
I had a lot of fun implementing the Application and Process parameters feature,
and tried to see how narrow I could make the gap between jailed (non-rooted) and
jailbroken (rooted). For example on Android, we didn’t even fetch app labels in
the non-rooted code-path. This was because we were relying on running shell
commands over ADB, and I couldn’t find a way to grab labels in that case.
The shell command route is very fragile, as most tools output details in a
format that’s meant to be consumed by a human, not a machine. And obviously
such output is likely to change as Android evolves.
Because of this we now have a tiny prebuilt .dex that we copy over and run, and
grabbing metadata is only a matter of making RPC calls to that helper process.
This means we are able to provide all the same details for non-rooted as we
provide in the rooted case, where we have a frida-server running on the Android
side.
Another thing worth mentioning is that we no longer consider Android’s launcher
a frontmost app, which means this is now consistent with our behavior on iOS,
where SpringBoard is never considered the frontmost app.
As part of these major changes I also added code to fetch icons on Android as
well, both non-rooted and rooted, so that this feature is no longer just limited
to iOS, macOS, and Windows.
We didn’t provide icons for jailed iOS though, but that feature gap is now also
closed. There is however still one difference between jailed and jailbroken iOS:
the ppid and user parameters are not available in the jailed case, as this
is not exposed by any lockdown/DTX API that I’m currently aware of. But other
than that, things are in pretty good shape.
Massively improved backtraces on i/macOS
Thanks to a very exciting pull-request by @hot3eed, we now have an i/macOS
symbolication fallback that uses the Objective-C runtime. In this way, instead
of showing module!0x1234, we may be able to resolve that to an Objective-C
method. Yay!
We also got another awesome contribution by @mrmacete, where NativeCallback
now always exposes a context, so you can do Thread.backtrace(this.context) and
expect it to work in all cases.
This was previously only possible when NativeCallback was used as an Interceptor
replacement. So if you were using ObjC.implement() to swizzle an Objective-C
API, you couldn’t actually capture a backtrace from that NativeCallback. So this
is a super-exciting improvement!
Unextracted Native Libraries on Android
For those of you using Frida on Android, you may have encountered apps where
native libraries don’t reside on the filesystem, but are loaded directly from
the app’s .apk. Thanks to a great contribution by @P-Sc, we now support this
transparently – no changes needed in your existing instrumentation code.
Upgraded OS Support
We now also support the latest betas of macOS Monterey, iOS 15, and Android 12.
Special thanks to @alexhude at Corellium for helping debug and test
things on iOS 15, and @pengzhangdev who contributed a fix for
frida-java-bridge to support Android 12.
Networked iOS Devices
Another feature that’s been requested a few times is support for networked iOS
devices. This is great if you don’t want to destroy your iPhone/iPad’s battery
by leaving it plugged in all day. What’s great about this feature is that it
“just works” – you should see them if you run frida-ls-devices.
Only two pitfalls worth mentioning: You may now have two different Device
objects with the same ID, in case a networked iOS device is reachable through
the network while also being plugged in.
E.g.:
$ frida-ls-devices
Id Type Name
--------------------------------------------------------------------local local Local System
00008027-xxxxxxxxxxxxxxxx usb iPad
socket remote Local Socket
00008027-xxxxxxxxxxxxxxxx remote iOS Device [fe80::146f:75af:d79:630c]
So if you’re using -U or frida.get_usb_device() things will work just like
before, where you’ll be using your device through USB. But if you want to use
the networked device, then resolving it by ID means the USB entry will take
precedence, as it’s typically ahead of the networked device in the list of
devices.
This means you would also need to check its type. Our CLI tools don’t
yet provide a switch to do this, but this would be a welcome pull-request if
anyone’s interested!
The second pitfall is that frida-server only listens on the loopback interface
by default, meaning we won’t be able to connect to it over the network. So if
you’re using our iOS .deb either manually or through Cydia, you will have to
edit /Library/LaunchDaemons/re.frida.server.plist to add the --listen
switch, and then use launchctl to restart it.
This may also be a situation where you want to make use of the new TLS and
authentication features mentioned earlier, depending on how much you trust your
network environment.
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changes in 15.0.0
Introduce PortalService API and daemon, a network service that
orchestrates a cluster of remote processes instrumented by Frida.
Implements both a frida-server compatible control interface, as well
as a cluster interface that agents and gadgets in target processes can
talk to. Connected controllers can enumerate processes as if they were
local to the system where the portal is running, and are able to
attach() and also enable spawn-gating to apply early instrumentation.
Add Session.join_portal(), making it easy to share control of a
process with a remote PortalService, joining its cluster together with
other nodes.
Add “connect” interaction to frida-gadget, so it can join a
PortalService cluster as well.
Add PortalClient, used to implement Session.join_portal() and
frida-gadget’s “connect” interaction. Connects to the PortalService
and joins its cluster. Implements automatic reconnect in case of
transient failures. Also supports specifying an ACL, which is a list
of tags that the PortalService must require connected controllers to
possess at least one of. It’s up to the application to implement
tagging of controllers based on e.g. authentication.
Add Device.bus API to allow clients connected to a PortalService to
exchange application-specific messages with it. Requires instantiating
the service using the API in order to wire up message handlers and
protocol logic.
Add Session persistence support, enabled by specifying a non-zero
“persist_timeout” option when attach()ing to a process. When the
server subsequently detects that the client owning the session got
disconnected, it will allow scripts to stay loaded until the timeout
(in seconds) is reached. Any script and debugger messages emitted in
the meantime are queued, and may later be delivered if the client
returns before the timeout is reached.
Add TLS support, enabled by specifying a certificate. On the server
end this is a PEM with a public and private key, where the server
will accept any certificate from the client’s side. However for the
client this is a PEM with the public key of a trusted CA, which the
server’s certificate must match or be derived from.
Add authentication support, enabled by specifying a token. The daemons
allow specifying a static token through a CLI option, and the APIs
allow plugging in a custom authentication backend – which means the
token can be interpreted as desired.
Move network protocols to WebSocket.
Add protocol-level keepalives.
Implement WebRTC Data Channel compatible peer-to-peer support, enabled
by calling setup_peer_connection() on Session. This allows a direct
connection to be established between the client and the remote
process, which is useful when talking to it through e.g. a Portal.
Optimize protocol by skipping the DBus authentication handshake and
telling GDBus not to fetch properties, saving an additional roundtrip.
Drop deprecated protocol bits, such as Session.enable_jit().
Improve the application and process query APIs. (Covered extensively above.)
Switch Crash parameter names to kebab-case.
Add Session.is_detached(), useful in multi-threaded scenarios where the
“detached” signal may already have been emitted by the time we manage to
connect to it.
Fix Stalker handling of SYSCALL instructions on Linux/x86.
Fix the iPad device name on macOS.
Massively improve backtraces/symbolication on i/macOS in cases where symbols
are missing, but the address to be symbolicated belongs to an Objective-C
method. Thanks @hot3eed!
Improve backtracer accuracy and flexibility, now exposing a minimal context to
NativeCallback in cases where it’s not used as an Interceptor replacement. One
such example is ObjC.implement(), used for swizzling APIs. Thanks
@mrmacete!
Improve Interceptor reliability on macOS/arm64, by switching to the mapping
strategy that we use on iOS.
Add support for network-connected iOS devices.
Avoid leaving behind a file when sandbox check fails on iOS.
Fix Stalker on newer iOS hardware jailbroken with checkra1n. This was solved
by disabling RWX support on iOS for now: Even if the jailbreak appears to make
it available, whether it actually works boils down to which mitigations the
hardware supports. Shout-out to @stacksmashing for reporting and helping
get to the bottom of this one!
Remove bashisms from iOS maintainer scripts, for improved jailbreak
compatibility. Thanks @nyuszika7h!
Improve Interceptor frame layout on arm64, so backtracing code is able to walk
the stack past our generated code. This also makes it easier to use a debugger
together with Interceptor.
Fix ObjC ApiResolver deadlock, which occurred when free() was resolved lazily
from a dyld image callback, at which point it is a bad idea to call dlsym().
Add support for unextracted native libraries on Android. Thanks @P-Sc!
Fix Android get_frontmost_application() name truncation.
Don’t consider the Android launcher a frontmost app.
Use the Android app’s label as the process name if the process represents is
its main UI process. This is finally consistent with what we do on iOS.
Improve jailed Android injector: Now using a long-lived shell session to speed
things up. Also ensure filenames dropped into /data/local/tmp are unique, and
clean up temporary files.
Drop Firefox OS support.
Rename the weak ref API to avoid clashing with ES2021. So instead of
WeakRef.bind() and WeakRef.unbind(), these are now Script.bindWeak() and
Script.unbindWeak().
Massively improve memory allocation performance on Windows, by lowering the
dlmalloc spin-lock sleep duration to zero – which means it will only yield
the remainder of its time slice. The default of 50 ms is prone to introduce
significant delay as soon as threads start competing for the lock.
Lazily create the ScriptScheduler thread pool. This means anyone using GumJS
can avoid background threads until they’re really needed. Very useful if
you’re writing a tool or agent that needs to handle fork(), without having to
implement logic to stop and later restart threads. (Something frida-agent
does, but which isn’t necessarily needed for simple use-cases.)
Java: Add support for Android 12 beta. Thanks @pengzhangdev!
Java: Fix Java.array() for unloaded array types: If the type of the array was
not used in the application it means that it wasn’t loaded into memory, and
Java.array() previously failed because of this. Thanks @yotamN!
Java: Add toString() to primitive arrays, so that instead of the generic
“[Object Object]” string it will generate a string where the array values are
separated by commas. Thanks @yotamN!
CModule: Add missing TinyCC builtins for 32-bit x86.
python: Add Script.is_destroyed property.
python: Add Session.is_detached property.
python: Add Device.is_lost property.
python: Throw when attempting an RPC call on a destroyed script.
node: Fix compatibility with newer versions of Node.js, where any given
Buffer’s backing store needs to be unique. We solve this by simply making a
copy in cases where we cannot guarantee that the same buffer can only be
observed once.
node: Fix use-after-free in signal transform callbacks.
node: Fix use-after-free in signal connection callbacks.
node: Move to C++17, for compatibility with newer Node.js headers.
node: Add Script.isDestroyed property.
node: Add Device.isLost property.
Changes in 15.0.1
Ensure DarwinGrafter’s merging of binds doesn’t make gaps in __LINKEDIT.
Not doing so triggers a bug in codesign for which the resulting signed
binary turns out corrupted. Thanks @mrmacete!
node: Fix compilation error when building with MSVC.
Changes in 15.0.2
Fix handling of large messages, for both client-server and p2p. Also bump the
WebSocket payload size limit to 256 KiB - same as is typically negotiated for
data channels in p2p mode.
Move WebSocket I/O to the DBus thread, to avoid unnecessary thread hopping.
Plug leaks when using p2p.
Changes in 15.0.3
Implement a new frida-pipe strategy for i/macOS. Turns out that our previous
strategy of directly setting up a Mach port in the target process becomes
problematic with guarded Mach ports. So instead we register a Mach service
that’s globally visible, and have the target process contact it to fetch its
end of the socketpair. We also check with the sandbox up front, and issue an
extension token if needed. However, if we’re unable to register the Mach
service with launchd, we fall back to our previous strategy.
Skip iOS platformized detection on iOS >= 15. It interacts badly with guarded
Mach ports.
Port early instrumentation to macOS 12 and iOS 15.
Gracefully handle agent failing to start. Instead of crashing the target
process, simply log the error and unload.
Linux: Use an abstract name for frida-pipe when supported.
Unlink UNIX socket when frida-pipe is done with it.
Fix iOS policyd Mach message lifetime logic.
Changes in 15.0.4
Fix the i/macOS injector’s data size logic. It’s been hard-coded since the
beginning, and the recent entrypoint data size adjustment broke it on systems
with 4K pages.
Fix i/macOS early instrumentation regression on dyld < 4.
Changes in 15.0.5
Fix the __CFInitialize() code-path on dyld >= 4.
Fix i/macOS sandbox extension logic during spawn().
node: Fix the ApplicationParameters typings. Thanks for reporting,
@pancake!
Changes in 15.0.8
iOS: Add support for unc0ver v6.1.2.
iOS: Update Substrate interop logic to support 0.9.7113.
Changes in 15.0.9
iOS: Revive support for older OS versions. (Verified on iOS 10.3.)
iOS: Fix support for older Apple usbmuxd versions.
Android: Handle devices where jailed is unsupported.
Fix DarwinGrafter alignment issue, aligning to 16 bytes also when lazy
binds follow regular binds. Thanks @mrmacete!
Changes in 15.0.10
Fix regression where Device.open_channel(“lockdown:”) ended up closing the
stream right away.
Fix crash when talking to older versions of ADB.
Changes in 15.0.11
Rewrite macOS spawn gating to use DTrace. This means we’ve now dropped support
for our kernel extension, and we don’t need to worry about future OSes no
longer supporting extensions. It also means we finally support spawn gating on
Apple Silicon as well.
Work around i/macOS arm64 single-step delay during early instrumentation.
Changes in 15.0.12
Fix macOS spawn gating task port lifetime issue. Should not try to be clever
and keep task ports around – bad things happen if a task port is used after an
exec transition.
Remove the i/macOS task port caching logic. It is dangerous in exec
transitions, adds some complexity, and doesn’t help all that much
performance-wise, anyway.
Make the macOS spawn gating DTrace predicate environment variable optional.
Improve the macOS spawn gating error message.
Changes in 15.0.13
Improve clients to specify Host header and use TLS SNI.
Revert i/macOS single-step delay workarounds.
iOS: Fix usbmux port number encoding in the connect request.
Python, Node.js: Fix ownership in Device.spawn() aux options logic.
Changes in 15.0.14
Port iOS crash reporter integration to iOS 14.7.1.
Configure internal agents to be less intrusive on i/macOS.
Improve i/macOS error-handling during process preparation.
Revive i/macOS single-step delay workarounds, which turned out to be needed
after all.
Handle reentrancy when about to yield JS lock, which may happen if a replaced
function gets called by Interceptor during end_transaction().
Fix conditional Interceptor unignore logic in GumJS. This was preventing
Interceptor from ignoring internal calls, and resulted in noise and reduced
performance.
Enhance the i/macOS DebugSymbol fallback name to also include the unslid
address. This makes it easy to plop it into a static analysis tool.
Fix Stalker code slab refill logic.
Add Stalker stats interface.
Changes in 15.0.15
Rework i/macOS Exceptor to support latest iOS 14. This would previously result
in a deadlock whenever a native exception occurred.
Changes in 15.0.16
Fix i/macOS single-step handling on ARM during early instrumentation, which
would result in attach() failing randomly for a freshly spawn()ed process.
Thanks @mrmacete!
Add Stalker backpatch prefetching support.
Make Stalker inline cache size configurable on x86.
Optimize Stalker x86 return handling.
ObjC: Allow proxies to implement methods. Thanks @hot3eed!
Changes in 15.0.17
gadget: Support packaging as framework on i/macOS. Load config from
“Resources/config.json”, and resolve relative paths relative to the same
directory. As an added bonus, we now also support specifying relative paths
for “certificate” and “asset_root”.
web-service: Implement basic directory listing with NGINX-style output. This
is useful with e.g. “frida-server –asset-root=/”.
stalker: Fix backpatch args for 32-bit x86.
Changes in 15.0.18
Plug long-standing memory leaks, both in our internal heap’s realloc behavior
being misconfigured and causing leaks, and in how we register JavaScript
classes with QuickJS. Kudos to @mrmacete for discovering and helping track
down these long-standing bugs!
Changes in 15.0.19
gadget: Fix framework resource lookup logic on iOS.
So much to talk about. Let’s kick things off with a big new feature:
Realms
Frida has supported Android for quite a while, but one particular feature has
kept getting requested (mostly) by users who thought they were looking at a bug.
The conversation usually started something like: “I’m using Frida inside the
hardware-accelerated Android emulator X, and when I attach to this process Y,
Process.enumerateModules() is missing JNI library Z. But I can see it in
Process.enumerateRanges() and /proc/$pid/maps. How come?”
As you may have guessed, we’re talking about Android’s NativeBridge, typically
used on Intel-powered Android devices to enable them to run apps that only
support ARM – i.e. apps with one or more JNI components only built for ARM.
In a Frida context, however, we’re usually talking about a VirtualBox-based
emulator that runs an Android system built for x86. This system then ships with
NativeBridge support powered by libhoudini, a proprietary ARM translator.
There’s quite a few of these emulators, e.g. BlueStacks, LDPlayer, NoxPlayer,
etc. While the ones mentioned are optimized for running games, there’s now also
Google’s official Android 11 AVDs which ship with NativeBridge support out of
the gate.
Through the years I’ve been thinking about how we could support such scenarios
in Frida, but thinking about it always made my head hurt a little. It did feel
like something we should support at some point, though, I just had a hard time
figuring out what the API would look like.
Then along came 2020 and Apple announced their transition to ARM, and suddenly
Rosetta became relevant once again. “Alright”, I thought, “now we have two
platforms where it would be useful to support processes containing an emulated
realm that’s running legacy code.”
And yeah there’s also Windows, but we don’t yet support Windows on ARM. We
totally should though, so if somebody’s interested in taking a stab at this
then please do get in touch.
Anyway, I’m exited to announce that our Android binaries for x86 and x86_64
now support such processes out of the box. You may already be familiar with
the following frida-core API, where the Python flavor looks like this:
session=device.attach(target)
(Or frida.attach() if your code only deals with the local system.)
If target has an emulated realm, you can now do:
session=device.attach(target,realm='emulated')
The default is realm='native', and you can actually use both realms at the
same time. And when using our CLI tools, pass --realm=emulated to act on the
emulated realm.
One important caveat when using this on Android is that you will need to apply
your Java-level instrumentation in the native realm.
Lastly it’s worth noting that this new feature is only supported on Android for
now, but it shouldn’t be hard to support Rosetta on macOS down the road.
Definitely get in touch if you want to help out with this.
Taking Android Java Hooking Inline
The way Frida’s Java bridge replaces Java methods on Android has up until
now been accomplished by mutating the in-memory method metadata so that the
target method becomes native – if it wasn’t already. This allows us to install
a NativeCallback that matches the given method’s JNI signature.
This has presented some challenges, as the ART runtime does have other internal
state that depends on the given method’s personality. We have devised a few
hacks to dance around some of these issues, but some particularly gnarly
edge-cases remained unsolved. One such example is JIT profiling data maintained
by the ART VM.
An idea I had been thinking about for a while was to stop mutating the method
metadata, and instead perform inline hooking of the AOT-generated machine code –
for non-native methods that is. That still leaves methods run on the VM’s
interpreter, but the assumption was that we could deal with those by hooking
VM internals.
I took a stab at an early prototype to explore this approach further. It seemed
like it could work, but there were still many challenges to work through. After
some brainstorming with @muhzii, he kept working on evolving this rough PoC
further in his spare time. Then one day I almost fell off my chair out of pure
excitement when I saw the amazing pull-request he had just opened.
Thanks to Muhammed’s amazing work, you can now all enjoy a much improved Java
instrumentation experience on Android. This means improved stability and also
that direct calls won’t bypass your replacement method. Yay!
Deoptimization
For those of you using Java.deoptimizeEverything() on Android to ensure that
your hooks aren’t skipped due to optimizations, there’s now a more granular
alternative. Thanks to @alkalinesec’s neat contribution to our Java bridge,
you can now use Java.deoptimizeBootImage(). It ensures only code in the boot
image OAT files gets deoptimized. This is a serious performance gain in some
situations where the app code itself is slow when deoptimized, and it is not
necessary to deoptimize it in order for hooks to be hit reliably.
CModule
Another really exciting update here. The next hero in our story is @mephi42,
who started porting Frida to S390x. Our CModule implementation relies on TinyCC
behind the scenes, and it doesn’t yet support this architecture. The system
might have a C compiler though, so @mephi42 proposed that we add support for
using GCC on systems where TinyCC cannot help us out.
I really liked this idea. Not only from the perspective of architecture support,
but also because of the potential for much faster code – TinyCC optimizes for
small compiler footprint and fast compilation, not fast code.
So needless to say I got more and more excited with each pull-request towards
GCC support. Once the last one landed it inspired me to add support for using
Apple’s clang on i/macOS.
Where toolchain is either any, internal, or external. The default is
any, which means we will use TinyCC if it supports your Process.arch, and
fall back to external otherwise.
The story doesn’t end here, though. While implementing support for i/macOS,
it wasn’t really clear to me how we could fuse in symbols provided by the
JavaScript side. (The second argument to CModule’s constructor.)
The GCC implementation uses a linker script, which is a really elegant solution
that Apple’s linker doesn’t support. But then it hit me: we already have our own
dynamic linker that we use for our injector.
Once I had wired that up, it seemed really obvious that we could also trivially
support skipping Clang entirely, and allow the user to pass in a precompiled
shared library.
The thinking there was that it would enable cross-compilation, but also make it
possible to implement a CModule in languages such as Swift and Rust: basically
anything that can interop with C.
So this means we now also support the following:
constcm=newCModule(blob);
Where blob is an ArrayBuffer containing the shared library to construct it
from. For now this part is only implemented on i/macOS, but the goal is to
support this on all platforms. (Contributions welcome!)
Also, as of frida-tools 9.2, the REPL’s -C switch also supports this, making
it easy to use an external toolchain without missing out on live-reload – which
makes for a much shorter feedback loop during development.
Taking that one step further, the CModule API now also provides a the property
CModule.builtins, which scaffolding tools can use to obtain the built-in
headers and preprocessor defines.
And on that note we now have such a tool in frida-tools:
$ mkdir pewpew
$ cd pewpew
$ frida-create cmodule
Created ./meson.build
Created ./pewpew.c
Created ./.gitignore
Created ./include/glib.h
Created ./include/gum/gumstalker.h
Created ./include/gum/gumprocess.h
Created ./include/gum/gummetalarray.h
Created ./include/gum/guminterceptor.h
Created ./include/gum/gumspinlock.h
Created ./include/gum/gummetalhash.h
Created ./include/gum/gummemory.h
Created ./include/gum/gumdefs.h
Created ./include/gum/gummodulemap.h
Created ./include/json-glib/json-glib.h
Created ./include/gum/arch-x86/gumx86writer.h
Created ./include/capstone.h
Created ./include/x86.h
Created ./include/platform.h
Run `meson build && ninja -C build` to build, then:
- Inject CModule using the REPL: frida Calculator -C ./build/pewpew.dylib
- Edit *.c, and build incrementally through `ninja -C build`
- REPL will live-reload whenever ./build/pewpew.dylib changes on disk
$ meson build && ninja -C build
…
[2/2] Linking target pewpew.dylib
$ frida Calculator -C ./build/pewpew.dylib
…
init()[Local::Calculator]->
And yes, it live-reloads! Taken to the extreme you could use a file-watcher tool
and make it run ninja -C build whenever pewpew.c changes – then just save
and instantly see the instrumentation go live in the target process.
It’s worth noting that you can also use the above when using the internal
CModule toolchain, as having the headers available on disk is handy for editor
features such as code completion.
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changes in 14.2.0
Brand new realms API for instrumenting emulated realms inside native
processes. Only implemented on Android for now.
Add –disable-preload/-P to frida-server. Useful in case of OS compatibility
issues where Frida crashes certain OS processes when attaching to them.
Fix libc detection on older versions of Android.
Fix crash when resolving export of the vDSO on Android. Thanks @ant9000!
Restore support for libhoudini on Android.
Fix ARM cache flushing on Android 11’s translator.
Fix linker offsets for Android 5.x. Thanks @muhzii!
Start refactoring CModule’s internals to prepare for multiple backends. Thanks
@mephi42!
Fix CModule aggregate initializations on ARM.
Fix ModuleApiResolver fast-path emitting bad matches.
Changes in 14.2.1
Fix CModule constructor error-path in the V8 runtime.
Use V8 runtime for the “system_server” agent on Android.
Changes in 14.2.2
Fix Darwin.Mapper arm64e handling of pages without fixups. This went unnoticed
out of pure “luck”, until our binaries eventually mutated sufficiently to
expose this bug.
Changes in 14.2.3
Upgrade to using inline hooking for the ART runtime. Thanks @muhzii!
Fix direct transport regression on i/macOS, introduced by GLib upgrade where
GLib.Socket gained GLib.Credentials support on Apple OSes. A typical symptom
of this regression is that frida-server gets killed by Jetsam.
Fix libffi support for stdcall, thiscall, and fastcall on 32-bit Windows.
Extend Memory.alloc() to support allocating near a given address. Thanks
@muhzii!
Fix relocation of RIP-relative indirect branches on x86_64. Thanks
@dkw72n!
Improve the JVM C++ allocator API probing logic by consulting debug symbols
before giving up. Thanks @Happyholic1203!
Upgrade SELinux libraries to support bleeding edge Android systems.
Add gum-linux-x86_64-gir target for GIR generation. Thanks @meme!
Changes in 14.2.4
Fix Android performance regression when ART’s interpreter is used, such as
when using deoptimizeEverything() or deoptimizeBootImage(), which results in
our JS callbacks becoming extremely hot. Move the hot callbacks to CModule to
speed things up.
Fix V8 debugger support in Node.js bindings on Linux.
Fix crash on ELF init error in the libdwarf backend.
Changes in 14.2.5
Fix regression on older Android systems, introduced in 14.2.4.
Changes in 14.2.6
Fix compatibility with legacy NativeBridge v3 and newer, where a namespace
needs to be specified.
Changes in 14.2.7
Fix frida-java-bridge crash on systems where printf() renders %p without
“0x” prefix.
Fix jni_ids_indirection_ offset parsing on ARM64. Thanks @muhzii!
Changes in 14.2.8
Fix GLib SO_NOSIGPIPE regression on i/macOS. This would typically result in
frida-server dying due to SIGPIPE. Thanks @mrmacete!
Refactor CModule internals and lay foundations for GCC backend. Thanks
@mephi42!
Add EventSink.make_from_callback() for Stalker C API consumers that only care
about events, and don’t need lifecycle hooks or code transformations.
Emit Stalker BLOCK event at the start of the block, as this is what’s the most
intuitive, as one would expect at least as many BLOCK events as COMPILE
events. This behavior is also the most suitable for measuring coverage.
Handle permanent entries in Darwin CodeSegment backend. Starting from iOS 14.3
on A12+ devices, mach_vm_remap() can return KERN_NO_SPACE when the target VM
map entries are marked as “permanent”. Thanks @mrmacete!
Improve frida-inject to support bidirectional stdio.
Add support for Termux in frida-python: pip install frida-tools now works.
Changes in 14.2.11
Improve frida-inject to support raw terminal mode.
Add internal policy daemon for Darwin.
Improve Gum.Darwin.Mapper to support strict kernels.
Changes in 14.2.12
Fix ART method hooking reliability after GC. Thanks @muhzii!
Changes in 14.2.13
Fix Instruction operands parsing on x86, ensuring the immediate value is
always represented by an Int64 and never a number. Thanks @muhzii!
Fix frida-inject when process is not attached to a terminal. Thanks
@muhzii!
Expose Base64 and Checksum GLib primitives to CModule. Thanks @mrmacete!
Changes in 14.2.14
Fix Gadget crash on i/macOS when loaded early.
Make frida-inject stdin communication optional. Thanks @muhzii!
Support iOS app spawn on unc0ver 6.x. Thanks @mrmacete!
Work around single-step delay when spawning iOS apps, to avoid failing
randomly. Thanks @mrmacete!
Fix read() signature mismatch in the libc shim, which would result in a
compilation error on newer Apple toolchains. Thanks @Manouchehri!
Fix Android enumerate_applications() name truncation on newer versions of
Android. Kudos to @pancake for reporting and helping figure this one out!
Fix hang when target is unable to load frida-agent.
Fix support for attaching to Windows services.
Clean up stale Windows services before registering new ones.
Add build option to support using installed assets instead of embedding them.
Update iOS packaging to use installed assets.
Add basic support for jailed Android. Thanks @enovella_ for all the fun
and productive pair-programming on this one!
Extend Arm64Writer API to support more immediates.
Improve Stalker to support temporarily misaligned stack on arm64.
Fix crash in Stalker follow() without a sink.
Implement Stalker invalidation support. This allows updating the
instrumentation without throwing away all of the translated code. Thanks
for the assist on this one, @p1onk!
Add Gum.DarwinModule.enumerate_function_starts().
Add Gum.DarwinGrafter for AOT grafting to be able to prepare binaries so they
can be instrumented when runtime code modification isn’t possible. Thanks for
the assist, @mrmacete!
Add Memory.allocate_near().
Improve Stalker performance and robustness on all supported architectures:
Improve call probes to probe at the target instead of at the call
site, and take advantage of the new invalidation infrastructure.
Handle adding/removing call probes from within call probes.
Refactor callout-handling so user data can be destroyed on invalidate.
This also eliminates the callout lock.
In case of self-modifying code, recompile instead of allocating a new
block.
Use separate slabs for code and data, to avoid cases where we only
use part of the slab because we run out of metadata storage.
Inline the first code/data slab in ExecCtx, so we use a lot less
memory when following threads that either don’t touch much code, or
none at all in case they don’t wake up.
Don’t bother storing original code when trust_threshold is 0.
Simplify Stalker block metadata to reduce the per-block memory
consumption.
Fix result of Java.enumerateMethods() on ART. This was a bug where static
initializer methods were being included in the enumerated set as ‘$init’ when
they should be skipped altogether. Thanks @muhzii!
Fix the Android/ART near memory allocation code path used during Java method
hooking. Thanks @muhzii!
Fix handling of generic Java array types. This allows array objects obtained
from the runtime to be reused later when marshalling array types, which is
necessary to preserve type information particularly in cases where the type
is dynamic. Thanks @muhzii!
Port Android/ART StackVisitor to x86, x64, and ARM32. Thanks @P-Sc!
Fix ARM cache flushing on Android. Turns out cacheflush() expects a range on
Linux/ARM. This 32-bit Android/ARM regression was introduced in 14.2.0.
Add a few missing TinyCC builtins for 32-bit ARM. Kudos to @giantpune for
reporting and helping figure this one out!
Fix wrap-around in Stalker block recycling logic.
Fix V8 NativePointer construction from large numbers.
Fix Stalker local thread actions on Windows.
Fix the CModule temporary directory cleanup logic.
Remove forgotten InspectorServer debug code.
Fix the V8 debugger integration. Kudos to @taviso for reporting!
Changes in 14.2.15
Fix compatibility with latest unc0ver iOS jailbreak. Thanks @mrmacete!
Handle replacing ART methods that may be devirtualized. Thanks @liuyufei!
Changes in 14.2.16
Add many missing TinyCC builtins for 32-bit ARM. Kudos to @giantpune for
reporting and helping figure this one out!
Fix Android ART trampoline alignment when using ADRP on arm64, previously
resulting in Error: invalid argument exception being thrown when attempting
to replace some methods. Kudos to @pandasauce for reporting and helping
figure this one out!
Changes in 14.2.17
Enumerate Darwin imports from chained fixups, to support the latest arm64e
binaries. Thanks @mrmacete!
Fix chained fixups handling in the jailed iOS injector. Thanks @mrmacete!
qml: Compile with no_keywords for GLib compatibility. Thanks @suy!
Changes in 14.2.18
Fix i/macOS injector on recent XNU versions, where mach_port_extract_right()
fails with KERN_INVALID_CAPABILITY when trying to steal the target process’
POSIX thread port send right. This resulted in the injector assuming that we’d
uninjected, subsequently deallocating memory still in use.
Fix ___error symbol name in the jailed iOS injector. Thanks @mrmacete!
Fix enumeration of modules with spaces on path in the Linux backend. Thanks
@suy!
Fix Stalker handling of direct branch addresses on x64.
We’ve just upgraded all of our dependencies to the latest and greatest. Part of
this work included refurbishing the build system bits used for building them.
With these improvements we will finally support building past versions of Frida
fully from source, which has been a long-standing issue that’s caused a lot of
frustration.
It is now also a whole lot easier to tweak our dependencies, e.g. while
debugging an issue. Say you’re troubleshooting why Thread.backtrace() isn’t
working well on Android, you might want to play around with libunwind’s
internals. It is now really easy to build one specific dependency:
$ make -f Makefile.sdk.mk FRIDA_HOST=android-arm64 libunwind
Or if you’re building it for the local system:
$ make -f Makefile.sdk.mk libunwind
But you might already have built Frida, and want to switch out libunwind in the
prebuilt SDK that it is using. To do that you can now do:
$ make -f Makefile.sdk.mk symlinks-libunwind
You can then keep making changes to “deps/libunwind”, and perform an incremental
compilation by re-running:
$ make -f Makefile.sdk.mk libunwind
iOS
We now support iOS 14.2. It was kinda already working, but our crash reporter
integration would deadlock Apple’s crash reporter, and this isn’t great for
system stability overall.
GumJS support for size_t and ssize_t
Thanks to @mame82 we finally support “size_t” and “ssize_t” in APIs
such as NativeFunction. This means that your cross-platform agents no longer
need to maintain mappings to the native types that these correspond to. Yay!
System GLib support
Gum can finally be built with the upstream version of GLib, and we now
support generating GObject introspection definitions. This paves the way for
future language bindings that are fully auto-generated.
Our Windows backend finally supports inprocess injection. By this I mean that in
the most common cases where the target process’ architecture is the same – and
no elevation is needed – we can now avoid writing out “frida-helper-{32,64}.exe”
to a temporary directory and launching it before we’re able to attach() to a
given target. As an added bonus this also reduces our startup time.
The motivation behind this improvement was to fix a long-standing issue where
some endpoint security products would prevent our injector from working, as our
logic was prone to trigger false positives in such software. We will still
obviously run into such issues when we do need to spawn our helpers, but
there’s now a good chance that the most common use-cases will actually work.
Stalker ARM improvements
For those of you using Stalker on 32-bit ARM, it should now be working a whole
lot better than ever before. A whole slew of fixes landed in this release.
Bytecode and frida-tools
One of the realizations since 14.0 was released is that QuickJS’ bytecode format
is a lot more volatile than expected. Because of this I would caution against
using “frida-compile -b” unless your application is designed to only be used
with one exact version of Frida.
As I wasn’t aware of this pitfall when cutting the previous release of
frida-tools, I opted to precompile the frida-trace agent to bytecode. Upon
realizing my mistake while working on releasing 14.1, I reverted this mistake
and released a new version of frida-tools.
So make sure you also grab its latest release while upgrading:
$ pip3 install-U frida-tools
EOF
There’s also a bunch of other exciting changes, so definitely check out the
changelog below.
Enjoy!
Changes in 14.1.0
All dependencies upgraded to the latest and greatest.
Heavily refurbished build system for dependencies. Going forward we will
finally support building past versions of Frida fully from source.
Port iOS crash reporter integration to iOS 14.2.
Fix error propagation when talking to iOS devices.
Add support for “size_t” and “ssize_t” in GumJS. Thanks @mame82!
Support linking against system GLib and libffi. Thanks @meme!
Improve Windows backend to support inprocess injection. This means we can
dodge common AV heuristics and speed things up in the most common cases where
the target process’ architecture is the same, and no elevation is needed.
Fix Stalker ARM handling of “ldr pc, [sp], #4”.
Fix Stalker ARM clobbering of flags in IT blocks.
Fix Stalker ARM handling of CMN/CMP/TST in IT blocks.
Fix suppression flags for ThumbWriter instruction.
Fix Stalker ARM exclusion logic reliability.
Fix ARM Stalker follow() of thread in Thumb mode.
Fix ARM Stalker SVC handling in Thumb mode.
Fix ThumbRelocator handling of unaligned ADR.
Move Stalker ARM to runtime VFP feature detection.
Refuse to Interceptor.attach() without any callbacks.
Improve GumJS error message formatting.
Fix starvation in the V8 debugger integration.
Keep NativeCallback alive during calls on V8 also.
Changes in 14.1.1
Fix CModule regression where Capstone went missing.
Add missing CModule builtins for 32-bit ARM.
Fix Thread.backtrace() on Android/ARM64.
Changes in 14.1.2
Fix Thread.backtrace() on Android/ARM.
Changes in 14.1.3
Fix ObjC.choose(). The TinyCC upgrade in 14.1.0 exposed an existing bug.
Re-enable V8 by default. Turns out we have use-cases where it is a much better
fit than QuickJS, and its debugger features were also being sorely missed.
Add –ignore-crashes/-C to frida-server for disabling the native crash
reporter integration. For use-cases where the integration is undesired, or
when running on bleeding edge OS versions that we don’t yet fully support.
(Crash reporter integration is only available on iOS and Android for now.)
Enhance devkits to ensure Capstone APIs are exposed on all platforms.
Here’s a major new release that took weeks of intense coding, with way too many
cups of coffee. But before we dive into it, we need to have a quick look down
memory lane.
For years now our V8-based runtime has served us well. But eventually we needed
to support constrained systems where V8 isn’t a great fit, so we introduced a
second runtime.
This has worked out nicely, but there were some trade-offs we were left with:
Language feature support being wildly different between the two runtimes.
We tried to alleviate some of this by making the minimalistic runtime be the
default, as it’s available everywhere and is the lowest common denominator in
terms of features.
Needing to sacrifice performance when using a tool such as frida-compile
to compile modern JavaScript to old JavaScript that runs on both runtimes.
Non-trivial agents with lots of code and data floating around make it clear
not just how fast V8 is – no surprise there – but that it’s really good at
packing objects to avoid wasting precious RAM. And to widen the gap between
the two runtimes even more, V8 can run the modern JavaScript as-is and doesn’t
need to run a bloated version that contains compatibility shims to fill in the
missing runtime bits such as Map and Set.
Example code and documentation tends to look arcane to avoid confusing users
who might try to run modern code on the default runtime.
Garbage collector implementation differences may hide the user’s bugs in one
runtime that instantly blow up in the other where resources are released way
more eagerly. One such example is failing to keep a NativeCallback alive while
external code is still using it.
Terrible UX: All of the above is a very frustrating and confusing story to
tell our users.
New features and refinements need to be implemented twice. This is a real pain
for me as a maintainer for obvious reasons.
Fast-forward to 2019 and QuickJS caught my eye. I was really busy with other
things at the time, though, so by the time I looked closer at it I noticed it
supports ES2020, and also performs impressively well for an interpreter.
But as I started thinking about bringing up a new runtime from scratch, and
seeing as the other two are roughly ~25 KLOC each, it just felt overwhelming.
I kept coming back to the QuickJS website though, devouring the technical
details, and even started reading deeper into the public API at some point.
Then I noticed that it didn’t support cooperative multi-threaded use, where
multiple threads execute JavaScript in lockstep. This made the mountain of work
ahead feel even more daunting, but then I remembered that I’d already
contributed support for this in Duktape, and it wasn’t that hard.
Eventually I mustered up the courage. Picked a super-simple test from GumJS’
extensive test-suite as my first challenge, and went ahead and copy-pasted
the ScriptBackend and Script implementations from the youngest of the
existing two runtimes. First renaming things, then stubbing out all of the
modules (Interceptor, Stalker, etc.), just wanting to get a near-empty “shell”
to compile and run.
At this point I was hooked and couldn’t stop. Lots of coffee was consumed, and
before I knew it I’d gotten the core bits and the first module implemented. Then
another, and then one more.
After working quite a bit with the QuickJS API, and jumping around its internals
to make sure I understood the reference counting rules etc., it suddenly seemed
really clear what was needed to implement the cooperative multi-threading API
that would be needed to make this a real runtime and not just a toy.
What we need to be able to do is suspend JS execution while calling out to a
NativeFunction. This is because the called function may block waiting for a lock
which another thread might already be holding, but that other thread may have
just called a hooked function and is waiting to enter the JS runtime. So if we
didn’t let go of the JS lock before calling the NativeFunction, we’d now be in
a deadlock.
Another use-case is calling Thread.sleep() or some other blocking API where
we’d cause starvation if we did that while holding the JS lock.
Anyway, the QuickJS multi-threading API turned out to be straight-forward,
so from there I kept on going, until it was all finally done! 🎉
At this point I was really curious about the performance of this brand new
runtime, starting with the question of what it costs to enter and leave it.
Went ahead and took it for a spin on an iPhone 6, running the GumJS test
that uses Interceptor to hook a nearly empty C function, supplying an empty JS
callback, and then measures the wall-clock time spent on each call as it keeps
calling the C function over and over.
The idea is to simulate what would happen if the user hooks a function that’s
called frequently, to get an idea of the base overhead.
Wow, so that was looking promising! How about baseline memory usage, i.e.
how much memory is consumed by one instance of the runtime itself?
That’s quite an improvement – only one fifth of the previous runtime!
The next thing I was curious about was the approximate initial size of Frida’s
internal heap when using our REPL. That includes all of the memory used by
frida-agent, the JS runtime, and the REPL agent that was loaded:
Yay, 1 MB freed up for other purposes!
So with that, I hope you’re as excited as I am about this new release. We’ve
replaced our previous default runtime with this brand new one built on QuickJS.
And as an experiment I have also decided to build our official binaries without
our V8 runtime. This means that the binaries are way smaller than they’ve ever
been before.
I do realize that some of you may have use-cases where the V8 runtime is
essential, so my hope is that you will take the new QuickJS runtime for a spin
and let me know how it works for you. If it’s an absolute disaster for your
particular use-case then don’t worry, just let me know and we will figure
something out.
If you’d like to build Frida yourself with the V8 runtime enabled, it’s only a
matter of tweaking this line. But please do let me know if you can’t live
without it, so we can decide on whether we need to keep supporting this runtime
down the road.
The only other change in this major release applies to i/macOS, where we’re
finally following Apple’s move to drop support for 32-bit programs. We’ll keep
the codepaths around for now though, but our official binaries have a lot less
fat, and the top-level build system is also a bit slimmer. E.g.
make core-macos-thin is now just make core-macos.
That’s all in Frida itself, but there’s more. We’ve also released frida-tools
9.0, freshly upgraded to make use of modern JavaScript features everywhere. That
includes frida-trace, where the generated boilerplate hooks have become a lot
more readable after some syntax upgrades. Last but not least we have also
released frida-compile 10.0, where the Babel dependencies are gone and so are
the corresponding command-line switches; it’s faster and so much simpler.
So with that, I hope you’ll enjoy this new release!
Changes in 14.0.0
Replace the default runtime with a brand new GumJS runtime based on QuickJS.
Disable V8 by default.
Retain callback object in Interceptor.attach() on V8.
Drop “enumerate” trap from the global access API.
Changes in 14.0.1
QJS: Fix nested global access requests.
qml: Update to the new frida-core API.
Changes in 14.0.2
QJS: Keep NativeCallback alive during calls.
QJS: Speed up the NativeCallback construction logic.
QJS: Disable stack limitation for now.
iOS: Port the iOS crash reporter integration to iOS 14.
iOS: Remove packaging logic for 32-bit.
Android: Use the default runtime for the “system_server” agent.
Modernize internal JavaScript agents.
Changes in 14.0.3
Disable V8 on Windows also.
iOS: Improve the packaging script.
Changes in 14.0.4
iOS: Fix arm64e regression caused by toolchain upgrade.
Changes in 14.0.5
QJS: Fix Interceptor error-handling.
Changes in 14.0.6
ObjC: Fix lifetime of replaced methods so they’re not tied to the class
wrapper, and also kept alive in chaining use-cases. Kudos to @Hexploitable
and @mrmacete for the assist!
Fix intermittent hang when enumerating and modifying threads on Linux.
Fix inconsistent PC vs CPSR Thumb bit handling.
Fix build regressions on Linux/armhf and Linux/arm64.
Publish binaries for Raspberry Pi 32- and 64-bit.
Changes in 14.0.7
Avoid deadlocking in scenarios where we crash while executing JS code, e.g.
when calling out to a NativeFunction w/ exceptions: 'propagate', or in case
of a bug in GumJS. Thanks @mrmacete!
Fix CModule on macOS/arm64.
Publish Python and Node.js binaries for Raspberry Pi 32-bit.
Publish binaries for Fedora 33 instead of Fedora 32.
Publish binaries for Ubuntu 20.10.
Changes in 14.0.8
Improve jailed iOS upload reliability by adding some bi-directional
communication into the upload connection. This is to prevent DoS protections
from kicking in during gadget upload in complex remote configurations. Thanks
@mrmacete!
In anticipation of Apple releasing macOS 11, it’s time for Frida 12.11! This
release brings full compatibility with macOS 11 Beta 3. Not only that, we now
also support macOS on Apple silicon. Yay!
It’s worth noting that we didn’t stop at arm64, we also support arm64e. This ABI
is still a moving target, so if you have a Developer Transition Kit (DTK) and
want to take this for a spin you will have to disable SIP, and then add a boot
argument:
$ sudo nvram boot-args="-arm64e_preview_abi"
Considering this awesome convergence of platforms, there’s actually a chance
that we may already support jailbroken iOS 14. We will know once a public
jailbreak becomes available. At least it shouldn’t require much work to support.
So for those of you exploring your DTK, you can grab our CLI tools and Python
bindings the usual way:
$ pip3 install frida-tools
As a sidenote we just released CryptoShark 0.2.0 and would highly recommend
checking it out. Only caveat is that we only provide binaries for macOS/x86_64
for now, so if you want to try this on macOS/arm64 you will be able to run it
thanks to Rosetta, but attaching to processes on the “Local System” device
won’t work.
The workaround is simple though – just grab a frida-server binary from our
releases and fire it up, then point CryptoShark at the “Local Socket”
device. You can also use local SSH port forwarding if you’d like to run
CryptoShark on one system and attach to processes on another:
$ ssh -L 27042:127.0.0.1:27042 dtk
There’s also a lot of other exciting changes in this release, so definitely
check out the changelog below.
Enjoy!
Changes in 12.11.0
Add support for macOS 11 and Apple silicon.
Daemonize helper process on Darwin. Thanks @mrmacete!
Daemonize helper process on Linux.
Fix unreliable iOS device handling when using usbmuxd. Thanks @mrmacete!
Fix infinite wait when i/macOS frida-helper dies early.
Add Android spawn() “uid” option to specify user ID. Thanks @sowdust!
Add support for the latest checkra1n jailbreak. Thanks for the assist,
@Hexploitable!
Improve Stalker ARM stability.
Plug leak in Interceptor arm64 backend error path.
Fix interception near memcpy() on systems w/o RWX pages.
Fix encoding of CpuContext pointers on Darwin/arm64e.
Always strip backtrace items on Darwin/arm64.
Fix Linux architecture detection on big-endian systems.
Fix Capstone endianness configuration on ARM BE8.
Changes in 12.11.1
Handle i/macOS targets using different ptrauth keys.
Fix Linux CPU type detection on big-endian systems.
Fix early instrumentation on Linux/ARM-BE8.
Fix injection into Linux processes blocked on SIGTTIN or SIGTTOU.
Changes in 12.11.2
Fix Stalker thread_exit probing on macOS 11/x86_64.
Fix slow exports resolution on macOS 11/x86_64.
Fix CModule support for Capstone headers on ARM.
Add ArmWriter to the CModule runtime for ARM.
qml: Add support for specifying the script runtime to use.
Changes in 12.11.3
Fix prototype of ModuleMap.values() in the V8 runtime.
qml: Sync DetachReason enum with the current Frida API.
qml: Fix Device lifetime logic.
Changes in 12.11.4
Fix injector on macOS 11 beta 3. Drop support for older betas.
Drop helper hack made redundant by macOS 11 beta 3.
Fix handling of i/macOS introspection modules.
Changes in 12.11.5
Fix i/macOS early instrumentation of processes using dyld’s modern code path
on macOS 11 and iOS 14.
Make JVM method interception safer by installing new methods using
VMThread::execute(), which blocks all Java threads and makes it safer to do
interception of hot methods. Thanks @0xraaz!
Add support for SUB instruction to ARM Relocator. This means improved
reliability when using Interceptor and Stalker on 32-bit ARM.
qml: Fix build with GCC by adding missing include.
Changes in 12.11.6
Port iOS jailed injector to the new arm64e ABI. This means iOS 14 beta 3 is
now fully supported in jailed mode, even on A12+ devices.
Changes in 12.11.7
Improve libc detection on Linux and QNX. Thanks @demantz!
Fix checking of symbol sizes in libdwarf backend. This means more reliable
debug symbol resolution on Linux.
Improve Android Java hooking reliability by clearing the
kAccFastInterpreterToInterpreterInvoke flag. Thanks @deroko!
Guard against using Java wrappers after $dispose(), to make such dangerous
bugs easier to detect.
Improve the frida-qml build system and add support for standalone use.
Changes in 12.11.8
Add support for macOS 11 beta 4 on Apple silicon.
Changes in 12.11.9
Add support for jailed iOS w/ Xcode 12 developer disk images.
Changes in 12.11.10
node: Plug leak in IOStream’s WriteOperation. Thanks @mrmacete!
qml: Add support for listing applications.
qml: Expose a “count” property on each model.
Fix ARM relocation of “add sb, pc, r4”.
Fix ARM relocation of “add ip, pc, #4, #12”.
Fix ARM writer support for LDMIA when Rn is in reglist.
Changes in 12.11.11
Add support for opaque JNI IDs on Android R, to support debuggable apps.
Thanks @muhzii!
qml: Add support for spawning processes.
qml: Add missing libraries when linking with devkit on Linux.
qml: Fix static linking on Linux.
qml: Optimize startup to not wait for enumerate_devices().
Changes in 12.11.12
Initialize CoreFoundation during early instrumentation on i/macOS. Thanks
@mrmacete!
Support a NULL EventSink in Stalker. Thanks @meme!
node: Provide Electron prebuilds for v10 and v11. Next release will drop
prebuilds for v9.
qml: Add post(QJsonArray).
Changes in 12.11.13
Fix ART internals probing on Android 11/arm64. Thanks @enovella_!
Build GumJS runtime for V8 without compression for now, as we need to improve
frida-compile to use the latest version of terser.
Changes in 12.11.14
Build GumJS runtime for V8 with compression now that frida-compile has been
upgraded to the latest version of terser.
Changes in 12.11.15
Add support for iOS 14.x secure DTX. Thanks @mrmacete!
Fix Java.deoptimizeEverything() on Android 11. Thanks @Gh0u1L5!
Changes in 12.11.16
Fix arm64e support in Arm64Relocator.can_relocate(). Thanks @mrmacete!
Add “onEvent” option to Stalker.follow(). This allows synchronous
processing of events in native code – typically implemented using CModule.
Useful when wanting to implement custom filtering and/or queuing logic to
improve performance, or sacrifice performance in exchange for reliable event
delivery.
Expose Stalker’s live CpuContext to EventSink. This can be accessed through
the “onEvent” callback, and through the Gum C API.
Add Spinlock to the CModule runtime.
Changes in 12.11.17
Kill via LLDB on jailed iOS, to avoid killing via ProcessControl when
possible. Turns out our previous behavior left debugserver in a bad state
for which killed apps sometimes would appear as already running, failing early
instrumentation on subsequent spawn() attempts. Thanks @mrmacete!
Fix Java bridge initialization on older Android API levels by letting the
instrumentation field detection fail gracefully. We don’t need it on older API
levels anyway.
Reduce Duktape memory usage a little per script. There is no need to intern
the script source code string.
Changes in 12.11.18
Skip app extensions when detecting frontmost app on jailed iOS. Sometimes an
app extension was returned as the first matched process, subsequently throwing
“Unable to resolve bundle path to bundle ID”. Thanks @mrmacete!
Improve Android ART instrumentation offset detection for x86/x86_64. Thanks
@Gh0u1L5!
Fix JDWP initialization failure on Android 7.1-8.1. Thanks @Gh0u1L5!
Fix nearest symbol logic in the libdwarf backend.
Plug a leak in the Duktape-based runtime’s argument parsing logic, where any
collected memory range arrays would leak in case an error occurs parsing one
of the following arguments.
This time we have some exciting news for Java developers and reversers:
frida-java-bridge now supports the HotSpot JVM. This means our Java
runtime bridge is no longer exclusively an Android feature. Huge thanks to
Razvan Sima for this amazing addition.
The timing couldn’t have been any better either, as we recently also added
Java.enumerateMethods(query), a brand new API for efficiently locating methods
matching a given query. We made sure to also implement this for the HotSpot JVM.
The query is specified as "class!method", with globs permitted. It may also be
suffixed with / and one or more modifiers:
i: Case-insensitive matching.
s: Include method signatures, so e.g. "putInt" becomes
"putInt(java.lang.String, int): void". Handy to match on argument and
return types, such as "*!*: boolean/s" to match all methods that return a
boolean.
u: User-defined classes only, ignoring system classes.
We’ve also enhanced frida-trace to support Java method tracing:
$ frida-trace \-U\-f com.google.android.youtube \--runtime=v8 \-j'*!*certificate*/isu'
Instrumenting...
X509Util.addTestRootCertificate: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/addTestRootCertificate.js"
X509Util.clearTestRootCertificates: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/clearTestRootCertificates.js"
X509Util.createCertificateFromBytes: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/createCertificateFromBytes.js"
X509Util.isKnownRoot: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/isKnownRoot.js"
X509Util.verifyKeyUsage: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/verifyKeyUsage.js"
X509Util.verifyServerCertificates: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.X509Util/verifyServerCertificates.js"
ResourceLoader$CppProxy.native_enableDevCertificate: Auto-generated handler at "/Users/oleavr/__handlers__/com.google.android.libraries.elements.interfaces.ResourceLoader_CppProxy/native_enableDevCertificate.js"
ResourceLoader$CppProxy.enableDevCertificate: Auto-generated handler at "/Users/oleavr/__handlers__/com.google.android.libraries.elements.interfaces.ResourceLoader_CppProxy/enableDevCertificate.js"
AndroidCertVerifyResult.getCertificateChainEncoded: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.AndroidCertVerifyResult/getCertificateChainEncoded.js"
bjbm.a: Auto-generated handler at "/Users/oleavr/__handlers__/bjbm/a.js"
bjbn.a: Auto-generated handler at "/Users/oleavr/__handlers__/bjbn/a.js"
AndroidNetworkLibrary.addTestRootCertificate: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.AndroidNetworkLibrary/addTestRootCertificate.js"
AndroidNetworkLibrary.clearTestRootCertificates: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.AndroidNetworkLibrary/clearTestRootCertificates.js"
AndroidNetworkLibrary.verifyServerCertificates: Auto-generated handler at "/Users/oleavr/__handlers__/org.chromium.net.AndroidNetworkLibrary/verifyServerCertificates.js"
vxr.checkClientTrusted: Auto-generated handler at "/Users/oleavr/__handlers__/vxr/checkClientTrusted.js"
vxr.checkServerTrusted: Auto-generated handler at "/Users/oleavr/__handlers__/vxr/checkServerTrusted.js"
vxr.getAcceptedIssuers: Auto-generated handler at "/Users/oleavr/__handlers__/vxr/getAcceptedIssuers.js"
ResourceLoader.enableDevCertificate: Auto-generated handler at "/Users/oleavr/__handlers__/com.google.android.libraries.elements.interfaces.ResourceLoader/enableDevCertificate.js"
Started tracing 18 functions. Press Ctrl+C to stop.
/* TID 0x339d */
955 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "suggestqueries.google.com")
972 ms AndroidCertVerifyResult.getCertificateChainEncoded()
1043 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,4,…],[48,-126,4,…]], "RSA", "www.googleadservices.com")
1059 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x33a0 */
1643 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,5,…],[48,-126,4,…]], "RSA", "googleads.g.doubleclick.net")
/* TID 0x339d */
1651 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "www.youtube.com")
/* TID 0x33a1 */
1665 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,15,…],[48,-126,4,…]], "RSA", "lh3.googleusercontent.com")
/* TID 0x33a0 */
1674 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x339d */
1674 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x3417 */
1674 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,15,…],[48,-126,4,…]], "RSA", "yt3.ggpht.com")
/* TID 0x33a1 */
1684 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x3417 */
1688 ms AndroidCertVerifyResult.getCertificateChainEncoded()
2513 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "redirector.googlevideo.com")
2527 ms AndroidCertVerifyResult.getCertificateChainEncoded()
2722 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "r1---sn-bxuovgf5t-vnaz.googlevideo.com")
/* TID 0x33a1 */
2741 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "r2---sn-bxuovgf5t-vnas.googlevideo.com")
/* TID 0x339d */
2758 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,9,…],[48,-126,4,…]], "RSA", "r2---sn-bxuovgf5t-vnaz.googlevideo.com")
/* TID 0x33a1 */
2771 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x3417 */
2772 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x339d */
2777 ms AndroidCertVerifyResult.getCertificateChainEncoded()
2892 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,6,…],[48,-126,4,…]], "RSA", "r2---sn-bxuovgf5t-vnas.googlevideo.com")
/* TID 0x3417 */
2908 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,6,…],[48,-126,4,…]], "RSA", "r2---sn-bxuovgf5t-vnaz.googlevideo.com")
/* TID 0x33a1 */
2926 ms AndroidNetworkLibrary.verifyServerCertificates([[48,-126,6,…],[48,-126,4,…]], "RSA", "r1---sn-bxuovgf5t-vnaz.googlevideo.com")
/* TID 0x3417 */
2935 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x339d */
2937 ms AndroidCertVerifyResult.getCertificateChainEncoded()
/* TID 0x33a1 */
2942 ms AndroidCertVerifyResult.getCertificateChainEncoded()
This was just released as part of frida-tools 8.0 – which you may grab
through e.g.: pip3 install -U frida-tools
We’ve also been working hard on quality improvements across the board. One good
example is Stalker for 32-bit ARM, which now works a lot better on Android. It
is also a lot faster, in part because of a bug resulting in Thumb blocks being
recompiled over and over. We have also implemented one of the adaptive
optimizations that the other Stalker backends make use of, and this alone
typically amounts to a ~5x performance improvement.
So that should cover the highlights – but if you’re curious about the details
I’d highly recommend reading the changelog below.
Enjoy!
Changes in 12.10.0
Java: Add support for HotSpot JVM. Uses JVMTI to enumerate classes and choose
objects. Method interception works if the JVM library has symbols (default
with JDK on macOS). Tested on macOS with java 8, 11, 13, 14. Thanks
@0xraaz!
Java: Fix non-return from _getUsedClass(), where calling Java.use() twice
without using Java.perform() would result in _getUsedClass() getting stuck
in an infinite sleep loop. Thanks @0xraaz!
Java: Fix $alloc(), which got broken by the refactoring a while back.
ObjC: Add Block.declare() to be able to work with blocks without signature
metadata.
ObjC: Fix ObjC pointer handling regression introduced in 12.9.8.
Changes in 12.10.1
Java: Allow ClassFactory.get(null), for convenience when using
enumerateMethods().
Java: Restore the JVM method adjustment logic, which got accidentally dropped
from the pull-request. Thanks @0xraaz!
Changes in 12.10.2
Fix handling of long symbol names on i/macOS. Thanks @mrmacete!
Java: Fix JVM interception issues for static/final methods. Thanks
@0xraaz!
Fix Stalker ARM handling of Thumb-2 “mov pc, <reg>”.
Fix Stalker ARM handling of volatile VFP registers.
Changes in 12.10.3
Fix device removal wiring in the Fruity backend. Thanks @mrmacete!
Avoid clobbering R9 in ArmWriter.put_branch_address().
Add ThumbWriter.can_branch_directly_between().
Add ThumbWriter.put_branch_address().
Improve ThumbRelocator to handle ADR.
Fix Stalker ARM block corruption.
Fix Stalker ARM block recycling logic for Thumb blocks.
Add missing Stalker ARM continuation logic, to support long basic blocks.
Implement Stalker ARM backpatching logic to improve performance, typically 5x.
Changes in 12.10.4
Fix encoding of Module.name in the V8 runtime. Thanks @mrmacete!
Our previous big release was all about Stalker. For those of you not yet
familiar with it, it’s basically a code tracing engine – allowing threads to be
followed, capturing every function, every block, even every instruction which is
executed. Beyond just tracing code, it also allows you to add and remove
instructions anywhere. It even uses advanced JIT tricks to make all of this
really fast.
That may still sound a little abstract, so let’s have a look at a couple of
examples. One way to use it is when you want to determine “what other functions
does this function call”. Or, perhaps you’d like to use Apple’s speech
synthesizer to announce the RAX register’s value at every RET instruction in
code belonging to the app? Here is how that can be done. This was one of the
demos at my r2con presentation back in 2017.
Up until now Stalker has only been available on Intel architectures and ARM64.
So I’m really excited to announce that Stalker is now also available on ARM32!
Yay! 🎉 I’m hopeful that this sorely missed Stalker backend will motivate a lot
of you to start building really cool things on top of Stalker. I feel like it
has a ton of potential beyond “just” code tracing. And combined with CModule
it’s become really easy to balance rapid prototyping and dynamic behavior with
performance.
There’s so much to talk about in this release. One of the other major changes is
that we have upgraded all of our dependencies. Most interesting among them is
probably V8, which we have upgraded to 8.4. This means you can use all of the
latest JavaScript language features such as optional chaining and nullish
coalescing operator without having to frida-compile your agent. That, and
performance improvements, another area where V8 just keeps on getting better and
better.
We’ve also just added support for Android 11 Developer Preview 4, and iOS/arm64e
apps are now fully supported even on jailed iOS. Things have improved so much
across all of our supported platforms. One thing in particular that I’d like to
highlight is that we have finally eliminated a long-standing resource leak
affecting our Duktape-based JS runtime – a bug that’s been around for as long as
we’ve been using Duktape as our default JS runtime.
Anyway, there’s really no easy way to dig into all of the areas where things
have improved, so definitely check out the changelog below.
Enjoy!
Changes in 12.9.0
Stalker now also available on ARM32. 🎉
Stalker JS integrations no longer clobber errno / LastError.
Stalker.follow() now reliable on x86 and ARM64, including when the target
thread is in a syscall on Windows.
Stalker is finally reliable on WoW64. Thanks @zuypt!
All dependencies have been updated to the latest and greatest. Most exciting
is V8 8.4, supporting the latest JavaScript language features.
Long-standing Duktape memory leak finally discovered and fixed. Thanks to
@disazoz for the bug-report that lead to this breakthrough.
Socket.connect() no longer leaks the file-descriptor (and associated memory)
on error. (Fixed by the GLib dependency upgrade.) Thanks for reporting,
@1215clf!
Kernel.read*() no longer leaks in the V8 runtime.
UNIX build system moved to Meson 0.54.
Windows build system moved to VS2019.
Node.js prebuilds provided for v14, in addition to v10 and v12.
Electron prebuilds provided for v8 and v9.
Fedora packages for F32.
Ubuntu packages for Ubuntu 20.04.
Python bindings no longer using any deprecated APIs.
Support for leanback-only Android apps. Thanks @5murfette!
iOS jailed spawn() w/o closure supported on arm64e. Thanks @mrmacete!
iOS usbmux pairing record plist parsing now also handles binary plists,
fixing a long-standing issue where Frida would reject a tethered iOS USB
device. Thanks @pachoo!
ObjC.choose() also supported on arm64e. Thanks @mrmacete!
ObjC.protocols enumeration finally working properly, and not just the first
time. Thanks for reporting, @CodeColorist!
Initial support for Android 11 Developer Preview. Thanks @abdawoud!
MUSL libc compatibility.
Support for older versions of glibc, so our binaries can run on a wide variety
of desktop Linux systems.
Libc shim also covers memalign() and supports newer GNU toolchains.
Exceptor’s POSIX backend is now detecting Thumb correctly on ARM32, which
would previously result in random crashes.
Exceptor no longer clobbers “rflags” (x86_64) and “cpsr” (ARM64) on i/macOS,
and provides write access to the native context.
Four essential i/macOS 64-bit syscalls added to the libc shim: read(),
write(), mmap(), munmap(). Thanks @mrmacete!
iOS binaries now signed with the “skip-library-validation” entitlement for
convenience. Thanks @elvanderb!
The frida-core Vala API bindings are no longer missing the frida.Error type.
Our scripts now allow messages to be post()ed to them while they are in the
LOADING state. This is useful when a script needs to make a synchronous
request during load(). Thanks @Gbps!
Gadget finally supports early instrumentation with the V8 runtime on 64-bit
ELF targets, where constructor functions would previously be run in the wrong
order. Thanks @tacesrever!
Support for ADB channels beyond just TCP in Device.open_channel().
Thanks @aemmitt-ns!
Many new instructions supported in the ArmWriter and ThumbWriter APIs.
Massive improvements to our ARM32 relocator implementations.
Linux module enumeration working when invoked through loader.
Linux symbol resolution improvements.
Better argument list handling in the V8 runtime, treating undefined the same
as in the Duktape runtime. Thanks @mrmacete!
CModule Stalker API is back in working order.
CModule runtime now exposes Thread.{get,set}_system_error().
CModule is now a stub on Linux/MIPS, instead of failing to compile due to
TinyCC not yet supporting MIPS.
Capstone configured to support ARMv8 A32 encodings.
Changes in 12.9.1
The Python bindings’ setup.py does the right thing for Python 3.x on macOS.
Changes in 12.9.2
Fruity (iOS USB) backend no longer emits a warning on stdio.
Changes in 12.9.3
Android 11 Developer Preview 4 is now supported. Thanks for the assist,
@enovella_!
Linux file monitoring is back in great shape.
ArmRelocator properly relocates ADD instructions involving the PC register.
ThumbRelocator properly handles IT blocks containing an unconditional branch.
This means Interceptor is able to hook even more tricky cases. Thanks
@bet4it!
Stalker ARM32 also supports clone syscalls in Thumb mode.
Stalker ARM32 now suppresses events around exclusive ops like the ARM64
backend.
Stalker ARM32 trust threshold support.
Improved error-handling in ObjC and Java bridges, to avoid crashing the
process on unsupported OSes.
Changes in 12.9.4
ObjC.available no longer pretends that the Objective-C runtime is available
when it indeed is not. The error-handling refactoring in 12.9.3 broke this,
and the regression went unnoticed due to this being a blind spot in our test
coverage.
Electron v9 is out, so we now only provide prebuilds for v9.
Changes in 12.9.5
iOS early instrumentation – i.e. spawn() – supported on latest unc0ver.
iOS crash reporter integration ported to iOS 13.5.
SystemFunction now implements call() and apply() in the Duktape runtime,
and not only in the V8 runtime.
Java bridge finally handles strings with embedded nuls, fixing a long-standing
issue that’s been around for as long as the Java bridge has existed. Thanks
@tacesrever!
Changes in 12.9.6
No changes except for proper Windows binaries this time. The Windows CI worker
did not actually build anything last time around, and released stale binaries.
Changes in 12.9.7
iOS early instrumentation more reliable on the unc0ver jailbreak: we now load
substrate-inserter.dylib as part of our early instrumentation. This means
it gets a chance to bootstrap the process, and lets you hook system APIs
hooked by the bootstrapper without worrying about the bootstrapper getting
confused when it encounters your hooks. Thanks @mrmacete!
Changes in 12.9.8
ApiResolver implementations now support case-insensitive matching by appending
“/i” to the query string. Thanks @Hexploitable!
The module ApiResolver no longer leaks the MatchInfo instance.
CModule runtime gained GLib.PatternSpec and GLib UTF-8 case helpers.
DebugSymbol.load() introduced to be able to explicitly load debug symbols.
For now this is only implemented on Windows, where we now also support
“module!symbol” notation for improved performance and precision. Thanks
@ohjeongwook!
Java bridge got a brand new API: Java.enumerateMethods(query) This enables
efficiently locating methods matching a given query.
ObjC.choose() no longer crashes due to a lifetime issue only reproducible in
our V8 runtime.
Get ready for an exciting new release. This time around we’re giving some long
overdue love to our Stalker engine. It’s been around for roughly ten years,
but it wasn’t until Frida 10.5 in late 2017 that we started unleashing its
massive potential.
Up until now we were able to Stalker.follow() existing threads and not only
observe them, but also mutate their instruction streams any way we’d like. It
could also be combined with Interceptor to instrument the current thread
between strategic points. This allowed us to build tools such as AirSpy.
But, what if we want to Stalker.follow() a NativeFunction call? This may seem
really simple, but reentrancy makes this really hard. It’s easy to end up
following execution inside e.g. our private heap, and end up needing to allocate
memory for the instrumentation itself… all kinds of fun scenarios that are
mind-boggling to reason about.
The way we dealt with this was to teach Stalker to exclude certain memory
ranges, so that if it sees a call going to such a location it will simply emit
a call instruction there instead of following execution. So what we did was to
automatically exclude frida-agent’s own memory range, and that way we didn’t
have to deal with any of the reentrancy madness.
We also took care to special-case attempts to Stalker.follow() the current
thread, so that we queued that work until we’re about to leave our runtime
and transition back into user code (or our main loop, in the case of the JS
thread).
That still left the big unanswered question of how to use Stalker in conjunction
with NativeFunction. We can now finally put that behind us:
By setting the traps: 'all' option on the NativeFunction, it will re-activate
Stalker when called from a thread where Stalker is temporarily paused because
it’s calling out to an excluded range – which is the case here because all of
frida-agent’s code is marked as excluded.
We can also achieve the same goal for Objective-C methods:
Yay. That said, these examples are barely scratching the surface of what’s
possible using Stalker. One of the really cool use-cases is in-process fuzzing,
which frida-fuzz is a great example of. There’s also a bunch of other
use-cases, such as reversing, measuring code coverage, fault injection for
testing purposes, hooking inline syscalls, etc.
So that’s the main story of this release. Would like to thank
@andreafioraldi for the great bug-reports and help testing these tricky
changes.
Wrapping up
One cool new feature worth mentioning is the new ArrayBuffer.wrap() API, which
allows you to conveniently and efficiently access memory regions as if they were
JavaScript arrays:
This means you can hand over direct memory access to JavaScript APIs without
needing to copy memory in/out of the runtime. The only drawback is that bad
pointers won’t result in a JS exception, and will crash the process.
We now also allow you to access the backing store of any ArrayBuffer, through
the new unwrap() method on ArrayBuffer. An example use-case for this is when
using an existing module such as frida-fs where you get an ArrayBuffer that
you then want to pass to native code.
Kudos to @DaveManouchehri for contributing the first draft of the
ArrayBuffer.wrap() API, and also big thanks to @CodeColorist for suggesting
and helping shape the unwrap() feature.
Changes in 12.8.0
Stalker reactivation working properly.
Stalker thread lifetime properly handled. Will also no longer crash when
following a thread to its death on i/macOS.
Safer garbage collection logic in Stalker.
Making mistakes in the Stalker transform callback which ends up throwing a JS
exception now results in Stalker.unfollow(), so the error doesn’t get
swallowed by the process crashing.
Robust support for Stalker transform calling unfollow().
Stalker support for older x86 CPUs without AVX2 support.
Support for disabling automatic Stalker queue drain.
NativeFunction is better at handling exceptions through the brand new
Interceptor unwinding API.
Java and ObjC APIs to specify NativeFunction options for methods through
clone(options), and blocks through the second argument to ObjC.Block().
ObjC class and protocol caching logic finally works. Thanks @gebing!
The prebuilt Python 3 extension for Windows finally supports all Python 3
versions >= 3.4 on Windows, just like on the other platforms.
ArrayBuffer wrap() and unwrap().
DebugSymbol API has better error-handling on Linux/Android.
Java integration no longer crashes in recompileExceptionClearForArm64() in
system processes on Android 10.
GumJS devkit on i/macOS supports V8 once again.
Changes in 12.8.1
The CModule Stalker integration is back in business.
Changes in 12.8.2
Thumb IT blocks are finally relocated correctly. This means we are able to
hook a lot more functions on 32-bit ARM targets, e.g. Android. Thanks
@bigboysun!
Changes in 12.8.3
Java.ClassFactory.get() introduced to be able to work with multiple class
loaders without worrying about colliding class names. This means that
assigning to the loader property is now considered deprecated. We still
keep it around for backwards compatibility, but using it alongside the new
API is not supported.
Java.enumerateLoadedClasses() also provides class handles and not just names.
The JNI GetByteArrayRegion() function is now part of the Env wrapper. Thanks
@iddoeldor!
Changes in 12.8.4
Internal hooks no longer result in crashes on Linux/ELF targets when PLT/GOT
entries haven’t been warmed up.
Changes in 12.8.5
Python bindings finally provide properly encoded error messages on Python 2.x.
Changes in 12.8.6
Android linker detection is finally working again in sandboxed processes.
This was a regression introduced in 12.7.8. Kudos to @DaveManouchehri
for reporting and helping track this one down!
Changes in 12.8.7
Our Node.js IOStream bindings received two critical stability improvements.
Turns out the cancellation logic had a race-condition that resulted in the
cancellable not always being used. There was also a bug in the teardown logic
that could result in a stream being closed before all I/O operations had
completed. Kudos to @mrmacete for these awesome fixes!
Changes in 12.8.8
Gadget no longer deadlocks on Android/Linux during early instrumentation
use-cases where Gadget’s entrypoint gets called with dynamic linker lock(s)
held. Due to Exceptor now using dlsym() to avoid running into PLT/GOT issues
during early instrumentation, we need to ensure that Exceptor gets initialized
from the entrypoint thread, and not the Gadget thread.
Changes in 12.8.9
Stalker’s JavaScript integration is no longer performing a use-after-free in
EventSink::stop(), i.e. after Stalker.unfollow().
Changes in 12.8.10
Gadget is once again able to run on iOS without a debugger present. This was a
regression introduced in 12.8.8. Kudos to @ddzobov for reporting!
Changes in 12.8.11
The i/macOS Exceptor’s API hooks no longer perform an OOB write when a
user of the Mach exception handling APIs only requests a subset of the
handlers. Such a user would typically be a crash reporter or analytics
framework.
Electron prebuilds are now provided for v8 (stable) and v9 (beta). We no
longer provide prebuilds for v7.
Changes in 12.8.12
Massively overhauled Android Java integration, now using Proxy objects and
CModule to lazily resolve things. And no more eval-usage to dynamically
generate method and field wrappers – i.e. less memory required per wrapper
generated. All of these changes reduce memory usage and allow Java.use()
to complete much faster.
Android Java integration provides uncensored access to methods and fields on
Android versions that attempt to hide private APIs, i.e. Android >= 9.
Way faster Android device enumeration. No longer running any adb shell
commands to determine the device name when the locally running ADB daemon is
new enough (i.e. ADB >= sometime during 2017).
We’ve finally eliminated a long-standing memory leak on Linux-based OSes,
affecting restricted processes such as zygote and system_server on newer
versions of Android. This was a bug in our logic that garbage-collects
thread-local data shortly after a given thread has exited. The mechanism that
determines that the thread has indeed finished exiting would fail and never
consider the thread gone. This would result in more and more garbage
accumulating, with a longer and longer collection of garbage to iterate over.
So not only would we be spending increasingly more time on futile GC attempts,
we would also be eating CPU retrying a GC every 50 ms.
The Python bindings allow obtaining a file-descriptor from a Cancellable in
order to integrate it into event loops and other poll()-style use-cases.
Worth noting that frida-tools 7.0.1 is out with a major improvement built on
this: The CLI tools no longer delay for up to 500 ms before exiting. So
short-lived programs like frida-ls-devices and frida-ps now feel very
snappy.
Duktape source-map handling now also works with scripts loaded by the REPL –
where the inline source-map isn’t the last line of the script due to the REPL
appending its own code. This means stack-traces always contain meaningful
filenames and line numbers.
Duktape: the baked in JavaScript runtime – i.e. GumJS’ glue code, ObjC, and
Java – is now Babelified with the loose option enabled, to reduce bloat and
improve performance. No modern JavaScript data structures leak out through the
APIs, so there’s no need to have Babel be spec-compliant.
V8: the baked in JavaScript runtime is compressed, for a smaller footprint and
faster code. This was previously only done to the Duktape one.
Better Linux process name heuristics in enumerate_processes().
Changes in 12.8.13
Java.performNow() is back in working order.
Python bindings’ setup.py now looks for a local .egg before attempting to
download one, and expects the download to complete within two minutes.
Kudos to @XieEDeHeiShou for these nice improvements!
Changes in 12.8.14
The iOS Simulator is now properly supported, both in Gadget form and attaching
to a running Simulator process from macOS. Kudos to @insitusec for helping
fix these issues!
Gadget now also looks for its .config in the directory above on iOS, but only
if its parent directory is named “Frameworks”. Kudos to @insitusec for
the suggestion!
Changes in 12.8.15
Brand new feature-complete support for iOS/arm64e, including new
NativePointer methods: sign(), strip(), blend().
Latest iOS Unc0ver jailbreak is now supported. Kudos to @mrmacete for
the pull-request, and @Pwn20wnd for the assistance! ❤️
Improved support for the Chimera jailbreak, making sure its
pspawn_payload-stg2.dylib is initialized. Thanks @mrmacete!
The i/macOS injector no longer fails when an agent entrypoint returns
instantly.
Better error message about needing Gadget for jailed iOS.
Improved error-handling in the Windows injector to avoid crashing the target
process when our DLL injection fails. Kudos @dasraf9!
Support for injection into live newborn targets on i/macOS, and also no longer
treating suspended processes as needing to be prepared for injection,
regardless of whether they actually need it.
Improved Android fault tolerance, handling zygote and system_server
processes dying without having to restart frida-server.
Now able to launch frida-server during boot on Android 10, as
LD_LIBRARY_PATH no longer interferes with the spawning of frida-helper-32.
Kudos to @enovella for helping track this one down!
No more infinite loop when failing to handle SIGABRT on UNIXy platforms.
We now support nested signals in Exceptor’s POSIX backend. Kudos @bannsec!
Proper handling of invalid Windows ANSI strings. Thanks, @clouds56!
Java.perform() working properly again on Android < 5.
Improved varargs-handling in NativeFunction, now promoting varargs smaller
than int. Thanks for reporting, @0x410c!
Changes in 12.8.16
Large CModule instances now working on iOS systems with 16K pages. Kudos to
@mrmacete for discovering and fixing this long-standing issue!
Stalker also works in arm64 processes on iOS/arm64e. Kudos to @AeonLucid
for reporting and helping track this one down!
Changes in 12.8.17
Support for injection into live newborn targets on i/macOS turned out to cause
regressions, so we’ve reverted it for now. Specifically, notifyd on iOS 12.4
is a case where libSystemInitialized is not getting set. Need to dig deeper
to figure out why, so decided to walk back this logic for now.
Changes in 12.8.18
New and improved Java.scheduleOnMainThread() to allow calling APIs such as
getApplicationContext(). Kudos to @giantpune for reporting!
Ability to hook CriticalNative methods on newer versions of Android. Kudos to
@abdawoud for reporting!
Changes in 12.8.19
Scripts are now properly cleaned up if destroyed without first being loaded.
This ensures that ultimately when the script core is disposed, it in turn
disposes its reference to the Exceptor. Failing to do so causes indefinite
hang when attaching after detaching in presence of unloaded scripts, due to
the Exceptor thread remaining in the target process. Kudos to @mrmacete
for discovering and fixing this long-standing issue!
Changes in 12.8.20
The remove_remote_device() API is back in working order. This was an
unfortunate regression introduced in 12.7.17. Thanks for reporting,
@CodeColorist!
There’s only one new feature this time, but it’s a big one. We’re going to
address the elephant in the room: performance.
While Frida’s instrumentation core, Gum, is written in C and can be used from C,
most use-cases are better off using its JavaScript bindings.
There are however situations where performance becomes an issue. Even when using
our V8-based runtime, which means your JavaScript will be profiled while it’s
running and optimized based on where the hotspots are… (Which by the way is
amazing – V8 is truly an impressive feat of engineering!)
…there is a small price to pay for entering and leaving the JavaScript VM.
On an iPhone 5S this might amount to something like six microseconds if you
use Interceptor.attach() and only specify onEnter, and leave it empty.
This may not sound like a lot, but if a function is called a million times,
it’s going to amount to 6 seconds of added overhead. And perhaps the hook only
needs to do something really simple, so most of the time is actually spent on
entering and leaving the VM.
There’s also the same kind of issue when needing to pass a callback to an API,
where the API walks through potentially millions of items and needs to call the
callback for each of them. The callback might just look at one byte and collect
the few of the items that match a certain criteria.
Naively one could go ahead and use a NativeCallback to implement that callback,
but it quickly becomes apparent that this just doesn’t scale.
Or, you might be writing a fuzzer and needing to call a NativeFunction in a
tight loop, and the cost of entering/leaving the VM plus libffi just adds up.
Short of writing the whole agent in C, one could go ahead and build a native
library, and load it using Module.load(). This works but means it has to be
compiled for every single architecture, deployed to the target, etc.
Another solution is to use the X86Writer/Arm64Writer/etc. APIs to generate
code at runtime. This is also painful as there’s quite a bit of work required
for each architecture to be supported. But up until now this was the only
portable option for use in modules such as frida-java-bridge.
But now we finally have something much better. Enter CModule:
It takes the string of C source code and compiles it to machine code, straight
to memory. This is implemented using TinyCC, which means that this feature
only adds ~100 kB of footprint to Frida.
As you can see, any global functions are automatically exported as NativePointer
properties named exactly like in the C source code.
And, it’s fast:
(Measured on an Intel i7 @ 3.1 GHz.)
We can also use this new feature in conjunction with APIs like Interceptor:
constm=newCModule(`
#include <gum/guminterceptor.h>
#define EPERM 1
int
open (const char * path,
int oflag,
...)
{
GumInvocationContext * ic;
ic = gum_interceptor_get_current_invocation ();
ic->system_error = EPERM;
return -1;
}
`);constopenImpl=Module.getExportByName(null,'open');Interceptor.replace(openImpl,m.open);
(Note that this and the following examples use modern JavaScript features like
template literals, so they either need to be run on our V8 runtime, or compiled
using frida-compile.)
Yay. Though this last particular example actually writes to stdout of the
target process, which is fine for debugging but probably not all that useful.
We can however fix that by calling back into JavaScript. Let’s see what that
might look like:
That is however just a toy example: doing it this way will actually defeat the
purpose of writing the hooks in C to improve performance. A real implementation
might instead append to a GLib.Array after acquiring a GLib.Mutex, and
periodically flush the buffered data by calling back into JS.
And just like JavaScript functions can be called from C, we can also share data
between the two realms:
For now we don’t have any docs on the built-in C APIs, but you can browse the
headers in frida-gum/bindings/gumjs/runtime/cmodule to get an overview.
Drop function names into an Internet search engine to look up docs for the
non-Frida APIs such as GLib’s.
The intention is to only expose a minimal subset of the standard C library,
GLib, JSON-GLib, and Gum APIs; in order to minimize bloat and maximize
performance. Things we include should either be impossible to achieve by calling
into JS, or prohibitively expensive to achieve that way.
Think of the JS side as the operating system where the functions you plug into
it are system calls; and only use CModule for hooking hot functions or
implementing high-performance glue code like callbacks passed to
performance-sensitive APIs.
Also bear in mind that the machine code generated by TinyCC is not as efficient
as that of Clang or GCC, so computationally expensive algorithms might actually
be faster to implement in JavaScript. (When using our V8-based runtime.) But for
hooks and glue code this difference isn’t significant, and you can always
generate machine code using e.g. Arm64Writer and plug into your CModule if you
need to optimize an inner loop.
One important caveat is that all data is read-only, so writable globals should
be declared extern, allocated using e.g. Memory.alloc(), and passed in as
symbols through the constructor’s second argument. (Like we did with calls in
the last example.)
You might also need to initialize things and clean them up when the CModule gets
destroyed – e.g. because the script got unloaded – and we provide a couple of
lifetime hooks for such purposes:
constcm=newCModule(`
#include <stdio.h>
void
init (void)
{
printf ("init\\n");
}
void
finalize (void)
{
printf ("finalize\\n");
}
`);cm.dispose();// or wait until it gets GCed or script unloaded
Anyway, this post is getting long, but before we wrap up let’s look at how to
use CModule with the Stalker APIs:
This shows how you can implement both the transform callback and the callouts
in C, but you may also use a hybrid approach where you write the transform
callback in JS and only some of the callouts in C.
It is also worth noting that I rewrote ObjC.choose() to use CModule, and it is
now roughly 100x faster. When testing it on the login screen of the Twitter app
on an iPhone 6S, this went from taking ~5 seconds to now only ~50 ms.
So with that, I hope you’ll enjoy this release. Excited to see what kind of
things you will build with the new CModule API. One thing I’m really looking
forward to is improving our REPL to support loading a .c file next to the
.js, for rapid prototyping purposes.
Enjoy!
Changes in 12.7.0
Brand new CModule API powered by TinyCC. (You just read about it.)
TinyCC was improved to support Apple’s ABI on macOS/x86.
Stalker.exclude() is now exposed to JS to be able to mark specific memory
ranges as excluded. This is useful to improve performance and reduce noise.
Concurrent calls to Java.use() are now supported, thanks to a neat
contribution by @gebing.
The hexdump() implementation was improved to clamp the length option to
the length of the ArrayBuffer, thanks to another neat contribution by
@gebing.
TinyCC was improved to support Apple’s ABI on iOS/arm64.
ObjC.choose() was rewritten using CModule, and is now ~100x faster.
Changes in 12.7.2
CModule got some missing ref-counting APIs.
Changes in 12.7.3
CModule memory ranges are now properly cloaked.
The V8 garbage collector is now informed about externally allocated CModule
memory so it can make better decisions about when to GC.
Symbols attached to a CModule are now properly kept alive in the V8 runtime
also; and the CModule itself is not kept alive indefinitely (or until script
unload).
CModule.dispose() was added for eagerly cleaning up memory.
Changes in 12.7.4
The frida-inject tool now supports spawn(). Kudos to @hunterli for
contributing this neat feature.
Our V8 runtime no longer deadlocks on i/macOS when thread_suspend() is
called with the JS lock still held, like Stalker.follow() indirectly does
when asked to follow another thread.
Changes in 12.7.5
Brand new channels API for establishing TCP connections to a tethered iOS
or Android device, as well as talking to lockdown services on a tethered
iOS device.
The timeout logic behind DeviceManager.find_device() and its sibling methods
is now working properly.
Java marshaling of java.lang.Class is now working properly, and instance
fields can also be introspected without needing an instance. Kudos to
@gebing for contributing these neat fixes!
Changes in 12.7.6
The Android linker is now properly detected on Android 10.
Our Android SELinux policy patcher now also handles devices like Samsung S10,
thanks to a neat contribution by @cbayet.
The frida-inject tool now supports -D/–device for working with non-local
devices.
We now have better error-handling to avoid crashing when i/macOS processes
terminate unexpectedly during early instrumentation.
iOS crash reporter integration is way more robust, thanks to some awesome
fixes contributed by @mrmacete. One of his fixes also ensures parallel
calls to recv().wait() for the same message type don’t end up in an infinite
wait.
Stalking of thread creation is now supported on Linux/arm64. Kudos to
@alvaro_fe for this awesome contribution!
V8 runtime’s WebAssembly support is working again on non-iOS also.
The Gum.DarwinModule API is now part of the cross-platform Gum API. Useful
for parsing Mach-O files on non-Apple systems.
Changes in 12.7.7
Eternalized agents are now kept around when the last session gets closed,
which means they can be reused for as long as the HostSession side, e.g.
frida-server, sticks around. This means that additional copies of frida-agent
can be avoided in a lot of cases. Kudos to @mrmacete for this awesome
improvement.
Java bridge no longer triggers a use-after-free when a method returns this.
Our Android SELinux policy patcher no longer prints a warning on older
versions of Android. This harmless but confusing regression was introduced
by the previous release’ fix for Samsung S10 ROMs.
Better SELinux-related error messages.
Rudimentary support for iOS/arm64e.
Changes in 12.7.8
Android 10 support just landed in our Java bridge thanks to a brilliant
contribution by @Alien-AV.
Better spawn()-handling for Android apps, where the activity parameter can
be used in cases where the app doesn’t have a launcher activity. This neat
improvement was contributed by @muhzii.
Android linker seeking logic was made future-proof thanks to an elegant
contribution by @timstrazz.
Massively improved fault-tolerance on iOS: our launchd agent now kills pending
processes when unloaded. This means that frida-server dying won’t leave
processes stuck in a suspended state. Kudos to @mrmacete for this awesome
improvement.
Changes in 12.7.9
We are back in business on macOS after a last-minute build regression snuck
into the previous release.
Changes in 12.7.10
MemoryAccessMonitor is now available on all platforms, and even the Duktape
runtime. Kudos to @alvaro_fe for these awesome improvements.
Android linker detection working properly again. (Regression introduced in
12.7.8.)
Gadget was improved to support passing a config through its constructor
function on i/macOS.
Gadget’s system loop integration – only implemented on i/macOS – was removed
to avoid undefined behavior in some scenarios.
Changes in 12.7.11
Frida no longer crashes in Android processes without a vDSO. (Regression
introduced in 12.7.8.)
Better error-handling when parsing Mach-O images.
ARM vs Thumb properly handled when restoring exception on i/macOS. Thanks
@alvaro_fe!
CModule’s header for JSON-GLib is now self-contained, as it should be.
Changes in 12.7.12
Full-featured iOS lockdown integration and unified devices, so Frida-based
tools don’t need to worry as much about jailed vs jailbroken. When interacting
with a jailed iOS device, Gadget is now injected automatically and there is no
need to repackage the app, it only has to be debuggable.
Frida is finally able to detect recent iOS devices on Windows.
Bug in V8 was tracked down and fix backported from upstream. Kudos to
@mrmacete for tracking this one down!
Changes in 12.7.13
Better handling of structs and unions in frida-objc-bridge. Thanks
@gebing!
Our Node.js bindings now also expose type definitions for Crash and
CrashParameters.
Attempts to attach to the system session on jailed iOS throw early and
with a clearer error message.
The iOS Developer Disk Image-related error messages were tweaked for
consistency.
Changes in 12.7.14
Frida now ensures code is readable before accessing it on Android >= 10.
This was the last missing piece for full-featured Android 10 support. Being
able to instrument system processes means that early instrumentation – i.e.
spawn() – works, and starting frida-server doesn’t crash system_server due
to the attempt it makes at preloading so the first spawn() will be fast.
Kudos to @Alien-AV and @esanfelix for the painful research that made
the solution possible to implement in one late Saturday evening. :-)
Changes in 12.7.15
Node.js bindings also expose the “summary” field of the Crash typing.
Changes in 12.7.16
The frida-gadget-ios meta-package comes with type definitions so it can be
consumed from TypeScript.
Node.js bindings provide proper typings for Stdio and ChildOrigin.
Changes in 12.7.17
More robust support for jailed iOS: calling kill() before resume() but after
attach() is now working properly.
Frida now communicates directly with the remote iOS/Android agent when
possible. We achieve this by establishing a fresh TCP connection to the
frida-server and having its file-descriptor passed to the agent. This means
frida-server can remove itself from the data path, improving performance and
reliability.
Clients connecting to frida-server to spawn() a process, but getting
disconnected before they get a chance to resume() or kill() said process,
will no longer leave such orphans in limbo. We now keep track of spawned
processes and kill() them if the client suddenly gets disconnected.
We no longer crash Zygote on Android 10. Turns out an SELinux rule was
missing.
Our TCP sockets now have TCP_NODELAY set, and we also support communicating
with a remote frida-server or frida-gadget using UNIX sockets in addition to
TCP.
NativeFunction now supports variadic functions, to avoid needing to
create one instance per unique argument list signature. Thanks @gebing!
Changes in 12.7.18
Node.js bindings finally link in needed OpenSSL symbols on UNIX, instead of
relying on luck where we’d usually end up in processes with another OpenSSL
already loaded that’s globally visible and ABI-compatible (!).
Changes in 12.7.19
We now properly handle apply() on NativeFunction w/o args in the V8 runtime
also. Kudos to @taviso for reporting this long-standing bug.
NativeFunction’s handling of optional args in call() and apply() now behaves
like the builtin counterparts.
Changes in 12.7.20
Frida now supports both cleartext and encrypted iOS lockdown channels,
retaining support for “cleartext after TLS handshake”-style channels by
appending “?tls=handshake-only” to the channel address. Kudos, @mrmacete!
The paired lockdown channel itself can be accessed by using “lockdown:” as the
channel address. Thanks @mrmacete!
Changes in 12.7.21
We now support iOS 13 on the checkra1n jailbreak. (Jailed iOS 13 was already
supported.)
Changes in 12.7.22
Our iOS package scripts launch daemon logic is now compatible with checkra1n,
so frida-server won’t have to be started/stopped manually.
Changes in 12.7.23
Enhanced support for the checkra1n jailbreak: Stalker is now way faster as it
makes use of RWX pages.
Stability improvements when using Stalker on iOS on jailbreaks without RWX
support. Thanks @mrmacete!
CModule is now compatible with additional iOS jailbreak flavors. Kudos,
@mrmacete!
CModule runtime support for working with ModuleMap objects.
Support for ARMBE8 thanks to awesome contributions by Jon Wilson.
Frida now makes parent file-descriptors available to child processes when
spawn()ing on i/macOS. This is consistent with the current behavior on Linux.
Thanks @wizche!
Changes in 12.7.24
Node.js prebuilds also provided for Node.js v13.
Changes in 12.7.25
Log handler APIs got an overhaul in the Python and Node.js bindings, as part
of a critical fix: the Node.js setter’s type wasn’t the same as the getter,
as it also allowed null. This inconsistency resulted in recent TypeScript
compiler versions choking on it. Thanks @mrmacete!
No more timestamp truncations in the V8 platform integration. Thanks for
reporting, @DaveManouchehri!
Our Module.enumerateSymbols() API provides a “size” property when available,
i.e. only on Linux/Android for now. Thanks @DaveManouchehri!
Java.use(name, { cache: ‘skip’ }) can now be used to bypass caching. Useful
when dealing with multiple class-loaders and colliding class names. Thanks
@ChaosData and @H4oK3!
Changes in 12.7.26
Stalker now supports temporary reactivation, to allow stalking code from
inside an excluded memory range.
NativeFunction got a brand new option traps: 'all' to allow calls to be
stalked even when Frida’s own memory range is marked as excluded.
Thread enumeration on Linux is finally working when using Yama. Thanks
Jon Wilson!
After a flurry of fixes across all platforms over the last few weeks,
I figured it was time to do another minor bump to call attention to
this release.
One particular fix is worth mentioning specifically. There was a long-
standing bug in our Android Java integration, where exception delivery
would intermittently result in the process crashing with
GetOatQuickMethodHeader() typically in the stack-trace. Shout-out to
Jake Van Dyke and Giovanni Rocca for helping track this one
down. This bug has been around for as long as ART has been supported,
so this fix is worth celebrating. 🎉
Our V8 runtime is also a lot more stable, child-gating works better
than ever before, Android device compatibility is much improved, etc.
So bottom line is that this is the most stable version of Frida ever
released – and now is the time to make sure you’re running Frida 12.6.
Enjoy!
Changes in 12.6.1
The exception delivery fix in the Android Java integration introduced
a performance bottleneck when running the VM in interpreter mode, e.g.
through Java.deoptimizeEverything(). For example when running the
Dropbox app from start to login screen, this would take ~94 seconds
on a Pixel 3 running Android 9, and now takes ~6 seconds.
Changes in 12.6.2
Android Java integration now supports more arm64 systems thanks to a
fix contributed by Giovanni Rocca.
Android Java integration once again supports being used by more than
one script at a time.
Changes in 12.6.3
Java.choose() is now working again on Android >= 8.1, thanks to a
fix contributed by Eugene Kolo.
Android Java integration unhooking is now working again. This also
means hooks are properly reverted on script unload.
Frida can now talk to old versions of Frida, from before the addition
of per-script runtime selection.
Changes in 12.6.4
Build system is back in business on all platforms.
Changes in 12.6.5
Linux thread enumeration is now working properly on x86-64.
Stalker finally handles restartable Linux syscalls.
Changes in 12.6.6
Android Java integration is back in fully working condition on 32-bit ARM.
Changes in 12.6.7
Latest Chimera iOS jailbreaks are now supported; confirmed working on 1.0.8.
Linux injector handles target processes where the libc’s name is ambiguous,
which is often an issue on Android.
Changes in 12.6.8
ObjC.Object now provides $moduleName, useful for determining which module
owns a given class. Kudos to David Weinstein for contributing this neat
feature!
Changes in 12.6.9
Latest unc0ver jailbreak is now fully supported.
Early instrumentation logic has been improved to fully support iOS 12. Kudos
to Francesco Tamagni for helping get these tricky changes across the
finish-line.
Enumeration of memory ranges is now more reliable on iOS 12, as memory ranges
belonging to threads are now correctly cloaked.
Cloaked memory ranges are now compacted, making lookups faster.
Child gating is able to hold children for longer than 25 seconds. Previously
these would get resumed automatically after that accidental timeout. This also
affects early instrumentation on Android, as it is built on top of child
gating.
Swift bindings support RPC and have been moved to Swift 5.0, thanks to
John Coates’ awesome contribution.
Changes in 12.6.10
Enumeration of memory ranges is now reliable on all platforms. There was a
long-standing bug when a removal ends up splitting an existing range.
Changes in 12.6.11
Enumeration of applications includes icons on iOS >= 12, thanks to a nice fix
by CodeColorist.
Gadget was taught how to detect the executable and package name of Android
apps, thanks to a neat contribution by gebing.
Cloaking of memory ranges got a critical fix affecting Windows users.
Changes in 12.6.12
The frida-inject tool now supports passing parameters to the script through
-P/–parameters. Kudos to Eugene Kolo for contributing this neat
feature.
Child-gating no longer deadlocks when script unload blocks. Kudos to
Ioannis Gasparis for helping track this one down.
Child-gating is more reliable as Frida now allocates file-descriptors in a
higher range to avoid them getting closed by applications calling dup2()
during a fork()+exec(). This would typically happen on Android when an app
called Runtime.exec(). Kudos to Ioannis Gasparis for helping track this
one down.
The painful Android NDK upgrade to r20 landed, thanks to a slew of awesome
contributions by Muhammed Ziad.
Error-handling was improved to avoid crashing in scenarios where we fail to
initialize due to lack of permissions. Kudos to pancake for reporting.
The native lockdown integration for iOS that had been sitting in a branch for
a very long time was finally merged. It is unfinished and considered unstable
API, but had to be merged due to a major refactoring that’s in progress.
Stalker now allows unfollow() from the transform callback, instead of
crashing the process like it used to. Kudos to Giovanni Rocca for helping
fix this.
Gadget’s Android package name detection logic was improved to handle one
edge-case not previously accounted for. Kudos to xiaobaiyey for reporting
and suggesting a fix.
The Java.registerClass() API was improved to support specifying the super
class, along with a slew of fixes for both that API and handling of arrays
with generics. Big thanks to gebing for these awesome improvements.
Changes in 12.6.13
Constructor/destructor functions in Agent and Gadget are now finally correctly
ordered, and our libc shim’s memory allocator hacks could be dropped. Those
fragile hacks broke in a new and colorful way with 32-bit ARM processes on
Android due to a subtle change in the toolchain’s libgcc.
Our libc shim now also handles __cxa_atexit() and atexit(), where the
former is crucial to avoid leaks.
Changes in 12.6.14
The Java.registerClass() API was improved to support user-defined
constructors and fields, thanks to the awesome improvements contributed
by gebing.
Temporary files are now cleaned up on all platforms.
Ctrl+C is handled by frida-server on Windows to support graceful shutdown
without leaving temporary files behind.
Changes in 12.6.15
NativePointerValue, i.e. support for passing an object with a handle
property in addition to NativePointer, is once again working everywhere.
Changes in 12.6.16
The frida-gadget-ios meta-package is now dependency-free.
Changes in 12.6.17
Crash reporter integration is now compatible with iOS 12.4.
Java integration was improved to eagerly release global handles when a
replaced method is called, to avoid running out of handles. Kudos to
gebing for this nice improvement.
Java.retain() was added to allow storing this for later use outside a
replaced Java method.
Support for older versions of Android should now be slightly better.
Frida no longer crashes on i/macOS if the target process dies while injecting
a library into it.
Support for MIPS64 thanks to awesome contributions by Jon Wilson.
Memory.patchCode() no longer crashes on android-arm64, thanks to a fix by
gebing.
Interception of already intercepted Thumb function is now working properly.
Frida no longer crashes when logging early in the process lifetime on iOS.
Simple ModuleApiResolver queries are now blazing fast.
Duktape runtime no longer includes the problematic Reflect builtin.
Interceptor C API was refactored to improve naming.
Changes in 12.6.18
Gadget binaries are once again stripped on all platforms.
Changes in 12.6.19
All APIs are now cancellable. Python and Node.js language bindings support
passing a Cancellable object. Remaining language bindings work like before,
and contributions are most welcome.
Changes in 12.6.20
DeviceManager.find_device() no longer crashes on startup.
Changes in 12.6.21
Future.wait_async() no longer crashes when cancelled last-minute.
Changes in 12.6.22
State management was improved to allow eternalize() and post() in disposed
state as well.
The dispose() RPC export is now passed a parameter specifying the reason,
to be able to differentiate between unload, exit, and exec.
Scripts may now be dispose()d again if an exec transition fails.
The frida-inject CLI tool was improved to exit on detach.
RpcClient no longer crashes when post_rpc_message() fails.
Fruity and Droidy backends are now disabled on iOS and Android, to reduce
footprint size on platforms where these backends are not applicable.
Changes in 12.6.23
Frida no longer crashes when HostSession gets lost mid-request.
This is one packed release. So many things to talk about.
V8
The main story this time is V8. But first, a little background.
Frida uses the Duktape JavaScript runtime by default to provide
scriptable access to its instrumentation core, Gum. We were
originally only using V8, but as V8 used to depend on operating support
for RWX pages – i.e. executable pages of memory that are also
writable – we ended up adding a secondary JS runtime based on Duktape.
Due to this OS constraint with V8, and the fact that Duktape lacks
support for the latest JS syntax and features, I decided to make Duktape
our default runtime so that scripts written for one platform wouldn’t
need any syntactic changes to work on another. Duktape was basically the
lowest common denominator.
Fast forward to today, and V8 no longer depends on OS support for RWX
pages. It’s actually moving towards flipping between RW- and R-X by
default. By doing so it means it can be used on modern iOS jailbreaks,
and also on jailed iOS if the process is marked as being debugged,
so it is able to run unsigned code. But there’s more; V8 can now even run
JIT-less, which means Frida can use V8 on every single platform, and
users no longer have to frida-compile their agents to use the latest
JavaScript syntax and features. This last point only applies to trivial
agents, though, as being able to split a non-trivial agent into multiple
source files is still desirable. Plus, frida-compile makes it easy to
use TypeScript, which is highly recommended for any non-trivial
Frida agent.
So with all of that in mind, it was clearly time to upgrade our V8 to
the latest and greatest. As of this release we are running 7.6.48,
and we also have a much deeper integration with V8 than ever before.
Both C++ memory allocations and page-level allocations are now managed
by Frida, so we are able to hide these memory ranges from APIs like
Process.enumerateRanges(), and also avoid poisoning the application’s
own heap with allocations belonging to Frida. These details may not
sound all that significant, but are actually crucial for implementing
memory-dumping tools on top of Frida. Not only that, however, we also
interfere less with the process that is being observed. That means
there’s a smaller risk of it exhibiting a different behavior than when
it runs without instrumentation.
Runtime Selection
You may remember the session.enable_jit() API. It has finally been
deprecated, as you can now specify the desired runtime during script
creation. E.g. using our Python bindings:
Another significant change in this release is that Stalker no longer
depends on RWX pages on arm64, thanks to John Coates’ awesome
contribution. This means Stalker is finally much more accessible on iOS.
For those of you using Stalker on 64-bit Windows and stalking 32-bit
processes, it finally handles the WOW64 transitions on newer versions of
Windows. This brain-twisting improvement was contributed by Florian Märkl.
Module.load()
There are times when you might want to load your own shared library,
perhaps containing hooks written in C/C++. On most platforms you could
achieve this by using NativeFunction to call dlopen() (POSIX) or
LoadLibrary() (Windows). It’s a very different story on newer versions
of Android, however, as their dlopen()-implementation looks at the
caller and makes decisions based on it. One such decision is whether
the app is trying to access a private system API, which would make it
hard for them to later remove or break that API. So as of Android 8
the implementation will return NULL when this is the case. This was
a challenge that Frida solved for its own injector’s needs, but users
wanting to load their own library were basically on their own.
As of Frida 12.5, there’s a brand new JavaScript API that takes care of
all the platform-specific quirks for you:
We fixed so many Android-specific bugs in this release. For example,
Module.getExportByName() on an app-bundled library no longer results
in the library being loaded a second time at a different base address.
This bug alone is reason enough to make sure you’ve got all your devices
upgraded and running the latest release.
iOS
The iOS Chimera jailbreak is also supported thanks to
Francesco Tamagni’s awesome contributions.
All the rest
There’s also lots of other improvements across platforms.
In chronological order:
Child gating also works on older versions of Windows.
Thanks Fernando Urbano!
Executables are smaller on UNIX OSes as they no longer export any
dynamic symbols.
Frida’s agent and gadget no longer crash on 32-bit Linux when loaded
at a high address, i.e. where MSB is set.
Only one of the two frida-helper-{32,64} binaries for Linux/Android
is needed, and none of them for builds without cross-arch support.
This means smaller footprint and improved performance.
Linux/ARM64 is finally supported, with binaries uploaded as part of
the release process.
We now provide a hint about Magisk Hide when our early instrumentation
fails to instrument Zygote on Android.
Changes in 12.5.1
Script runtime can be specified per script, deprecating enable_jit().
Changes in 12.5.2
Gadget no longer crashes at script load time when using V8 on Linux
and Android. Huge thanks to Leon Jacobs for reporting and helping
track this one down.
Changes in 12.5.3
Android linker integration supports a lot more devices.
Android Java integration no longer crashes with “Invalid instruction”
on some arm64 devices. Kudos to Jake Van Dyke for reporting and
helping track this one down.
LineageOS 15.1 is supported after adding a missing SELinux rule.
Changes in 12.5.4
Hooks are no longer able to interfere with our V8 page allocator
integration.
Android stability improved greatly after plugging a hole in our libc
shim. Big thanks to Giovanni Rocca for reporting and helping track
this one down!
Changes in 12.5.5
Apple USB devices are properly detected on Windows. Thanks @xiofee!
Changes in 12.5.6
Android Java integration now has a workaround for a bug in ART’s
exception delivery logic, where one particular code-path assumes that
there is at least one Java stack frame present on the current thread.
That is however not the case on a pure native thread, like Frida’s JS
thread. Simplest reproducer is Java.deoptimizeEverything() followed
by Java.use() of a non-existent class name. Kudos to
Jake Van Dyke for reporting and helping track this one down.
Android Java integration no longer crashes the process when calling
Java.deoptimizeEverything() in a process unable to TCP listen().
Android Java integration supports JNI checked mode like it used to.
Node.js 12 supported in addition to 8 and 10, with prebuilds for all
supported platforms.
Node.js bindings’ enableDebugger() method no longer requires
specifying which port to listen on.
Changes in 12.5.7
Android teardown no longer crashes on systems where we are unable to
spawn logcat for crash reporting purposes.
Better SuperSU integration teardown logic on Android.
Android Java integration now properly supports JNI checked mode, which
massively improves Android ROM compatibility. Kudos to @muhzii for
reporting and assisting with testing the changes.
V8 backend teardown no longer suffers from a use-after-free, and also
no longer crashes when a WeakRef is bound late.
Changes in 12.5.8
Linux child-gating now handles children changing architecture, e.g. a
32-bit app doing fork+exec to run a 64-bit executable. Big thanks to
@gebing for the fix.
Child gating no longer deadlocks in case of a fork+exec where a child
process is not followed. Kudos to @gebing for the fix.
Module export lookups no longer fail on Android apps’ own modules.
Changes in 12.5.9
Our libc shim now includes memcpy(), making it safe to hook. Thanks to
Giovanni Rocca for debugging and contributing the fix.
Interceptor.flush() now also works even when a thread has temporarily
released the JS lock, e.g. while calling a NativeFunction.
Android Java integration no longer crashes intermittently during ART
exception delivery, e.g. when hooking ClassLoader.loadClass(). Kudos
to Jake Van Dyke and Giovanni Rocca for helping track this one
down. This bug has been around for as long as ART has been supported,
so this fix is worth celebrating. 🎉
Android Java integration no longer crashes processes where the JDWP
transport cannot be started.
Let’s talk about iOS kernel introspection. It’s been a while since Frida got
basic support for introspection of the iOS kernel, but in the last months we
kept improving on that. Today’s release includes significant additions to our
Kernel API to work with recent 64-bit kernels.
Kernel base
You can get the kernel’s base address by reading the Kernel.base property.
Having the base allows for example to calculate the slid virtual address of
any symbol you already know from static analysis of the kernel cache.
Kernel memory search
The memory search API has been ported to the Kernel, so you can use
Kernel.scan() (or Kernel.scanSync()) in the same way you use Memory.scan()
(or Memory.scanSync()) in userland. This is a powerful primitive which,
combined with the recent bit mask feature, allows you to create your own symbol
finding code by searching for arm64 patterns.
KEXTs and memory ranges
With Kernel.enumerateModules() (or Kernel.enumerateModulesSync()) it’s now
possible to get the names and the offsets of all the KEXTs.
Kernel.enumerateModuleRanges() (or Kernel.enumerateModuleRangesSync()) is
the way to enumerate all the memory ranges defined by the Mach-O sections
belonging to a module (by name) filtering by protection. The result is similar
to what you can get in userland when calling Module.enumerateRanges() but it
also includes the section names.
Final notes
All Kernel APIs don’t rely on NativePointer because its size depends on the
user-space which doesn’t necessarily match the kernel space one. Instead all
addresses are represented as UInt64 objects.
All of this, plus the existing JavaScript interfaces for reading, writing, and
allocating kernel memory can provide a powerful starting point to build your own
kernel analysis or vulnerability research tools.
Note that this is to be considered experimental and messing with the kernel in
random ways can wildly damage your devices, so be careful, and happy hacking!
Troubleshooting
Problem: Kernel.available is false
The Kernel API is available if both of these conditions are met:
Your device is jailbroken
Frida is able to get a send right to the kernel task, either by traditional
task_for_pid (0) or by accessing the host special port 4 (which is what
modern jailbreaks are doing)
The recommended way to accomplish the latter is to attach to the system session,
i.e. PID 0, and load your scripts there.
Problem: can’t do much with my 32-bit kernel
Yes, that could improve in the future but 32-bit iOS is quite far down on the
list of priorities nowadays, but you’re very welcome to contribute and send PRs.
Problem: I was trying to do X and the kernel panicked
Don’t worry that’s normal. You can go to the
/private/var/mobile/Library/Logs/CrashReporter directory on your device, or
navigate to Settings -> Privacy -> Analytics -> Analytics Data, find your panic
log and figure out what you (or Frida) did wrong. Remember: the Kernel is always
right!
Problem: I unrecoverably damaged my device using Frida Kernel APIs
Sorry to hear, if the damage is at the hardware level and you can dedicate
enough time and money you can probably repair it yourself by following tutorials
at https://ifixit.com.
Massive changes under the hood this time. All of our dependencies have been
upgraded to the latest and greatest. Let’s have a look at the highlights.
V8 7.0
Frida’s V8 dependency was previously at 6.2.2, and has now been upgraded to
7.0.242. The move to such a new version means that the V8 debugger API is gone
and has been replaced with the new Inspector API, which the latest Node.js is
also using. One thing that’s pretty awesome about it is that it’s natively
supported by Google Chrome’s Inspector.
To start using it, just tell Frida to use V8, by calling session.enable_jit(),
and then session.enable_debugger().
Then in Google Chrome, right-click and choose “Inspect”, and click on the green
Node.js icon in the upper left corner of the Inspector. That’s it, you are now
debugging your Frida scripts. That means a nifty console with auto-completion,
pause/continue, stepping, breakpoints, profiling, and heap snapshots. What makes
it really convenient is that the server listens on your host machine, so you can
call enable_debugger() on a session representing a process on your
USB-tethered Android device, and it all works the same.
Here’s what it looks like:
Note however that V8 is currently not included in our prebuilt iOS binaries,
but it should be possible to get it running again on iOS now that it’s able to
run without RWX pages. We do however plan on bridging Duktape’s binary debugger
protocol behind the scenes so debugging “just works” with Duktape also, though
probably with a slightly reduced feature-set.
Process.id
It is often quite useful to know the PID of the process that your agent is
executing inside, especially in preloaded mode. So instead of requiring you
to use NativeFunction to call e.g. getpid(), this is now a lot simpler as
you can use the brand new Process.id property.
Anything else?
No other features, but some really nice bug-fixes. Thanks to mrmacete we are
now able to attach to com.apple.WebKit.* processes on iOS 11.x. And thanks to
viniciusmarangoni this release also packs a couple of goodies for frida-java,
fixing one Android 8.0 regression and adding the ability to properly instrument
system_server.
As some of you may have picked up on, there may be a book on Frida in the
works. In my day to day at NowSecure I spend a good chunk of time as a user
of Frida’s APIs, and consequently I’m often reminded of past design decisions
that I’ve since come to regret. Even though I did address most of them over the
years, some were so painful to address that I kept them on the backburner. Fast
forward to today, and the thought of publishing a book with all these in mind
got me thinking that it was time to bite the bullet.
This is why I’m stoked to announce Frida 12. We have finally reached a point
in Frida’s evolution where our foundations can be considered sufficiently stable
for a book to be written.
Let’s have a look at the changes.
CLI tools
One thing that caused a bit of confusion in the past was the fact that our
Python bindings also came with some CLI tools. Frida is a toolkit for building
tools, and even though we provide a few sample tools it should be up to you if
you want to have them installed.
Up until now this meant anyone building a tool using our Python bindings would
end up depending on colorama, prompt-toolkit, and pygments, because our
CLI tools happen to depend on those.
Well, that changes now. If you do:
$ pip install frida
You will now only get our Python bindings. Nothing more. And this package has
zero dependencies.
The CLI tools might still be useful to you, though, so to install those do:
$ pip install frida-tools
Convenience APIs in bindings
Something that seemed like a great idea at the time was having our language
bindings provide some convenience APIs on the Session object. The thinking
was that simple use-cases that only need to enumerate loaded modules and perhaps
a few memory ranges, to then read or write memory, wouldn’t have to load their
own agent. So both our Python and our Node.js bindings did this behind the
scenes for you.
Back then it was somewhat tedious to communicate with an agent as the rpc
API didn’t exist, but even so, it was a bad design decision. The JS APIs
are numerous and not all can be exposed without introducing new layers of
complexity. Another aspect is that every language binding would have to
duplicate such convenience APIs, or we would have to add core APIs that
bindings could expose. Both are terrible options, and cause confusion by
blurring the lines, ultimately confusing people new to Frida. Granted, it did
make things easier for some very simple use-cases, like memory dumping tools,
but for everybody else it just added bloat and confusion.
These APIs are now finally gone from our Python and Node.js bindings. The other
bindings are unaffected as they didn’t implement any such convenience APIs.
Node.js bindings
It’s been a few years since our Node.js bindings were written, and since then
Node.js has evolved a lot. It now supports ES6 classes, async / await, arrow
functions, Proxy objects, etc.
Just the Proxy support alone means we can simplify rpc use-cases like:
Some of you may also prefer writing your application in TypeScript, which
is an awesome productivity boost compared to old-fashioned JavaScript. Not only
do you get type checking, but if you’re using an editor like VS Code you
also get type-aware refactoring and amazing code completion.
However, for type checking and editor features to really shine, it is crucial to
have type definitions for your project’s dependencies. This is rarely ever an
issue these days, except for those of you using Frida’s Node.js bindings.
Up until now we didn’t provide any type definitions. This has finally been
resolved. Rather than augmenting our bindings with type definitions, I decided
to rewrite them in TypeScript instead. This means we also take advantage of
modern language features like ES6 classes and async / await.
We could have stopped there, but those of you using our Node.js bindings from
TypeScript would still find this a bit frustrating:
Here, the compiler knows nothing about which events exist on the Script
object, and what the callback’s signature is supposed to be for this particular
event. We’ve finally fixed this. The API now looks like this:
script.message.connect((message,data)=>{});
Voilà. Your editor can even tell you which events are supported and give you
proper type checking for the code in your callback. Sweet!
Interceptor
Something that’s caused some confusion in the past is the observation that
accessing this.context.pc from onEnter or onLeave would give you the
return address, and not the address of the instruction that you put the hook
on. This has finally been fixed. Also, this.context.sp now points at the
return address on x86, instead of the first argument. The same goes for
Stalker when using call probes.
As part of this refactoring breaking our backtracer implementations, I also
improved our default backtracer on Windows.
Tether?
You might have wondered why frida.get_usb_device() would give you a Device
whose type was ‘tether’. It is now finally ‘usb’ as you’d expect. So our
language bindings are finally consistent with our core API.
Changes in 12.0.1
core: fix argument access on 32-bit x86
core: update Stalker to the new CpuContext semantics
python: publish the correct README to PyPI
python: fix the Windows build system
Changes in 12.0.2
core: upgrade to Capstone’s next branch
core: fix the DbgHelp backtracer on Windows and update to latest DbgHelp
python: fix long description
java: fix hooking of java.lang.Class.getMethod() – thanks 0x3430D!
Changes in 12.0.3
core: fix the iOS build system broken by Capstone upgrade
Changes in 12.0.4
core: fix i/macOS libc++ initialization on early instrumentation
– thanks mrmacete!
core: add support for memory search with mask – thanks mrmacete!
core: fix InvocationContext.get_return_address()
node: fix crash on RPC object return from an async function
Changes in 12.0.5
core: fix arm64 crashes caused by Capstone upgrade, where test-and-branch
decoding logic failed to decode negative offsets – kudos to
mrmacete for discovering and fixing this one!
It’s time to overhaul the spawn() API and fix some rough edges in the spawn-
and child-gating APIs.
spawn()
Say you’re using Frida’s Python bindings, you’d currently do:
pid=device.spawn(["/bin/cat","/etc/passwd"])
Or to spawn an iOS app:
pid=device.spawn(["com.apple.mobilesafari"])
Well, that’s pretty much all you could do with that API really… except one
thing that wasn’t exposed by the Python and Node.js bindings. We’ll get to
that in a bit. Before we go there, let’s take a look at the underlying API
in frida-core, which these bindings expose to different languages:
That’s Vala code by the way, which is the language that frida-core is
written in. It’s a C#-like language that compiles to C, and it’s pretty awesome.
But I digress. The first method, spawn() is asynchronous, allowing the calling
thread to do other things while the call is in progress, whereas spawn_sync()
blocks until the operation completes.
Those two methods compile down to the following three C functions:
The first two constitute spawn(), where you’d call the first giving it a
callback, and once that callback gets called you’d call the second one,
spawn_finish(), giving it the GAsyncResult your callback was given.
The return value is the PID, or, in case it failed, the error out-argument
explains what went wrong. This is the GIO async pattern in case you’re
curious.
As for the third, spawn_sync(), this is what Frida’s Python bindings use.
Our Node.js bindings actually use the first two, as those bindings are fully
asynchronous. Someday it would be nice to also migrate our Python bindings to
be fully async, by integrating with the async/await support introduced in
Python 3.5.
Anyway, returning to the examples above, I mentioned there was something not
exposed. If you look closely at the frida-core API you’ll notice that there’s
the envp string-array. Peeking under the hood of the bindings, you’d realize
we did indeed not expose this, and we actually did this:
So that means we passed along whatever the Python process’ environment happened
to be. That’s definitely not good if the actual spawning happened on another
system entirely, like on a connected iOS or Android device. What made this
slightly less problematic was the fact that envp was ignored when spawning
iOS and Android apps, and only used when spawning regular programs.
Another issue with this old API is that the declaration, string[] envp, means
it isn’t nullable, which it would have been if the declaration had been:
string[]? envp. That means there is no way to distinguish between wanting to
spawn without any environment, which intuitively would mean “use defaults”, and
an empty environment.
As I was about to fix this aspect of the API, I realized that it was time to
also fix a few other long-standing issues with it, like being able to:
provide just a few extra environment variables on top of the defaults
set the working directory
customize stdio redirection
pass along platform-specific options
Up until this point we have always redirected stdio to our own pipes, and
streamed any output through the output signal on Device. There was also
Device.input() for writing to stdin. Those APIs are still the same, the
only difference is that we no longer do such redirection by default. Most of
you were probably not too bothered with this, though, as we didn’t implement
such redirection for iOS and Android apps. Starting with this release we do
however finally implement it for iOS apps.
By now you’re probably wondering what the new API looks like. Let’s have a look:
So going back to the Python examples at the beginning, those still work without
any changes. But, instead of:
device.spawn(["com.apple.mobilesafari"])
You can now also do:
device.spawn("com.apple.mobilesafari")
As the first argument is the program to spawn. You can still pass an argv
here and that will be used to set the argv option, meaning that argv[0] will
be used for the program argument. You can also do this:
And if you’d like to replace the entire environment instead of using defaults:
device.spawn("/bin/ls",envp={"CLICOLOR":"1"})
Though in most cases you probably only want to add/override a few environment
variables, which is now also possible:
device.spawn("/bin/ls",env={"CLICOLOR":"1"})
You might also want to use a different working directory:
device.spawn("/bin/ls",cwd="/etc")
Or perhaps you’d like to redirect stdio:
device.spawn("/bin/ls",stdio="pipe")
The stdio default value is inherit, as mentioned earlier.
We have now covered all of the SpawnOptions, except the last of them: aux.
This is a dictionary for platform-specific options. Setting such options is
pretty simple with the Python bindings: any keyword-argument not recognized
will end up in that dictionary.
For example, to launch Safari and tell it to open a specific URL:
So as you can see, the second argument is an object with options, and those not
recognized end up in the aux dictionary.
Remaining changes in 11.0.0
Let’s just summarize the remaining changes, starting with the Device class:
enumerate_pending_spawns() is now enumerate_pending_spawn() to be
grammatically correct.
The spawned signal has been renamed to spawn-added, and there is now also
spawn-removed.
The delivered signal has been renamed to child-added, and there is now
also child-removed.
The final change is that the Child class’ path, argv, and envp
properties are now all nullable. This is to be able to discern e.g. “no envp
provided” from “empty envp provided”.
Changes in 11.0.1
core: fix stack alignment of agent thread for 32-bit ARM processes
core: fix fragile SELinux rule patching
Changes in 11.0.2
core: plug Mach ports leaks in spawn()-logic on i/macOS (long-standing issue)
Changes in 11.0.3
core: fix crash on iPhone 8 and X caused by bad tls_base calculation on arm64
Changes in 11.0.4
python: update metadata and bump requirements
Changes in 11.0.5
core: fix compatibility issue with Electra’s Tweak Injector
core: fix process name truncation in enumerate_processes() on iOS
java: Java.registerClass() now supports overloads
packaging: every new release now comes with packages for Fedora and Ubuntu
Changes in 11.0.6
python: fix dependency spec so REPL works again when installed from PyPI
Changes in 11.0.7
core: better child gating API coverage on Windows
python: 2.7 binaries for Linux are no longer broken when installed from PyPI
Changes in 11.0.8
core: fix race resulting in crash on system session setup on some platforms
python: fix deadlock on interpreter shutdown
Changes in 11.0.9
java: fix issue preventing Java.registerClass() during early instrumentation
Changes in 11.0.10
core: fix crash when enumerating imports/exports of ELF modules with an empty
DT_GNU_HASH
Changes in 11.0.11
java: fix type compatibility checking, which typically resulted in the wrong
overload getting called, in turn causing the VM to abort()
Changes in 11.0.12
core: fix compatibility issues with the latest macOS Mojave and iOS 12 betas
core: improve the iOS Kernel API available in the system session, i.e. PID 0
frida-trace: fix crash when tracer scripts send() arbitrary data
Changes in 11.0.13
core: fix hang on teardown of script that was never load()ed
EOF
So that’s about it. If you didn’t read about the Frida 10.8 release that
happened last week, make sure you go read about it here.
Get ready for a major upgrade. This time we have solved our three longest
standing limitations – all in one release.
Limitation #1: fork()
As a quick refresher, this old-school UNIX API clones the entire process and
returns the child’s process ID to the parent, and zero to the child. The child
gets its own copy of the parent’s address space, usually at a very small cost
due to copy-on-write.
Dealing with this one gets tricky once multiple threads are involved. Only the
thread calling fork() survives in the child process, so if any of the other
threads happen to be holding locks, those locks will still be held in the child,
and nobody is going to release them.
Essentially this means that any application doing both forking and
multi-threading will have to be really carefully designed. Even though most
applications that fork are single-threaded, Frida effectively makes them
multi-threaded by injecting its agent into them. Another aspect is
file-descriptors, which are shared, so those also have to be carefully managed.
I’m super-excited to announce that we are finally able to detect that a fork()
is about to happen, temporarily stop our threads, pause our communications
channel, and start things back up afterwards. You are then able to apply the
desired instrumentation to the child, if any, before letting it continue
running.
Limitation #2: execve(), posix_spawn(), CreateProcess(), and friends
Or in plain English: programs that start other programs, either by replacing
themselves entirely, e.g. execve(), or by spawning a child process, e.g.
posix_spawn() without POSIX_SPAWN_SETEXEC.
Just like after a fork() happened you are now able to apply instrumentation
and control when the child process starts running its first instructions.
Limitation #3: dealing with sudden process termination
An aspect that’s caused a lot of confusion in the past is how one might hand off
some data to Frida’s send() API, and if the process is about to terminate,
said data might not actually make it to the other side.
Up until now the prescribed solution was always to hook exit(), abort() etc.
so you can do a send() plus recv().wait() ping-pong to flush any data still
in transit. In retrospect this wasn’t such a great idea, as it makes it hard to
do this correctly across multiple platforms. We now have a way better solution.
So with that, let’s talk about the new APIs and features.
Child gating
This is how we address the first two. The Session object, the one providing
create_script(), now also has enable_child_gating() and
disable_child_gating(). By default Frida will behave just like before, and
you will have to opt-in to this new behavior by calling enable_child_gating().
From that point on, any child process is going to end up suspended, and you will
be responsible for calling resume() with its PID. The Device object now also
provides a signal named delivered which you should attach a callback to in
order to be notified of any new children that appear. That is the point where
you should be applying the desired instrumentation, if any, before calling
resume(). The Device object also has a new method named
enumerate_pending_children() which can be used to get a full list of pending
children. Processes will remain suspended and part of that list until they’re
resumed by you, or eventually killed.
So that’s the theory. Let’s have a look at a practical example, using
Frida’s Python bindings:
As for the third limitation, namely dealing with sudden process termination,
Frida will now intercept the most common process termination APIs and take
care of flushing any pending data for you.
However, for advanced agents that optimize throughput by buffering data and only
doing send() periodically, there is now a way to run your own code when the
process terminates, or the script is unloaded. All you need to do is to define
an RPC export named dispose. E.g.:
rpc.exports={dispose(){send(bufferedData);}};
In closing
Building on the brand new fork()-handling in Frida, there is also a fully
reworked Android app launching implementation. The frida-loader-{32,64}.so
helper agents are now gone, and our behind-the-scenes Zygote instrumentation
is now leveraging the brand new child gating to do all of the heavy lifting.
This means you can also instrument Zygote for your own needs. Just remember to
enable_child_gating() and resume() any children that you don’t care about.
iOS users rejoice: Frida is now compatible with the latest Electra
jailbreak on iOS 11! At the time of this writing that means 1.0.4, but
now that Electra seems to have stabilized it should be safe to assume
that we’ll also be compatible with future updates. Just make sure you’re
not running anything older than 1.0.4.
In other news, our Android support has improved significantly over the
last releases, so if you’re even slightly behind: go grab the latest
10.7.x right away.
This component is really useful when dealing with jailed iOS and Android
devices, but is now also able to cover a lot of other scenarios.
Its environment variables are now gone, and have been replaced by an optional
configuration file. Because some apps may look for loaded libraries with “Frida”
in their name as part of their “anti-debug” defenses, we now allow you to rename
Gadget’s binary however you like. Along with this it now also supports three
different interaction types.
It can listen on a TCP port, like before, and it can also load scripts from the
filesystem and run fully autonomously. The latter part used to be really limited
but is now really flexible, as you can even tell it to load scripts from a
directory, where each script may have filters. This is pretty useful for
system-wide tampering, and should allow for even more interesting use-cases.
So without further ado, I would urge you all to check out the brand new docs
available here.
The midnight oil has been burning and countless cups of coffee have been
consumed here at NowSecure, and boy do we have news for you this time.
Continuing in the spirit of last release’ low-level bag of goodies, we’ll be
moving one level up the stack this time. We are going to introduce a brand new
way to use new CodeWriter APIs, enabling you to weave in your own instructions
into the machine code executed by any thread of your choosing. We’re talking
lazy dynamic recompilation on a per-thread basis, with precise control of the
compilation process.
But first a little background. Most people using Frida are probably using the
Interceptor API to perform inline hooking, and/or doing method swizzling or
replacement through the ObjC and Java APIs. The idea is typically to
modify some interesting API that you expect to be called, and be able to divert
execution to your own code in order to observe, augment, or fully replace
application behavior.
One drawback to such approaches is that code or data is modified, and such
changes can be trivially detected. This is fine though, as being invisible to
the hosting process’ own code is always going to be a cat and mouse game when
doing in-process instrumentation.
These techniques are however quite limited when trying to answer the question
of “behind this private API, which other APIs actually get called for a given
input?”. Or, when doing reversing and fuzzing, you might want to know where
execution diverges between two known inputs to a given function. Another example
is measuring code coverage. You could use Interceptor’s support for
instruction-level probes, first using a static analysis tool to find all the
basic blocks and then using Frida to put single-shot probes all over the place.
Enter Stalker. It’s not a new API, but it’s been fairly limited in what it
allowed you to do. Think of it as a per-thread code-tracer, where the thread’s
original machine code is dynamically recompiled to new memory locations in
order to weave in instrumentation between the original instructions.
It does this recompilation lazily, one basic-block at a time. Considering that
a lot of self-modifying code exists, it is careful about caching compiled blocks
in case the original code changes after the fact.
Stalker also goes to great lengths to recompile the code such that
side-effects are identical. E.g. if the original instruction is a CALL it will
make sure that the address of the original next instruction is what’s pushed on
the stack, and not the address of the next recompiled instruction.
Anyway, Stalker has historically been like a pet project inside of a pet
project. A lot of fun, but other parts of Frida received most of my attention
over the years. There have been some awesome exceptions though. Me and
@karltk did some fun pair-programming sessions many years ago when we
sat down and decided to get Stalker working well on hostile code. At some
later point I put together CryptoShark in order get people excited about its
potential. Some time went by and suddenly Stalker received a critical bug-fix
contributed by Eloi Vanderbeken. Early this year, Antonio Ken Iannillo
jumped on board and ported it to arm64. Then, very recently, Erik Smit
showed up and fixed a critical bug where we would produce invalid code for
REP-prefixed JCC instructions. Yay!
Stalker’s API has so far been really limited. You can tell it to follow a
thread, including the thread you’re in, which is useful in combination with
inline hooking, i.e. Interceptor. The only two things you could do was:
Tell it which events you’re interested in, e.g. call: true, which will
produce one event per CALL instruction. This means Stalker will add some
logging code before each such instruction, and that would log where the
CALL happened, its target, and its stack depth. The other event types are
very similar.
Add your own call probes for specific targets, giving you a synchronous
callback into JavaScript when a CALL is made to a specific target.
I’m super-excited to announce that we’ve just introduced a third thing you
can do with this API, and this one is a game changer. You can now customize
the recompilation process, and it’s really easy:
The transform callback gets called synchronously whenever a new basic block
is about to be compiled. It gives you an iterator that you then use to drive
the recompilation-process forward, one instruction at a time. The returned
Instruction tells you what you need to know about the instruction that’s
about to be recompiled. You then call keep() to allow Stalker to recompile
it as it normally would. This means you can omit this call if you want to skip
some instructions, e.g. because you’ve replaced them with your own code. The
iterator also allows you to insert your own instructions, as it exposes the full
CodeWriter API of the current architecture, e.g. X86Writer.
The example above determines where the application’s own code is in memory, and
adds a few extra instructions before every RET instruction in any code belonging
to the application itself. This code checks if eax contains a value between 60
and 90, and if it does, calls out to JavaScript to let it implement arbitrarily
complex logic. This callback can read and modify registers as it pleases.
What’s nice about this approach is that you can insert code into hot code-paths
and selectively call into JavaScript, making it easy to do really fast checks in
machine code but offload more complex tasks to a higher level language. You can
also Memory.alloc() and have the generated code write directly there, without
entering into JavaScript at all.
So that’s the big new thing in 10.5. Special thanks to @asabil who helped
shape this new API.
In closing, the only other big change is that the Instruction API now exposes
a lot more details of the underlying Capstone instruction. Stalker also
uses a lot less memory on both x86 and arm64, and is also more reliable. Lastly,
Process.setExceptionHandler() is now a documented API, along with our
SQLite API.
Frida provides quite a few building blocks that make it easy to do portable
instrumentation across many OSes and architectures. One area that’s been lacking
has been in non-portable use-cases. While we did provide some primitives like
Memory.alloc(Process.pageSize) and Memory.patchCode(), making it possible to
allocate and modify in-memory code, there wasn’t anything to help you actually
generate code. Or copy code from one memory location to another.
Considering that Frida needs to generate and transform quite a bit of machine
code for its own needs, e.g. to implement Interceptor and Stalker, it should
come as no surprise that we already have C APIs to do these things across six
different instruction set flavors. Initially these APIs were so barebones that I
didn’t see much value in exposing them to JavaScript, but after many years of
interesting internal use-cases they’ve evolved to the point where the essential
bits are now covered pretty well.
So with 10.4 we are finally exposing all of these APIs to JavaScript. It’s also
worth mentioning that these new bindings are auto-generated, so future additions
will be effortless.
Let’s take a look at an example on x86:
constgetLivesLeft=Module.getExportByName('game-engine.so','get_lives_left');constmaxPatchSize=64;// Do not write out of bounds, may be// a temporary buffer!Memory.patchCode(getLivesLeft,maxPatchSize,code=>{constcw=newX86Writer(code,{pc:getLivesLeft});cw.putMovRegU32('eax',9999);cw.putRet();cw.flush();});
Which means we replaced the beginning of our target function with simply:
moveax,9999ret
I.e. assuming the return type is int, we just replaced the function body with
return 9999;.
As a side-note you could also use Memory.protect() to change the page
protection and then go ahead and write code all over the place, but
Memory.patchCode() is very handy because it also
ensures CPU caches are flushed;
takes care of code-signing corner-cases on iOS.
So that was a simple example. Let’s try something a bit crazier:
Though that’s quite a few hoops just to multiply 42 by 7, the idea is to
illustrate how calling functions, even back into JavaScript, and jumping to
labels, is actually quite easy.
Finally, let’s look at how to copy instructions from one memory location to
another. Doing this correctly is typically a lot more complicated than a
straight memcpy(), as some instructions are position-dependent and need to
be adjusted based on their new locations in memory. Let’s look at how we can
solve this with Frida’s new relocator APIs:
We just made our own replica of puts() in just a few lines of code. Neat!
Note that you can also insert your own instructions, and use skipOne() to
selectively skip instructions in case you want to do custom instrumentation.
(This is how Stalker works.)
Anyway, that’s the gist of it. You can find the brand new API references at:
Also note that Process.arch is convenient for determining which
writer/relocator to use. On that note you may wonder why there’s just a single
implementation for 32- and 64-bit x86. The reason is that these instruction sets
are so close that it made sense to have a unified implementation. This also
makes it easier to write somewhat portable code, as some meta register-names are
available. E.g. xax resolves to eax vs rax depending on the kind of
process you are in.
This time we’re kicking it up a notch. We’re bringing you stability
improvements and state of the art JavaScript support.
Let’s talk about the stability improvements first. We fixed a heap
corruption affecting all Linux users. This one was particularly hard to
track down, but rr saved the day. The other issue was a crash on
unload in the Duktape runtime, affecting all OSes.
Dependencies were also upgraded, so as of Frida 10.0.0 you can now enjoy
V8 6.0.124, released just days ago. We also upgraded Duktape to the
latest 2.1.x. The Duktape upgrade resulted in slight changes to the
bytecode semantics, which meant we had to break our API slightly.
Instead of specifying a script’s name at load time, it is now specified
when compiling it to bytecode, as this metadata is now included in the
bytecode. This makes a lot more sense, so it was a welcome change.
Beside V8 and Duktape we’re also using the latest GLib, Vala compiler,
etc. These upgrades also included JSON-GLib, which recently ditched
autotools in favor of Meson. This is excellent news, as we’re also
planning on moving to Meson down the road, so we’ve now done the
necessary groundwork for making this happen.
So that’s about it. This upgrade should not require any changes to
existing code – unless of course you are among the few using the
bytecode API.
Some big changes this time. We now use our Duktape-based JavaScript runtime
by default on all platforms, iOS app launching no longer piggybacks on Cydia
Substrate, and we are bringing some massive performance improvements. That, and
some bugfixes.
Let’s talk about Duktape first. Frida’s first JS runtime was based on V8,
and I’m really happy about that choice. It is however quite obvious that there
are use-cases where it is a bad fit.
Some systems, e.g. iOS, don’t allow RWX memory1,
and V8 won’t run without that. Another example is resource-constrained embedded
systems where there just isn’t enough memory. And, as reported by users from
time to time, some processes decide to configure their threads to have tiny
stacks. V8 is however quite stack-hungry, so if you hook a function called by
any of those threads, it won’t necessarily be able to enter V8, and your hooks
appear to be ignored2.
Another aspect is that V8 is way more expensive than Duktape for the native ⇔
JS transitions, so if your Frida agent is all about API hooks, and your hooks
are really small, you might actually be better off with Duktape. Garbage
collection is also more predictable with Duktape, which is good for hooking
time-sensitive code.
That said, if your agent is heavy on JavaScript, V8 will be way faster. It also
comes with native ES6 support, although this isn’t too big a deal since
non-trivial agents should be using frida-compile, which compiles your code
to ES5.
So the V8 runtime is not going away, and it will remain a first-class citizen.
The only thing that’s changing is that we pick Duktape by default, so that you
are guaranteed to get the same runtime on all platforms, with a high probability
that it’s going to work.
However, if your use-case is JS-heavy, all you have to do is call
Session#enable_jit() before the first script is created, and V8 will be used.
For our CLI tools you may pass –enable-jit to get the same effect.
That was Duktape. What’s the story about app launching and Substrate, then?
Well, up until now our iOS app launching was piggybacking on Substrate. This was
a pragmatic solution in order to avoid going into interoperability scenarios
where Frida and Substrate would both hook posix_spawn() in launchd and
xpcproxy, and step on each other.
It was however on my long-term TODO to fix this, as it added a lot of complexity
in other areas. E.g. an out-of-band callback mechanism so our Substrate plugin
could talk back to us at load time, having to manage temporary files, etc.
In addition to that, it meant we were depending on a closed source third-party
component, even though it was a soft-dependency only needed for iOS app
launching. But still, it was the only part of Frida that indirectly required
permanent modifications to the running system, and we really want to avoid
that.
Let’s have a look at how the new app launching works. Imagine that you ran
this on your host machine that’s got a jailbroken iOS device connected to it
over USB:
$ frida-trace -U-f com.atebits.Tweetie2 -i open
We’re telling it to launch Twitter’s iOS app and trace functions named open.
As a side-note, if you’re curious about the details, frida-trace is written in
Python and is less than 900 lines of code, so it might be a good way to
learn more about building your own tools on top of Frida. Or perhaps you’d
like to improve frida-trace? Even better!
The first part that it does is that it gets hold of the first USB device and
launches the Twitter app there. This boils down to:
Our launchd.js agent then intercept launchd’s __posix_spawn() and adds
POSIX_SPAWN_START_SUSPENDED, and signals back the identifier and PID.
This is the /usr/libexec/xpcproxy helper that will perform an exec()-style
transition to become the app.
We then inject our xpcproxy.js agent into this so it can hook
__posix_spawn() and add POSIX_SPAWN_START_SUSPENDED just like our launchd
agent did. This one will however also have POSIX_SPAWN_SETEXEC, so that
means it will replace itself with the app to be launched.
We resume() the xpcproxy process and wait for the exec to happen and the
process to be suspended.
At this point we let the device.spawn() return with the PID of the app that
was just launched. The app’s process has been created, and the main thread is
suspended at dyld’s entrypoint. frida-trace will then want to attach to it
so it can load its agent that hooks open. So it goes ahead and does something
similar to this:
Now that it has applied the instrumentation, it will ask Frida to resume
the process so the main thread can call main() and have some fun:
device.resume(pid)
Note that I did skip over a few details here, as the attach() operation is
actually a bit more complicated due to how uninitialized the process is, but
you can read more about that here.
Finally, let’s talk about footprint and performance. First, let’s examine how
much disk space is required when Frida is installed on an iOS device and is
in a fully operational state:
That’s the 64-bit version, which is only 1.87 MB xz-compressed. The 32-bit
version is obviously even smaller. Quite a few optimizations at play here:
We used to write the frida-helper binary out to a temporary file and spawn it.
The meat of the frida-helper program is now statically linked into
frida-server, and its entitlements have been boosted along with it. This
binary is only necessary when Frida is used as a plugin in an unknown process,
i.e. where we cannot make any guarantees about entitlements and code-signing.
In the frida-server case, however, it is able to guarantee that all such
constraints are met.
The library that we inject into processes to be instrumented,
frida-agent.dylib, is no longer written out to a temporary file. We use
our own out-of-process dynamic linker to map it from frida-server’s memory
and directly into the address space of the target process. These mappings
are made copy-on-write, so that means it is as memory-efficient as the old
dlopen() approach was.
V8 was disabled for the iOS binaries as it’s only really usable on old
jailbreaks where the kernel is patched to allow RWX pages.
(If V8 is important to your use-case, you can build it like this:
make server-ios FRIDA_DIET=no)
The iOS package has been split into two, “Frida” for 64-bit devices, and
“Frida for 32-bit devices” for old devices.
Getting rid of the Substrate dependency for iOS app launching also meant
we got rid of FridaLoader.dylib. This is however a very minor improvement.
Alright, so that’s disk footprint. How about memory usage?
Nice. How about performance? Let’s have a look:
Note that these measurements include the time spent communicating from the
macOS host to the iOS device over USB.
Enjoy!
1 Except if the process has an entitlement, although that’s
limited to just one region. ↩
2: It is technically possible to work around this by
having a per-thread side-stack that we switch to before calling into V8. We
did actually have this partially implemented in the past. Might be something
we should revive in the longer term. ↩
It’s time for a release, and this time we have some big new things for those of
you building Frida-based tools, plus a few additional goodies. Let’s start with
the first part.
There’s no doubt that Frida’s JavaScript API is fairly low-level and only
meant to provide low-level building blocks that don’t pertain to just one
specific use-case. If your use-case involves grabbing screenshots on iOS, for
example, this is not functionality one would expect to find in Frida itself.
You may then wonder how different tools with common features are supposed to
share agent code with each other, and luckily the answer is not “copy paste”.
We have a growing ecosystem of Frida-specific libraries, like
frida-screenshot, frida-uikit, frida-trace, etc.
Perhaps some of you would be interested in APIs for instrumenting backend
software written in Java, .NET, Python, Ruby, or Perl, or perhaps you would want
to trace crypto APIs across different OSes and libraries, or some other cool
idea. I would then highly recommend that you publish your module to npm, perhaps
naming your module frida-$name to make it easy to discover.
Now you might be asking “but Frida does not support require(), how can I even
split my agent code into multiple files in the first place?”. I’m glad you
asked! This is where a handy little CLI tool called frida-compile enters
the picture.
You give it a .js file as input and it will take care of bundling up any other
files it depends on into just one file. But unlike a homegrown concatenation
solution using cat, the final result also gets an embedded source map, which
means filenames and line numbers in stack traces are meaningful. Modules are
also separated into separate closures so variables are contained and never
collide. You can also use the latest JavaScript syntax, like
arrow functions, destructuring, and generator functions, as it
compiles the code down to ES5 syntax for you. This means that your code also
runs on our Duktape-based runtime, which you are forced to use if you use Frida
on a jailed iOS device, or on a jailbroken iOS device running iOS >= 9.
In order to give you a short feedback loop while developing, frida-compile also
provides a watch mode through -w, so you get instant incremental builds as you
develop your agent.
Anyway, enough theory. Let’s look at how we can use an off-the-shelf web
application framework from npm, and inject that into any process.
First, make sure you have the latest version of Node.js installed. Next, create
an empty directory and paste this into a file named “package.json”:
{"name":"hello-frida","version":"1.0.0","scripts":{"prepublish":"npm run build","build":"frida-compile agent -o _agent.js","watch":"frida-compile agent -o _agent.js -w"},"devDependencies":{"express":"^4.14.0","frida-compile":"^2.0.6"}}
Then in agent.js, paste the following code:
constexpress=require('express');constapp=express();app.get('/ranges',(req,res)=>{res.json(Process.enumerateRangesSync({protection:'---',coalesce:true}));}).get('/modules',(req,res)=>{res.json(Process.enumerateModulesSync());}).get('/modules/:name',(req,res)=>{try{res.json(Process.getModuleByName(req.params.name));}catch(e){res.status(404).send(e.message);}}).get('/modules/:name/exports',(req,res)=>{res.json(Module.enumerateExportsSync(req.params.name));}).get('/modules/:name/imports',(req,res)=>{res.json(Module.enumerateImportsSync(req.params.name));}).get('/objc/classes',(req,res)=>{if(ObjC.available){res.json(Object.keys(ObjC.classes));}else{res.status(404).send('Objective-C runtime not available in this process');}}).get('/threads',(req,res)=>{res.json(Process.enumerateThreadsSync());});app.listen(1337);
Install frida-compile and build your agent in one step:
$ npm install
Then load the generated _agent.js into a running process:
Sweet. We just built a process inspection REST API with 7 different endpoints in
fewer than 50 lines of code. What’s pretty cool about this is that we used an
off-the-shelf web application framework written for Node.js. You can actually
use any existing modules that rely on Node.js’ built-in net and http
modules. Like an FTP server, IRC client, or NSQ client.
So up until this release you could use Frida-specific modules like those
mentioned earlier. You could also use thousands of other modules from npm, as
most of them don’t do any I/O. Now with this release you also get access to
all net and http based modules, which opens up Frida for even more cool
use-cases.
In case you are curious how this was implemented, I added Socket.listen()
and Socket.connect() to Frida. These are minimal wrappers on top of GIO’s
SocketListener and SocketClient, which are already part of Frida’s
technology stack and used by Frida for its own needs. So that means our
footprint stays the same with no dependencies added. Because frida-compile
uses browserify behind the scenes, all we had to do was plug in our own
builtins for net and http. I simply ported the original net and http
modules from Node.js itself.
This release also brings some other goodies. One long-standing limitation with
NativeFunction is that calling a system API that requires you to read errno
(UNIX) or call GetLastError() (Windows) would be tricky to deal with. The
challenge is that Frida’s own code might clobber the current thread’s error
state between your NativeFunction call and when you try to read out the
error state.
Enter SystemFunction. It is exactly like NativeFunction, except that the
call returns an object wrapping the returned value and the error state right
afterwards. Here’s an example:
constopen=newSystemFunction(Module.getExportByName(null,'open'),'int',['pointer','int']);constO_RDONLY=0;constpath=Memory.allocUtf8String('/inexistent');constresult=open(path,O_RDONLY);console.log(JSON.stringify(result,null,2));/*
* Which on Darwin typically results in the following output:
*
* {
* "value": -1,
* "errno": 2
* }
*
* Where 2 is ENOENT.
*/
This release also lets you read and modify this system error value from your
NativeCallback passed to Interceptor.replace(), which might come handy if
you are replacing system APIs. Note that you could already do this with
Interceptor.attach(), but that’s not an option in cases where you don’t want
the original function to get called.
Another big change worth mentioning is that our V8 runtime has been heavily
refactored. The code is now easier to understand and it is way less work to add
new features. Not just that, but our argument parsing is also handled by a
single code-path. This means that all of our APIs are much more resilient to bad
or missing arguments, so you get a JavaScript exception instead of having some
APIs do fewer checks and happily crash the target process in case you forgot an
argument.
Anyway, those are the highlights. Here’s a full summary of the changes:
8.1.0:
core: add Socket.listen() and Socket.connect()
core: add setImmediate() and clearImmediate()
core: improve set{Timeout,Interval}() to support passing arguments
core: fix performance-related bug in Interceptor’s dirty state logic
8.1.1:
core: add Script.nextTick()
8.1.2:
core: teach Socket.listen() and Socket.connect() about UNIX sockets
core: fix handling of this.errno / this.lastError replacement functions
core: add SystemFunction API to get errno / lastError on return
core: fix crash on close() during I/O with the Stream APIs
core: fix and consolidate argument handling in the V8 runtime
8.1.3:
core: temporarily disable Mapper on macOS in order to confirm whether this was
the root cause of reported stability issues
core: add .call() and .apply() to NativeFunction
objc: fix parsing of opaque struct types
8.1.4:
core: fix crash in the V8 runtime caused by invalid use of v8::Eternal
frida-repl: add batch mode support through -e and -q
8.1.5:
node: generate prebuilds for 6.0 (LTS) and 7.0 only
8.1.6:
node: generate prebuilds for 4.0 and 5.0 in addition to 6.0 and 7.0
8.1.7:
objc: fix infinite recursion when proxying some proxies
objc: add support for proxying non-NSObject instances
python: fix removal of signal callbacks that are member functions
8.1.8:
core: implement hooking of single-instruction ARM functions
core: plug leak in the handling of unhookable functions on some architectures
core: fix race condition in the handling of setTimeout(0) and
setImmediate() in the Duktape runtime
core: fix crash when processing tick callbacks in the Duktape runtime
core: fix lifetime issue in the Duktape runtime
core: fix the reported module sizes on Linux
core: fix crash when launching apps on newer versions of Android
core: fix handling of attempts to launch Android apps not installed
core: improve compatibility with different versions and flavors of Android by
detecting Dalvik and ART field offsets dynamically
core: fix unload issue on newer versions of Android, which resulted in only
the first attach() succeeding and subsequent attempts all timing out
core: move ObjC and Java into their own modules published to npm, and use
frida-compile to keep baking them into Frida’s built-in JS runtime
java: improve ART compatibility by detecting ArtMethod field offsets
dynamically
node: update dependencies
node: fix unhandled Promise rejection issues
8.1.9:
core: fix use-after-free caused by race condition on script unload
8.1.10:
core: make ApiResolver and DebugSymbol APIs preemptible to avoid deadlocks
8.1.11:
core: use a Mach exception handler on macOS and iOS, allowing us to reliably
catch exceptions in apps that already have a Mach exception handler of
their own
core: fix leak in InvocationContext copy-on-write logic in the Duktape
runtime, used when storing data on this across onEnter and onLeave
8.1.12:
core: fix Interceptor argument replacement issue in the V8 runtime,
resulting in the argument only being replaced the first time
First off is the long-standing issue where multiple Frida clients attached to
the same process were forced to coordinate so none of them would call detach()
while one of the others was still using the session.
This was probably not a big deal for most users of Frida. However, we also had
the same issue if one running frida-server was shared by multiple clients.
You might have frida-trace running in one terminal while using the REPL in
another, both attached to the same process, and you wouldn’t then expect one of
them calling detach() to result in the other one getting kicked out.
Some of you may have tried this and observed that it works as expected, but this
was due to some crazy logic in frida-server that would keep track of how many
clients were interested in the same process, so it could ignore a detach()
call if other clients were still subscribed to the same session. It also had
some logic to clean up a certain client’s resources, e.g. scripts, if it
suddenly disconnected.
Starting with 8.0 we have moved the session awareness into the agent, and kept
the client-facing API the same, but with one little detail changed. Each call to
attach() will now get its own Session, and the injected agent is aware of it.
This means you can call detach() at any time, and only the scripts created in
your session will be destroyed. Also, if your session is the last one alive,
Frida will unload its agent from the target process.
That was the big change of this release, but we didn’t stop there.
One important feature of Frida’s scripts is that you can exchange messages with
them. A script may call send(message[, data]) to send a JSON-serializable
message, and optionally a binary blob of data next to it. The latter is so
you don’t have to spend CPU-cycles turning your binary data into text that you
include in the message.
It is also possible to communicate in the other direction, where the script
would call recv(callback) to get a callback when you post_message() to
it from your application. This allowed you to post a JSON-serializable message
to your script, but there was no support for sending a binary blob of data
next to it.
To address this shortcoming we renamed post_message() to post(), and gave it
an optional second argument allowing you to send a binary blob of data next to
it.
We also improved the C API by migrating from plain C arrays to GBytes,
which means we are able to minimize how many times we copy the data as it flows
through our APIs.
So in closing, let’s summarize the changes:
8.0.0:
core: add support for multiple parallel sessions
core: rename Script’s post_message() to post() and add support for passing
out-of-band binary data to the script
core: replace C arrays with GBytes to improve performance
core: fix heap corruption caused by use-after-free in libgee
core: fix multiple crashes
core: fix exports enumeration crash on macOS Sierra
core: add basic support for running on Valgrind
core: bump the macOS requirement to 10.9 so we can rely on libc++
node: update to the new 8.x API
python: update to the new 8.x API
swift: update to the new 8.x API
swift: upgrade to Swift 3
qml: update to the new 8.x API
clr: update to the new 8.x API
clr: plug leaks
8.0.1:
node: fix Script#post()
8.0.2:
core: fix deadlock when calling recv().wait() from our JS thread
8.0.3:
core: reduce Interceptor base overhead by up to 65%
core: minimize Interceptor GC churn in our V8 runtime, using the same
recycling and copy-on-write tricks as our Duktape runtime
core: speed up gum_process_get_current_thread_id() on macOS and iOS
It’s finally release o’clock, and this time around the focus has been on
improving quality. As it’s been a while since the last time we upgraded our
third-party dependencies, and I found myself tracking down a memory-leak in GLib
that had already been fixed upstream, I figured it was time to upgrade our
dependencies. So with this release I’m happy to announce that we’re now packing
the latest V8, GLib, Vala compiler, etc. Great care was also taken to eliminate
resource leaks, so you can attach to long-running processes without worrying
about memory allocations or OS handles piling up.
So in closing, let’s summarize the changes:
7.3.0:
core: upgrade to the latest V8, GLib, Vala, Android NDK, etc.
core: plug resource leaks
core: fix thread enumeration on Linux/x86-32
core: (arm64) improve function hooking by adding support for relocating LDRPC
with an FP/SIMD destination register
7.3.1:
core: build Android binaries with PIE like we used to
7.3.2:
core: add Script.setGlobalAccessHandler() for handling attempts to access
undeclared global variables, which is useful for building REPLs
7.3.3:
objc: convert Number to NSNumber when an object is expected
objc: add support for auto-converting to an array of objects, useful when
calling e.g. +[NSArray arrayWithObjects:count:]
7.3.4:
core: improve the unstable accessor API
core: fix the Duktape globals accessor logic so it’s only applied to reads
7.3.5:
core: improve hexdump() to support any NativePointer-conforming object
objc: fix handling of the L type
7.3.6:
core: fix regression in devkit header auto-generation logic
Some of you may be aware that Frida has two JavaScript runtimes, one based
on V8, and another one based on Duktape.
We also used to have a runtime based on JavaScriptCore,
but it got retired when our Duktape runtime proved better in all of the
situations where V8 wasn’t a good fit, e.g. on tiny embedded systems and
systems where RWX pages are forbidden.
Anyway, what is pretty neat is that Duktape has an API for compiling to
bytecode, allowing you to cache the compiled code and save precious startup time
when it’s time to instrument a new process. Starting with this release we now
have brand new API for compiling your JavaScript to bytecode, and of course
instantiating a script from it. This API is not yet supported in our V8 runtime,
but we should be able to implement it there after our next V8 upgrade, by using
the WebAssembly infrastructure that started appearing in the latest releases.
So without further ado, let’s take this new API for a spin with the Duktape
runtime by forcing Frida to favor Duktape through Session.disable_jit().
Note that the same caveats as specified in the Duktape documentation
apply here, so make sure the code you’re trying to load is well-formed and
generated by the same version of Duktape. It may get upgraded when you upgrade
to a future version of Frida, but will at least be architecture-neutral; i.e.
you can compile to bytecode on a 64-bit x86 desktop and load it just fine in
a 32-bit iOS app on ARM.
So that’s bytecode compilation through the API, but you probably want to use the frida-compile
CLI tool for this instead:
While developing you can also use it in watch mode by adding -w, which makes
it watch the inputs and perform fast incremental builds whenever one of them
changes.
Whether you’re using bytecode (-b) or not, frida-compile is highly recommended
as it also comes with a number of other benefits, letting you:
Split your script into multiple .js files by using require().
Use ES6 syntax and have your code compiled to ES5 so it’s compatible with
the Duktape runtime.
So in closing, let’s summarize the changes:
7.2.0:
core: add support for compiling and loading to/from bytecode
core: include error name and stack trace in RPC error replies
node: add support for the new bytecode APIs
node: augment RPC errors with name and stack when available
node: port examples to ES6
python: add support for the new bytecode APIs
python: update to the revised RPC protocol
7.2.1:
objc: add support for resolving methods on minimal Objective-C proxies
7.2.2:
objc: fix handling of methods returning structs and floating point values
7.2.3:
objc: expose the raw handle of Objective-C methods
7.2.4:
core: fix deadlock that was easily reproducible on iOS 9
java: improve Java.perform() robustness and handling of non-app processes
7.2.5:
objc: fix handling of methods returning a struct in registers on x86-64
7.2.6:
core: port Gum to MIPS
core: avoid swallowing exception when a Proxy object misbehaves
objc: add support for accessing Objective-C instance variables
7.2.7:
core: port .so injector to MIPS
core: enhance MIPS fuzzy backtracer with more branch-and-link instructions
core: fix UnixInputStream and UnixOutputStream pollable behavior on TTYs,
fixing hang on script unload
core: remove “0x” prefix from hexdump() offsets
7.2.8:
objc: fix parsing of type hints
objc: add support for including type hints
objc: make ObjC.Block’s types field public
objc: add support for properly declaring void *
core: (MIPS) fix stack offset when getting/setting stack arguments
7.2.9:
core: fix bug preventing registers from being written in the V8 runtime
7.2.10:
core: add support for attaching to iOS Simulator processes
core: fix Android class-resolving regression introduced in 7.2.4
7.2.11:
core: always kill iOS apps through SpringBoard
7.2.12:
objc: unregister Objective-C classes on unload and GC
7.2.13:
core: fix application kill logic on iOS 9
7.2.14:
core: make the Duktape runtime preemptible like the V8 runtime
core: fix a few locking bugs in the V8 runtime
7.2.15:
core: implement the Kernel API in the Duktape runtime also
core: remove the dangerous Kernel.enumerateThreads() API
7.2.16:
core: improve robustness when quickly reattaching to the same process
core: fix deadlock when pending calls exist at detach time
core: fix hooking regression on 32-bit ARM
core: fix dlsym() deadlock in frida-gadget on Linux
core: fix Windows build regression
core: fix iOS 7 regression
7.2.17:
core: fix session teardown regression
7.2.18:
core: fix long-standing stability issue on iOS 9, where the injected bootstrap
code was not pseudo-signed and caused processes to eventually lose their
CS_VALID status
core: speed up app launching on iOS by eliminating unnecessary disk I/O
core: fix temporary directory clean-up on iOS
7.2.19:
core: fix preemption-related lifetime-issue in the Duktape runtime
7.2.20:
core: rework the V8 runtime to support fully asynchronous unloading
core: rework the Duktape runtime to support fully asynchronous unloading
core: make the Duktape runtime fully reentrant
core: add Script.pin() and Script.unpin() for extending a script’s
lifetime in critical moments, e.g. for callbacks expected from external
APIs out of one’s control
core: fix a timer-related leak in both the V8 and the Duktape runtime
objc: keep script alive until callback scheduled by ObjC.schedule() has
been executed
objc: add a dealloc event to the ObjC proxy API
7.2.21:
core: fix hang on detach()
7.2.22:
core: fix hang on script unload
core: fix hang on abrupt connection loss during detach()
7.2.23:
core: fix two low-probability crashes during script unload
7.2.24:
core: fix use-after-free in the Duktape runtime
core: fix use-after-free bugs in ModuleApiResolver
core: improve unload-behavior when an exception handler is set
7.2.25:
core: fix app launching on iOS 9.3.3
frida-server: fix “hang” on detach when another client is attached to the
same process
If you’ve ever used Frida to spawn programs making use of stdio you might have
been frustrated by how the spawned process’ stdio state was rather undefined and
left you with very little control. Starting with this release we have started
addressing this, and programs are now always spawned with stdin, stdout and
stderr redirected, and you can even input your own data to stdin and get
the data being written to stdout and stderr. Frida’s CLI tools get this
for free as this is wired up
in the ConsoleApplication base-class. If you’re not using ConsoleApplication
or you’re using a different language-binding, simply connect to the output
signal of the Device object and your handler will get three arguments each
time this signal is emitted: pid, fd, and data, in that order. Hit the
input() method on the same class to write to stdin. That’s all there is to
it.
Now that we have normalized the stdio behavior across platforms, we will
later be able to add API to disable stdio redirection.
Beside this and lots of bug-fixes we have also massively improved the support
for spawning plain programs on Darwin, on both Mac and iOS, where spawn() is
now lightning fast on both and no longer messes up the code-signing status on
iOS.
For those of you doing advanced instrumentation of Mac and iOS apps there’s now
also brand new API for dynamically creating your own Objective-C protocols at
runtime. We already supported creating new classes and proxy objects, and with
this new API you can do even more.
So in closing, here’s a summary of the changes:
7.1.0:
core: add Device.input() API for writing to stdin of spawned processes
core: add Device.output signal for propagating output from spawned processes
core: implement the new spawn() stdio behavior in the Windows, Darwin, and
Linux backends
core: downgrade to Capstone 3.x for now due to non-trivial regressions in 4.x
node: add support for the new stdio API
node: add missing return to error-path
python: add support for the new stdio API
7.1.1:
core: fix intermittent crash in spawn()
7.1.2:
core: rework the spawn() implementation on Darwin, now much faster and
reliable
core: add support for enumerating and looking up dynamic symbols on Darwin
core: fix page size computation in the Darwin Mach-O parser
7.1.3:
core: revert temporary hack
7.1.4:
python: fix ConsoleApplication crash on EOF
frida-trace: flush queued events before exiting
7.1.5:
frida-repl: improve REPL autocompletion
objc: add ObjC.registerProtocol() for dynamic protocol creation
objc: fix handling of class name conflicts
objc: allow proxies to be named
7.1.6:
python: fix setup.py download fallback
7.1.7:
python: improve the setup.py download fallback
7.1.8:
python: fix the setup.py local fallback and look in home directory instead
7.1.9:
core: fix handling of overlapping requests to attach to the same pid
core: (Darwin) fix spawn() without attach()
core: (Darwin) fix crash when shutdown requests overlap
frida-server: always recycle the same temporary directory
7.1.10:
core: (Windows) upgrade from VS2013 to VS2015
node: add prebuild for Node.js 6.x
python: fix handling of unicode command-line arguments on Python 2.x
qml: use libc++ instead of libstdc++ on Mac
7.1.11:
core: provide a proper error message when the remote Frida is incompatible
core: ignore attempts to detach from the system session
core: guard against create_script() and detach() overlapping
core: fix setTimeout() so the delay is optional and defaults to 0
It’s been a while since our last major release bump. This time we’re addressing
the long-standing issue where 64-bit integers were represented as JavaScript
Number values. This meant that values beyond 53 bits were problematic due to
the fact that the underlying representation is a double.
The 64-bit types in the Memory, NativeFunction, and NativeCallback APIs
are now properly represented by the newly introduced Int64
and UInt64 types, and their APIs are almost
identical to NativePointer.
core: fix Int64/UInt64 field capacity on 32-bit architectures
7.0.2:
core: allow Int64 and UInt64 to be passed as-is to all relevant APIs
core: fix handling of $protocols on ObjC instances
7.0.3:
core: fix race-condition where listener gets destroyed mid-call
core: fix handling of nested native exception scopes
core: improve QNX support
frida-repl: tweak the startup message
7.0.4:
core: massively improve the function hooking success-rate on 32-bit ARM
core: improve the function hooking success-rate on 64-bit ARM
core: fix the sp value exposed by Interceptor on 32-bit ARM
7.0.5:
core: spin the main CFRunLoop while waiting for Device#resume() when
spawning iOS apps, allowing thread-sensitive early instrumentation to be
applied from the main thread
7.0.6:
core: fix hooking of half-word aligned functions on 32-bit ARM
core: fix thread enumeration on Linux
core: add simple hexdump() API to the Script runtimes
core: make the Duktape runtime’s CpuContext serializable to JSON
7.0.7:
core: allow passing a NativePointer to hexdump()
7.0.8:
core: fix handling of wrapper objects in retval.replace()
core: fix behavior of Memory.readUtf8String() when a size is specified
core: add support for the new task_for_pid(0) method on the iOS 9.1 JB
core: don’t use cbnz which is not available in ARM mode on some processors
core: implement enumerate_threads() and modify_thread() for QNX
7.0.9:
core: fix early crash in FridaGadget.dylib on iOS when running with
ios-deploy and other environments where we are loaded before
CoreFoundation
core: run a CFRunLoop in the main thread of frida-helper on Darwin,
allowing system session scripts to make use of even more Apple APIs
core: add stream APIs for working with GIO streams, for now only exposed
through UnixInputStream and UnixOutputStream (UNIX), and
Win32InputStream and Win32OutputStream (Windows)
7.0.10:
core: fix deadlock on script unload when I/O operations are pending
7.0.11:
core: spin the main CFRunLoop while FridaGadget.dylib is blocking waiting for
Device#resume(), allowing thread-sensitive early instrumentation to be
applied from the main thread
It’s release o’clock, and this time we’re bringing you massive performance
improvements on all platforms, a brand new API for looking up functions, and
major stability improvements on iOS 9.
Let’s talk about the latter subject first. Some of you may have noticed weird
bugs and deadlocks when using Frida on iOS 9. The root cause was simply that our
inline hooking was causing the process to lose the CS_VALID bit of its
code-signing status.
This was not a problem on iOS 8 and older as jailbreaks were always able to
patch the kernel to loosen up on its code-signing requirements. Starting with
this release we have implemented some tricks to be able to do inline hooking
without breaking the code-signing status. For the technically curious this means
that we dynamically generate a .dylib as a temporary file, write out the new
versions of the memory pages that we’d like to modify, e.g. the libc memory page
containing open(), then pseudo-sign this binary, ask the kernel to F_ADDFILESIGS
to it, and finally mmap() from this file on top of the original memory pages.
This brings us to the next topic: performance. The tricks that I just talked
about do actually add quite a bit of extra overhead just to hook one single
function. It is also a very different approach from what we can do on systems
with support for read-write-execute memory-pages and relaxed code-signing
requirements, so this obviously meant that major architectural changes were
needed. I had also been thinking for a while about being able to apply a whole
batch of hooks in one go, allowing us to be more efficient and have more control
on exactly when hooks are activated.
Starting with this release, our Interceptor API now supports transactions.
Simply call begin_transaction(), hook all the functions, and make them all
active in one go by calling end_transaction(). This results in a massive
performance boost, and you get all of this for free without any changes to your
existing code. This is because we implicitly begin a transaction whenever we’re
entering the JavaScript runtime, and end it when we’re leaving it (and just
before we send() a message or return from an RPC method). So unless you’re
attaching your hooks from timers or asynchronous APIs like Memory.scan(),
they will all be batched into a single transaction and get a performance boost.
Here’s how we stack up to CydiaSubstrate in terms of performance:
Note that if you’re using our instrumentation engine from C or C++ you will
have to call begin_transaction() and end_transaction() yourself to get this
boost, but your code will still work even if you don’t, because every operation
will implicitly contain a transaction, and the API allows nesting those calls.
That was function hooking performance, but we didn’t stop there. If you’ve ever
used frida-trace to trace Objective-C APIs, or glob for functions across all
loaded libraries, you may have noticed that it could take quite a while to
resolve all the functions. If you combined this with early instrumentation it
could even take so long that we exceeded the system’s launch timeout.
All of this has now been optimized, and to give you an idea of the speed-up,
a typical Objective-C case that used to take seconds is now completing in a
few milliseconds.
Now to the final part of the news. Considering that dynamically discovering
functions to hook is such a common use-case, and not just something that
frida-trace does, we now have a brand new API
for just that:
So in closing, here’s a summary of the changes:
6.2.0:
core: improve Interceptor to avoid breaking dynamic code-signing on iOS 9
core: move to a transaction-based Interceptor API for improved performance
core: fix crash when scheduled callbacks are freed late (V8 and Duktape)
frida-trace: improve performance by removing setTimeout() logic, allowing
many hooks to be applied in the same transaction
frida-trace: batch log events in 50 ms chunks to improve performance
6.2.1:
core: add ApiResolver API
frida-trace: improve performance by using the new ApiResolver API
6.2.2:
core: fix oops that prevented injection into Windows Store/Universal apps
core: fix crash on teardown on 32-bit ARM
core: add frida-inject, a tool to inject an agent into a running process with
similar semantics to frida-gadget
core: (Linux) prevent libdl from unloading to work around TLS destructor bug
core: (Linux) fix race-condition on rapid uninject
6.2.3:
core: fix source-map handling for eval code, which manifested itself as
unhandled exceptions getting swallowed, e.g. when running frida-trace
core: fix Python 3.x build system regression
frida-trace: fix path escaping issue
frida-trace: improve error-handling for bad handlers
6.2.4:
frida-trace: monitor handlers instead of polling them
6.2.5:
core: add support for hooking arbitrary instructions by calling
Interceptor.attach() with a function instead of a callbacks object
core: add support for detaching individual listeners added by
Interceptor.attach(), even synchronously from their callbacks
core: add Memory.scanSync()
core: fix clobber by improving Interceptor to preserve r12 aka IP on ARM
core: expose r8 through r12 to the JavaScript runtimes
core: fix crash on architectures where unaligned word access is not supported
frida-repl: simplify logic by using the RPC feature
node: upgrade to prebuild 3.x
6.2.6:
core: fix regression on non-jailbroken iOS systems
core: fix Interceptor regression in the Duktape runtime
core: fix module name of resolved imports
core: add API for specifying which host to connect to
core: improve QNX support and fix build regressions
core: fix the frida-inject build system on Mac
core: (Windows) fix crash when USB device location retrieval fails
frida-server: allow overriding the default listen address
frida-node: add addRemoteDevice() and removeRemoteDevice() to
DeviceManager
frida-python: add -H switch for specifying the host to connect to
frida-python: add add_remote_device() and remove_remote_device() to
DeviceManager
frida-python: fix compatibility issues with the Duktape runtime
frida-python: canonicalize the requested RPC method name
Some time ago @s1341 ported Frida to QNX, and just a
few weeks back he was running into memory footprint issues when using Frida on
embedded ARM devices. This was right after he contributed pull-requests porting
Frida to linux-arm. We started realizing that it might be time for a new
JavaScript runtime, and agreed that Duktape seemed like a
great fit for our needs.
This runtime has now landed, all tests are passing, and it even beats our V8
runtime on the measured overhead for a call to a hooked function with an empty
onEnter/onLeave callback. To give you an idea:
…/interceptor_on_enter_performance: V8 min=2 max=31 avg=2 OK
…/interceptor_on_enter_performance: DUK min=1 max=2 avg=1 OK
(Numbers are in microseconds, measured on a 4 GHz i7 running OS X 10.11.2.)
Anyway, even if that comparison isn’t entirely fair, as we do some clever
recycling and copy-on-write tricks that we don’t yet do in our V8 runtime, this
new runtime is already quite impressive. It also allows us to run on really tiny
devices, and the performance difference between a roaring JIT-powered monster
like V8 and a pure interpreter might not really matter for most users of Frida.
So starting with this release we are also including this brand new runtime
in all of our prebuilt binaries so you can try it out and tell us how it works
for you. It only adds a few hundred kilobytes of footprint, which is nothing
compared to the 6 MB that V8 adds per architecture slice. Please try it out
by passing --disable-jit to the CLI tools, or calling session.disable_jit()
before the first call to session.create_script().
Considering that this new runtime also solves some issues that would require a
lot of work to fix in our JavaScriptCore runtime, like ignoring calls from
background threads and avoid poisoning the app’s heap, we decided to get rid
of that runtime and switch to this new Duktape-based runtime on OSes where V8
cannot currently run, like on iOS 9. We feature-detect this at runtime, so you
still get to use V8 on iOS 8 like before – unless you explicitly --disable-jit
as just mentioned.
So in closing, here’s a summary of the changes:
6.1.0:
core: replace the JavaScriptCore runtime with its successor built on Duktape
core: add disable_jit() to allow users to try out the new Duktape engine
core: fix crash on Linux when injecting into processes where pthread_create
has never been called/bound yet
core: add support for linux-armhf (e.g. Raspberry Pi)
python: add disable_jit() to Session
node: add disableJit() to Session
CLI tools: add –disable-jit switch
frida-repl: upgrade to latest prompt-toolkit
frida-trace: fix crash when attempting to trace partially resolved imports
frida-trace: stick to ES5 in the generated handlers for Duktape compatibility
6.1.1:
core: fix synchronization logic and error-handling bugs in the Duktape runtime
6.1.2:
core: fix Android regression resulting in crash on inject
core: fix Python 3.x build regression
clr: add DisableJit() to Session
6.1.3:
core: give the iOS frida-helper all the entitlements that the Preferences app
has, so system session scripts can read and write system configuration
core: changes to support AppContainer ACL on temporary directory/files within
node: fix pid check so it allows attaching to the system session
6.1.4:
core: implement spawn() for console binaries on iOS
core: improve support for hooking low-level OS APIs
core: fix mapper issues preventing us from injecting into Mac processes
where libraries frida-agent depends are not yet loaded
core: make InvocationContext available to replaced functions also
6.1.5:
core: add support for generator functions in scripts generated by frida-load
Epic release this time, with brand new iOS 9 support and improvements all over
the place. For some more background, check out my blog posts here
and here.
There’s a lot of ground to cover here, but the summary is basically:
6.0.0:
core: add support for OS X El Capitan
core: add support for iOS 9
core: fix launchd plist permissions in Cydia package
core: disable our dynamic linker on iOS for now
core: add new JavaScript runtime based on JavaScriptCore, as we cannot
use V8 on iOS 9 with the current jailbreak
core: add brand new system session when attaching to pid=0
core: improve arm hooking, including support for early TBZ/TBNZ/IT/B.cond,
and avoid relocating instructions that a later instruction loops back to
core: fix relocation of LDR.W instructions on arm64
core: abort when we’re stuck in an exception loop
core: fix AutoIgnorer-related deadlocks
core: drop our . prefix so temporary files are easier to discover
python: add support for running without ES6 support
python: tweak setup.py to allow offline installation
python: lock the prompt-toolkit version to 0.38 for now
frida-repl: fix display of raw buffers as returned by Memory.readByteArray()
frida-repl: fix crash in completion on error
node: add support for DeviceManager’s added and removed signals
node: add example showing how to watch available devices
node: use prebuild instead of node-pre-gyp
node: Babelify the source code read by frida.load()
node: remove frida.load() as it’s now in the frida-load module
6.0.1:
python: stop providing 3.4 binaries and move to 3.5 instead
node: fix Linux linking issue where we fail to pick up our libffi
node: also produce prebuild for Node.js LTS
6.0.2:
core: provide FridaGadget.dylib for instrumenting iOS apps without jailbreak
core: add support for the iOS Simulator
core: improve MemoryAccessMonitor to allow monitoring any combination of
R, W or X operations on a page
python: fix UTF-8 fields being accidentally exposed as str on Python 2.x
6.0.3:
core: fix spawn() on OS X
6.0.4:
core: add partial support for using the gadget standalone
CLI tools: fix crash when the stdout encoding cannot represent all characters
frida-trace: always treat handler scripts as UTF-8
6.0.5:
core: add logical shift right and left operations to NativePointer
core: improve Interceptor to support attaching to a replaced function
core: add support for hooking tiny functions on 32-bit ARM
core: emulate {Get/Set}LastErrror and TLS key access on Windows, allowing
us to hook more low-level APIs
6.0.6:
core: fix launchd / Jetsam issue on iOS 9
core: fix iOS 9 code signing issue
core: update security attributes on named pipe to allow us to inject into
more Windows apps
6.0.7:
core: add support for injecting into processes on linux-arm
core: fix crashes related to the DebugSymbol API on Mac and iOS
frida-trace: improve manpage parser
6.0.8:
core: fix Linux compatibility issue caused by failing to link libstdc++
statically
6.0.9:
core: add support for running frida-gadget standalone
core: add a temporary workaround for Windows compatibility regression
core: port the Fruity backend to Linux, allowing direct access to connected
iOS devices
core: expose the InvocationContext context read-write in the JavaScriptCore
runtime also
core: fix issue with InvocationContext’s CpuContext getting GCed prematurely
6.0.10:
Re-release of 6.0.9 with a Windows build regression fix.
6.0.11:
core: prevent stale HostSession objects in case of network errors
CLI tools: assume UTF-8 when the stdout encoding is unknown
node: fix double free caused by using the wrong Nan API
6.0.12:
core: update security attributes on named pipe on Windows
core: add CreateProcessW flags to prevent IFEO loop on Windows
core: fix hooking of recursive functions on arm and arm64
Wow, another major release! We decided to change the Device API to give you
persistent IDs so you can easily tell different devices apart as they’re
hotplugged.
But that’s just the beginning of it, we’re also bringing a ton of other
improvements this time:
5.0.0:
core: change Device.id to represent individual devices across reconnects
core: add new Droidy backend for interfacing with connected Android devices
core: adjust confusing iPhone 5+ device name on Darwin
core: normalize the fallback iOS device name for consistency with Android
core: upgrade V8 to 4.5.103.30
objc: include both class and instance methods in $methods and $ownMethods
python: add -D switch for specifying the device id to connect to
python: add frida-ls-devices CLI tool for listing devices
python: update to the new Device.id API
python: add get_local_device() and improve API consistency with frida-node
node: update to the new Device.id API
node: improve the top-level facade API
qml: update to the new Device.id API
clr: update to the new Device.id API
frida-ps: improve the output formatting
5.0.1:
core: add support for source maps
node: add frida.load() for turning a CommonJS module into a script
node: upgrade Nan
5.0.2:
core: add console.warn() and console.error()
core: add Module.enumerateImports() and implement on Darwin, Linux,
and Windows
core: allow null module name when calling Module.findExportByName()
core: move Darwin.Module and Darwin.Mapper from frida-core to frida-gum,
allowing easy Mach-O parsing and out-of-process dynamic linking
core: better handling of temporary files
frida-trace: add support for conveniently tracing imported functions
frida-trace: blacklist dyld_stub_binder from being traced
python: avoid logging getting overwritten by the status message changing
5.0.3:
core: improve arm64 hooking, including support for hooking short functions
5.0.4:
core: improve arm64 hooking, also taking care to avoid relocating instructions
that other instructions depend on, including the next instruction after
a BL/BLR/SVC instruction
core: port Arm64Writer and Arm64Relocator to Capstone
5.0.5:
core: fix crash on teardown by using new API provided by our GLib patch
core: fix module name resolving on Linux
core: improve ELF handling to also consider ET_EXEC images as valid modules
core: improve arm64 hooking
core: port {Arm,Thumb}Writer and {Arm,Thumb}Relocator to Capstone
python: fix tests on OS X 10.11
node: fix tests on OS X 10.11
5.0.6:
core: turn NativeFunction invocation crash into a JS exception when possible
core: add Process.setExceptionHandler() for handling native exceptions from
JS
core: install a default exception handler that emits error messages
core: prevent apps from overriding our exception handler if we install ours
early in the process life-time
core: gracefully handle it if we cannot replace native functions
core: allow RPC exports to return ArrayBuffer values
python: add support for rpc methods returning ArrayBuffer objects
node: add support for rpc methods returning ArrayBuffer objects
5.0.7:
core: don’t install a default exception handler for now
5.0.8:
Re-release of 5.0.7 due to build machine issues.
5.0.9:
python: update setup.py to match new build server configuration
5.0.10:
core: fix instrumentation of arm64 functions with early usage of IP registers
Time for another packed release. This time we’re bringing a brand new spawn
gating API that lets you catch processes spawned by the system, and tons of
Android improvements and improvements all over the place.
So without further ado, the list of changes:
4.5.0:
core: add Process.pageSize constant
core: let Memory.alloc() allocate raw pages when size >= page size
core: fix NativeFunction’s handling of small return types
core: fix PC alignment when rewriting BLX instructions
core: add spawn gating API
core: implement get_frontmost_application() on Android
core: implement enumerate_applications() on Android
core: add support for spawning Android apps
core: add support for injecting into arm64 processes on Android
core: add support for Android M
core: patch the kernel’s live SELinux policy
core: integrate with SuperSU to work around restrictions on Samsung kernels
core: work around broken sigsetjmp on Android, and many other Android fixes
core: fix crash when enumerating modules on Linux
core: optimize exports enumeration for remote processes on Darwin
dalvik: port to ART and deprecate Dalvik name, now known as Java
java: add Java.openClassFile() to allow loading classes at runtime
java: fixes for array conversions and field setters
python: add support for the new spawn gating API
python: allow script source and name to be unicode on Python 2.x also
With 4.4 out the door, we can now offer you a brand new RPC API
that makes it super-easy to communicate with your scripts and have them expose
services to your application. We also got some amazing contributions from
Adam Brady, who just ported frida-node to
Nan, making it easy to build it for multiple
versions of Node.js.
So to summarize this release:
core: add new RPC API
python: add support for calling RPC exports
node: add support for calling RPC exports
node: allow posted message value to be anything serializable to JSON
The Frida co-conspirators have been cracking away on several fronts, so much
lately that I figured it was worth jotting this down to get the word out.
In Dalvik land, @marc1006 contributed a really
neat new feature – the ability to do object carving, essentially scanning the
heap for objects of a certain type. Check this out:
In other mobile news, @pancake added support for
enumerating applications on Firefox OS. Sweet!
While all of this was going on, @s1341 has been
hard at work stabilizing the QNX port, and it’s reportedly working really well
now.
On my end I have been applying Frida to interesting challenges at
NowSecure, and ran into quite a few bugs and
limitations in the Objective-C integration. There’s now support for overriding
methods that deal with struct types passed by value, e.g. -[UIView drawRect:],
which means NativeFunction and NativeCallback also support these; so for
declaring a struct simply start an array with the fields’ types specified
sequentially. You can even nest them. So for the - drawRect: case where a
struct is passed by value, and that struct is made out of two other structs,
you’d declare it like this:
Another thing worth mentioning is that a long-standing issue especially visible
when instrumenting 32-bit iOS apps, but affecting all platforms, has finally
been fixed.
So let’s run quickly through all the changes:
4.1.8:
core: add support for enumerating applications on Firefox OS
core: add NativePointer.toMatchPattern() for use with Memory.scan()
core: fix QNX injector race condition
objc: massively improved handling of types
objc: fix implicit conversion from JS string to NSString
objc: fix crash during registration of second proxy or unnamed class
objc: new ObjC.Object properties: $className and $super
dalvik: add Dalvik.choose() for object carving
4.1.9:
core: NativeFunction and NativeCallback now support functions passing
struct types by value
core: fix accidental case-sensitivity in Process.getModuleByName()
dalvik: new object property: $className
4.2.0:
core: add this.returnAddress to Interceptor’s onEnter and onLeave
callbacks
objc: add ObjC.choose() for object carving
4.2.1:
core: fix exports enumeration of stripped libraries on QNX
objc: new ObjC.Object property: $kind, a string that is either instance,
class or meta-class
objc: fix the $class property so it also does the right thing for classes
objc: fix crash when looking up inexistent method
python: ensure graceful teardown of the reactor thread
frida-discover: fix regression
frida-repl: fix hang when target crashes during evaluation of expression
4.2.2:
core: fix exception handling weirdness; very visible on ios-arm
core: QNX stability improvements
objc: add ObjC.api for direct access to the Objective-C runtime’s API
objc: new ObjC.Object properties: equals, $superClass and $methods
objc: fix iOS 7 compatibility
objc: fix toJSON() of ObjC.classes and ObjC.protocols
dalvik: fix handling of java.lang.CharSequence
frida-repl: add %time command for easy profiling
4.2.3:
core: fix crash when handling exceptions without a message object
core: fix the life-time of CpuContext JS wrappers
core: expose the file mapping info to Process.enumerateRanges()
core: make it possible to coalesce neighboring ranges when enumerating
core: add convenience API for looking up modules and ranges
core: make the QNX mprotect read in a loop instead of just the once
dalvik: avoid crashing the process if a type conversion fails
dalvik: allow null as call parameter
objc: fix conversion of structs with simple field types
objc: speed up implicit string conversion by caching wrapper object
4.2.4:
objc: fix crash when interacting with not-yet-realized classes
4.2.5:
core: optimize Interceptor callback logic and make it twice as fast when
onEnter and onLeave aren’t both specified
core: fix return-address seen by the invocation-context on arm64
core: add a fuzzy backtracer for arm64
4.2.6:
core: fix access to arguments 4 through 7 on arm64
core: add Memory.readFloat(), Memory.writeFloat(), Memory.readDouble()
and Memory.writeDouble()
dalvik: improved type checking
qnx: implement side-stack for calling onEnter()/onLeave() with the
stack-hungry V8 engine
4.2.7:
core: Darwin backend bug-fixes
core: optimize handling of the send() data payload
core: add APIs for interacting with the iOS kernel through task_for_pid(0),
only available in the attach(pid=0) session
core: side-stack support for replaced functions on QNX
objc: add getOwnPropertyNames() to ObjC.classes
frida-repl: improved completion
4.2.8:
python: fix Py3k regression
4.2.9:
objc: add $ownMethods to ObjC.Object
dalvik: add support for primitive arrays and object arrays
python: improve compatibility between Python 2 and 3
frida-repl: better magic commands
4.2.10:
core: fix Interceptor vector register clobbering issue on arm64
core: improve temporary directory handling on Android
4.2.11:
dalvik: add support for accessing instance and static fields
dalvik: type conversion improvements
python: resolve python runtime lazily on Mac to allow our binaries to work
with multiple Python distributions
python: pip support
4.2.12:
python: fix Py3k regressions
That’s all for now. Please help spread the word by sharing this post across
the inter-webs. We’re still quite small as an open source project, so
word-of-mouth marketing means a lot to us.
It’s release o’clock, and this time we’re taking the iOS support to the next
level while also bringing some solid quality improvements. I’m also really
excited to announce that I’ve recently joined NowSecure,
and the awesomeness of this release is no conincidence.
Let’s start with a brand new iOS feature. It’s now possible to list installed
apps, which frida-ps can do for you:
Note that we piggy-back on Cydia Substrate for the early launch part in order
to maximize interoperability; after all it’s not too good if multiple frameworks
all inject code into launchd and risk stepping on each others’ toes. This
dependency is however a soft one, so we’ll throw an exception if Substrate isn’t
installed when trying to call spawn() with an app identifier.
So, early instrumentation of iOS apps is pretty cool. But, those applications
are typically consuming tons of Objective-C APIs, and if we want to instrument
them we often find ourselves having to create new Objective-C classes in order
to create delegates to insert between the application and the API. Wouldn’t it
be nice if such Objective-C classes could be created in pure JavaScript? Now
they can:
constMyConnectionDelegateProxy=ObjC.registerClass({name:'MyConnectionDelegateProxy',super:ObjC.classes.NSObject,protocols:[ObjC.protocols.NSURLConnectionDataDelegate],methods:{'- init':function(){constself=this.super.init();if(self!==null){ObjC.bind(self,{foo:1234});}returnself;},'- dealloc':function(){ObjC.unbind(this.self);this.super.dealloc();},'- connection:didReceiveResponse:':function(conn,resp){/* this.data.foo === 1234 */},/*
* But those previous methods are declared assuming that
* either the super-class or a protocol we conform to has
* the same method so we can grab its type information.
* However, if that's not the case, you would write it
* like this:
*/'- connection:didReceiveResponse:':{retType:'void',argTypes:['object','object'],implementation(conn,resp){}},/* Or grab it from an existing class: */'- connection:didReceiveResponse:':{types:ObjC.classes.Foo['- connection:didReceiveResponse:'].types,implementation(conn,resp){}},/* Or from an existing protocol: */'- connection:didReceiveResponse:':{types:ObjC.protocols.NSURLConnectionDataDelegate.methods['- connection:didReceiveResponse:'].types,implementation(conn,resp){}},/* Or write the signature by hand if you really want to: */'- connection:didReceiveResponse:':{types:'v32@0:8@16@24',implementation(conn,resp){}}}});constproxy=MyConnectionDelegateProxy.alloc().init();/* use `proxy`, and later: */proxy.release();
Though most of the time you’d like to build a proxy object where you
pass on everything and only do some logging for the few methods you
actually care about. Check this out:
constMyConnectionDelegateProxy=ObjC.registerProxy({protocols:[ObjC.protocols.NSURLConnectionDataDelegate],methods:{'- connection:didReceiveResponse:':function(conn,resp){/* fancy logging code here *//* this.data.foo === 1234 */this.data.target.connection_didReceiveResponse_(conn,resp);},'- connection:didReceiveData:':function(conn,data){/* other logging code here */this.data.target.connection_didReceiveData_(conn,data);}},events:{forward(name){console.log('*** forwarding: '+name);}}});constmethod=ObjC.classes.NSURLConnection['- initWithRequest:delegate:startImmediately:'];Interceptor.attach(method.implementation,{onEnter(args){args[3]=newMyConnectionDelegateProxy(args[3],{foo:1234});}});
So that’s Objective-C. The Dalvik integration also got some sweet new API for
enumerating loaded classes thanks to @marc1006,
who also fixed our handling of static methods and being able to return booleans
from overriden implementations.
We also got lots of awesome improvements from @Tyilo
who helped improve the ObjC integration, beat the REPL into better shape, added
APIs for enumerating malloc ranges, and added some convenience APIs to
NativePointer.
While all of this was going on, @s1341 has been
hard at work doing an amazing job porting Frida to QNX, which is now really
close to working like a charm.
Let’s run through the remaining changes:
4.0.1:
objc: support for more types
frida-trace: fix ObjC tracing regression
4.0.2:
frida-node: fix encoding of the pixels property
4.0.3:
frida-repl: fix Windows regression
4.0.5:
objc: support for more types and better type checking
objc: arm64 now working properly
frida-repl: allow variables to be created
4.0.6:
platform: support passing a plain array of data to send()
arm: support for relocating cbz/cbnz instructions
4.1.0:
platform: fix spawning of child processes that write to stdout
platform: fix NativeCallback’s handling of bool/int8/uint8 return
values (this was preventing Dalvik method overrides from being able to
return false).
platform: allow Memory.readByteArray() with length < 1
arm: support for relocating the ldrpc t2 instruction
arm: improved redirect resolver
arm64: fix relocation of the adrp instruction
arm64: support for relocating PC-relative ldr instruction
dalvik: add Dalvik.enumerateLoadedClasses()
dalvik: fix handling of static methods
python: fix console.log() on Windows
frida-repl: bugfixes and improvements
frida-trace: glob support for tracing ObjC methods
4.1.1:
platform: add missing pid field in enumerate_applications()
4.1.2:
objc: class and proxy creation APIs
objc: new ObjC.protocols API for enumerating protocols
4.1.3:
platform: improved concurrency by releasing V8 lock while calling
NativeFunction
platform: add Process.getModuleByName(name)
platform: faster and more robust detach
python: stability improvements in CLI tools
frida-repl: replace readline with prompt-toolkit
4.1.4:
platform: faster and more robust teardown
frida-server: clean up on SIGINT and SIGTERM
4.1.5:
frida-ps: add support for listing applications
4.1.6:
platform: fix crash on spawn on Mac, iOS and Linux
platform: add NativePointer.compare() and NativePointer.equals()
frida-trace: switch from Enter to Ctrl+C for stopping
frida-trace: fix spawning of iOS apps
frida-repl: add prototype names to autocomplete
4.1.7:
python: CLI tools stability improvements
That’s all for now. Please help spread the word by sharing this post across
the inter-webs. We’re still quite small as an open source project, so
word-of-mouth marketing means a lot to us.
It’s time for an insane release with tons of improvements.
Let’s start with a user-facing change. The CLI tool called frida-repl has
been renamed to just frida, and now does tab completion! This and some other
awesome REPL goodies were contributed by @fitblip.
There is also integrated support for launching scripts straight from the shell:
$ frida Calculator -l calc.js
_____
(_____)
| | Frida 4.0.0 - A world-class dynamic
| | instrumentation framework
|`-'|
| | Commands:
| | help -> Displays the help system
| | object? -> Display information about 'object'
| | exit/quit -> Exit
| |
| | More info at https://frida.re/docs/home/
`._.'# The code in calc.js has now been loaded and executed[Local::ProcName::Calculator]->
# Reload it from file at any time[Local::ProcName::Calculator]-> %reload
[Local::ProcName::Calculator]->
Or, perhaps you’re tired of console.log() and would like to set some breakpoints
in your scripts to help you understand what’s going on? Now you can, because
Frida just got an integrated Node.js-compatible debugger.
(Cue “Yo Dawg” meme here.)
Yep yep, but it is actually quite useful, and all of the CLI tools provide
the --debug switch to enable it:
# Connect Frida to a locally-running Calculator.app# and load calc.js with the debugger enabled$ frida Calculator -l calc.js --debug
_____
(_____)
| | Frida 4.0.0 - A world-class dynamic
| | instrumentation framework
|`-'|
| | Commands:
| | help -> Displays the help system
| | object? -> Display information about 'object'
| | exit/quit -> Exit
| |
| | More info at https://frida.re/docs/home/
`._.'
Debugger listening on port 5858
# We can now run node-inspector and start debugging calc.js[Local::ProcName::Calculator]->
Here’s what it looks like:
Ever found yourself wanting to frida-trace Objective-C APIs straight from
the shell? Thanks to @Tyilo you now can:
There are also other goodies, like brand new support for generating backtraces
and using debug symbols to symbolicate addresses:
constf=Module.getExportByName('libcommonCrypto.dylib','CCCryptorCreate');Interceptor.attach(f,{onEnter(args){console.log('CCCryptorCreate called from:\n'+Thread.backtrace(this.context,Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join('\n')+'\n');}});
Or perhaps you’re on Windows and trying to figure out who’s accessing certain
memory regions? Yeah? Well check out the brand new
MemoryAccessMonitor. Technically
this code isn’t new, but it just hasn’t been exposed to the JavaScript API
until now.
Another nice feature is that starting with this release it is no longer
necessary to forward multiple TCP ports when using frida-server running
on another device, e.g. Android.
There is now also much better error feedback propagated all the way from a
remote process to different exceptions in for example Python. With the previous
release attaching to an inexistent pid on Mac would give you:
That’s better. Let’s talk about performance. Perhaps you used frida-trace and
wondered why it spent so much time “Resolving functions…”? On a typical iOS
app resolving just one function would typically take about 8 seconds.
This is now down to ~1 second. While there were some optimizations possible,
I quickly realized that no matter how fast we make the enumeration of function
exports, we would still need to transfer the data, and the transfer time alone
could be unreasonable. Solution? Just move the logic to the target process and
transfer the logic instead of the data. Simple.
Also, the Dalvik and ObjC interfaces have been optimized so seconds have been
reduced to milliseconds. The short story here is further laziness in when we
interrogate the language runtimes. We took this quite far in the ObjC interface,
where we now use ES6 proxies to provide a more idiomatic and efficient API.
That brings us to the next topic. The ObjC interface has changed a bit.
Essentially:
constNSString=ObjC.use("NSString");
is now:
constNSString=ObjC.classes.NSString;
You still use ObjC.classes for enumerating the currently loaded classes,
but this is now behaving like an object mapping class name to a JavaScript ObjC
binding.
Yep, no more class hierarchies trying to mimic the ObjC one. Just a fully
dynamic wrapper where method wrappers are built on the first access, and
the list of methods isn’t fetched unless you try to enumerate the object’s
properties.
Anyway, this is getting long, so let’s summarize the other key changes:
The Dalvik interface now handles varargs methods. Thanks to
@dmchell for reporting and helping track this
down.
NativePointer also provides .and(), .or() and .xor() thanks to
@Tyilo.
The Interceptor’s onEnter/onLeave callbacks used to expose the CPU
registers through this.registers, which has been renamed to this.context,
and now allows you to write to the registers as well.
Process.enumerateThreads()’s thread objects got their CPU context field
renamed from registers to context for consistency.
Synchronous versions of enumerateFoo() API available as enumerateFooSync()
methods that simply return an array with all of the items.
Memory.readCString() is now available for reading ASCII C strings.
Frida.version can be interrogated to check which version you’re running,
and this is also provided on the frida-core end, which for example is
exposed by frida-python through frida.__version__.
Stalker now supports the jecxz and jrcxz instructions. This is good news
for CryptoShark, which should soon
provide some updated binaries to bundle the latest version of Frida.
V8 has been updated to 4.3.62, and a lot of ES6 features have been enabled.
We’re now using a development version of the upcoming Capstone 4.0.
All third-party dependencies have been updated to the latest and greatest.
Windows XP is now supported. This is not a joke. I realized that we didn’t
actually use any post-XP APIs, and as I had to rebuild the dependencies on
Windows I figured we might as well just lower our OS requirements to help
those of you still instrumenting software on XP.
We just brought you brand new Node.js bindings,
and they are fully asynchronous:
Check out the examples
to get an idea what the API looks like. It’s pretty much a 1:1 mapping of the
API provided by the Python bindings, but following Node.js / JavaScript
conventions like camelCased method-names, methods returning ES6 Promise
objects instead of blocking, etc.
Now, combine this with NW.js and you can build
your own desktop apps with HTML, CSS, and JavaScript all the way through.
So, brand new Node.js bindings; awesome! We did not stop there, however.
But first, a few words about the future. I am excited to announce that I have
just started a company with the goal of sponsoring part-time development of
Frida. By offering reverse-engineering and software development expertise,
the goal is to generate enough revenue to pay my bills and leave some time
to work on Frida. Longer term I’m hoping there will also be demand for help
adding features or integrating Frida into third-party products.
In the meantime, however, if you know someone looking for reverse-engineering
or software development expertise, I would really appreciate it if you could
kindly refer them to get in touch. Please see my CV
for details.
That aside, let’s get back to the release. Next up: 32-bit Linux support!
Even Stalker has been ported. Not just that, the Linux backend can even do
cross-architecture injection like we do on the other platforms. This means a
64-bit Frida process, e.g. your Python interpreter, can inject into a 32-bit
process. The other direction works too.
Another awesome update is that Tyilo contributed
improvements
to frida-trace so it now uses man-pages for auto-generating the log handlers.
Awesome, huh? But there’s even more goodies:
frida-server ports are now recycled, so if you’re using Frida on Android
you won’t have to keep forwarding ports unless you’re actually attaching to
multiple processes at the same time.
Linux and Android spawn() support has been improved to also support PIE
binaries.
Android stability and compatibility improvements.
Mac and Linux build system have been revamped, and make it easy to build just
the parts that you care about; and maybe even some components you didn’t even
know were there that were previously not built by default.
Python bindings have a minor simplification so instead of
frida.attach(pid).session.create_script() it’s simply just
frida.attach(pid).create_script(). This is just like in the brand
new Node.js bindings, and the reason we had to bump the major version.
That’s the gist of it. Please help spread the word by sharing this post across
the inter-webs. We’re still quite small as an open source project, so
word-of-mouth marketing means a lot to us.
Thanks to your excellent feedback we just eliminated a crasher when using
Frida on Windows with certain iOS device configurations. As this is a very
important use-case we decided to do a hotfix release without any other changes.
It’s time for a new and exciting release! Key changes include:
No more kernel panics on Mac and iOS! Read the full story
here.
Mac and iOS injector performs manual mapping of Frida’s dylib. This means
we’re able to attach to heavily sandboxed processes.
The CLI tools like frida-trace, frida-repl, etc., have brand new support
for spawning processes:
$ frida-trace -i'open*'-i'read*' /bin/cat /etc/resolv.conf
27 ms open$NOCANCEL()
28 ms read$NOCANCEL()
28 ms read$NOCANCEL()
28 ms read$NOCANCEL()
Target process terminated.
Stopping...
$
Usability improvements in frida-repl and frida-discover.
First call to DeviceManager.enumerate_devices() does a better job and
also gives you the currently connected iOS devices, so for simple applications
or scripts you no longer have to subscribe to updates if you require the
device to already be present.
The python API now provides you with frida.get_usb_device(timeout = 0) and
frida.get_remote_device() for easy access to iOS and remote/Android
devices.
The onEnter and onLeave callbacks passed to Interceptor.attach() may
access this.registers to inspect CPU registers, which is really useful
when dealing with custom calling conventions.
console.log() logs to the console on your application’s side instead of
the target process. This change is actually why we had to bump the major
version for this release.
Android 5.0 compatibility, modulo ART support.
Brand new support for Android/x86. Everything works except the Dalvik
integration; please get in touch if you’d like to help out with a pull-request
to fix that!
Want to help out? Have a look at our GSoC 2015 Ideas Page
to get an overview of where we’d like to go next.
Enjoy!
Update 2am: An iOS issue slipped through the final testing, so we
just pushed 2.0.1 to remedy this.
Update 11pm: Thanks to your excellent feedback we found a critical
bug when using Frida on Windows with certain iOS device configurations.
Please upgrade to 2.0.2 and let us know if you run into any issues.
This release introduced a serious regression on iOS and was quickly pulled
from our Cydia repo, though it was available for Mac, Linux and Android while
waiting to be replaced by 2.0.0.
Tired of waiting for Frida to attach to 32-bit processes on 64-bit Mac
or iOS systems? Or perhaps frida-trace takes a while to resolve functions?
If any of the above, or none of it, then this release is for you!
Attaching to 32-bit processes on Mac/iOS hosts has been optimized, and instead
of seconds this is now a matter of milliseconds. That’s however specific to
Darwin OSes; this release also speeds up enumeration of module exports on
all OSes. This is now 75% faster, and should be very noticable when using
frida-trace and waiting for it to resolve functions.
Also, as an added bonus, teardown while attached to multiple processes no
longer crashes on Darwin and Linux.
It’s release o’clock, and time for some bug fixes:
iOS 8.1 is now supported, and the ARM64 support is better than ever.
The iOS USB transport no longer disconnects when sending a burst of data to
the device. This would typically happen when using frida-trace and tracing
a bunch of functions, resulting in a burst of data being sent over the wire.
This was actually a generic networking issue affecting Mac and iOS,
but was very reproducible when using Frida with a tethered iOS device.
Eliminated crashes on shutdown of the Python interpreter.
The onEnter and onLeave callbacks in frida-trace scripts are now called
with this bound to the correct object, which means that it’s bound to an
object specific to that thread and invocation, and not an object shared by
all threads and invocations.
The engine no longer pre-allocates a fixed chunk of 256 MB per thread being
traced, and now grows this dynamically in a reentrancy-safe manner.
Eliminated a bug in the cache lookup logic where certain blocks would always
result in a cache miss. Those blocks thus got recompiled every time they
were about to get executed, slowing down execution and clogging up the cache
with more and more entries, and eventually running out of memory.
Relocation of RIP-relative cmpxchg instruction is now handled correctly.
Better Dalvik integration (Android):
App’s own classes can now be loaded.
Several marshalling bugs have been fixed.
Script runtime:
More than one NativeFunction with the same target address no longer results
in use-after-free.
Also, CryptoShark 0.1.2 is out,
with an upgraded Frida engine and lots of performance improvements so the GUI
is able to keep up with the Stalker. Go get it while it’s hot!
This latest release includes a bunch of enhancements and bug fixes.
Some of the highlights:
The remainder of Frida’s internals have been migrated from udis86 to
Capstone, which means that our Stalker is now able to trace binaries with
very recent x86 instructions. Part of this work also included battle-testing
it on 32- and 64-bit binaries on Windows and Mac, and all known issues have
now been resolved.
Memory.protect() has been added to the JavaScript API, allowing you to
easily change page protections. For example:
Memory.protect(ptr("0x1234"),4096,'rw-');
Process.enumerateThreads() omits Frida’s own threads so you don’t have to
worry about them.
Python 3 binaries are now built against Python 3.4.
So with this release out, let’s talk about CryptoShark:
Grab a pre-built Windows binary here,
or build it from source if you’d like to try it out on Mac or Linux.
How is this implemented you ask? That’s the cool part. Frida already uses the
amazing Capstone disassembly framework
behind the scenes, and thus it makes perfect sense to make it available to the
JavaScript runtime. Have a look at the
JavaScript API Reference for all
the details.
Compatibility with the Pangu iOS jailbreak on ARM64. The issue is that RWX
pages are not available like they used to be with the evad3rs jailbreak.
Fix occasional target process crash when detaching.
Fix crash when trying to attach to a process the second time after failing
to establish the first time. This primarily affected Android users, but could
happen on any OS when using frida-server.
Faster and more reliable injection on Linux/x86-64 and Android/ARM.
Fix issues preventing hooking of HeapFree and friends on Windows.
Upgraded GLib, libgee, json-glib and Vala dependencies for improved
performance and bugfixes.
No more resource leaks. Please report if you find any.
Also new since 1.6.0, as covered in my blog post, there is now a full-
featured binding for Qml. This should be of interest to those of you
building graphical cross-platform tools.
As some of you may have noticed, Frida recently got brand new Android support,
allowing you to easily instrument code just like on Windows, Mac, Linux and iOS.
This may sound cool and all, but Android does run a lot of Java code, which
means you’d only be able to observe the native side-effects of whatever
that code was doing. You could of course use Frida’s FFI API to poke your way
into the VM, but hey, shouldn’t Frida just do that dirty plumbing for you?
Of course it should!
The Dalvik.perform() call takes care of attaching your thread to the VM,
and isn’t necessary in callbacks from Java. Also, the first time you call
Dalvik.use() with a given class name, Frida will interrogate the VM and
build a JavaScript wrapper on-the-fly. Above we ask for the
Activity
class and replace its implementation of onResume with our own version,
and proceed to calling the original implementation after sending a message
to the debugger (running on your Windows, Mac or Linux machine). You could
of course choose to not call the original implementation at all, and emulate
its behavior. Or, perhaps you’d like to simulate an error scenario:
So there you just instantiated a Java Exception and threw it straight from
your JavaScript implementation of Activity.onResume.
This release also comes with some other runtime goodies:
Memory.copy(dst, src, n): just like memcpy
Memory.dup(mem, size): short-hand for Memory.alloc() followed by
Memory.copy()
Memory.writeXXX(): the missing Memory.read() counterparts: S8, S16, U16,
S32, U32, S64, U64, ByteArray, Utf16String and AnsiString
Process.pointerSize to make your scripts more portable
NativePointer instances now have a convenient isNull() method
NULL constant so you don’t have to do ptr("0") all over the place
WeakRef.bind(value, fn) and WeakRef.unbind(id) for the hardcore:
The former monitors value so fn gets called as soon as value has been
garbage-collected, or the script is about to get unloaded. It returns an
id that you can pass to unbind() for explicit cleanup.
This API is useful if you’re building a language-binding, where you need to
free native resources when a JS value is no longer needed.
Just a quick bugfix release to squash
this annoying bug, which is
reproducible on all supported x86 OSes. Thanks for Guillaume for tracking
this one down.
As a bonus, frida-repl now also works on Windows. Happy REPLing!
Interested in spawning processes on Windows or Linux, and not just on Mac? Or
maybe you’ve been bitten by the Linux injector crashing your processes instead
of letting you inject into them? Or maybe you had a function name that was so
long that frida-trace overflowed the max filename length on Windows? Well, if
any of the above, or none of it, then Frida 1.4.1 is for you!
Thanks to Guillaume and Pedro for making this release awesome. Keep those pull-
requests and bug reports coming!
Did anyone say Android? Frida 1.4.0 is out, with brand new Android support!
Have a look at the documentation here
to get started. Also new in this release is that Frida is now powered by
the amazing Capstone Disassembly Engine,
which means our cross-platform code instrumentation is even more powerful.
It also paves the way for taking the x86-only stealth tracing
to new architectures in future releases.
It’s release-o-clock, and Frida 1.2.0 is finally out! Bugfixes aside, this
release introduces brand new ARM64 support, which is quite useful for those of
you using Frida on your iPhone 5S or iPad Air. You can now inject into both 64-
and 32-bit processes, just like on Mac and Windows.
This release also improves stability on ARM32, where attaching to short
functions used to result in undefined behavior.
Some of you experienced issues injecting into processes on Windows, as well as
crashes on iOS. Here’s a new release bringing some serious improvements to
Frida’s internals:
V8 has been upgraded to 3.25 in order to fix the iOS stability issues. This
also means new features (like ECMAScript 6) and improved performance on all
platforms. Another nice aspect is that Frida now depends on a V8 version
that runs on 64-bit ARM, which paves the way for porting Frida itself to
AArch64.
The Windows injector has learned some new tricks and will get you into even
more processes. A configuration error was also discovered in the Windows
build system, which explains why some of you were unable to inject into
some processes.
For those of you building Frida on Windows, the build system there now
depends on VS2013. This means XP is no longer supported, though it is still
possible to build with the v120_xp toolchain if any of you still depend
on that, so let me know if this is a deal-breaker for you.
The recently added support for this.lastError (Windows) is now working
correctly.
That’s all for now. Let us know what you think, and if you like Frida, please
help spread the word! :)
Interceptor is now compatible with a lot more functions on iOS/ARM.
A new CLI tool called frida-repl provides you with a basic REPL to
experiment with the JavaScript API from inside a target process.
onLeave callback passed to Interceptor.attach() is now able to replace
the return value by calling retval.replace().
Both onEnter and onLeave callbacks passed to Interceptor.attach() can
access this.errno (UNIX) or this.lastError (Windows) to inspect or
manipulate the current thread’s last system error.
Here’s how you can combine the latter three to simulate network conditions for
a specific process running on your Mac:
~ $ frida-repl TargetApp
Then paste in:
callbacks={\onEnter(args){\args[0]=ptr(-1);// Avoid side-effects on socket \},\onLeave(retval){\constECONNREFUSED=61;\this.errno=ECONNREFUSED;\retval.replace(-1);\}\};\Module.enumerateExports("libsystem_kernel.dylib",{\onMatch(exp){\if(exp.name.indexOf("connect")===0&&exp.name.indexOf("connectx")!==0){\Interceptor.attach(exp.address,callbacks);\}\},\onComplete(){}\});
Another release — this time with some new features:
Objective-C integration for Mac and iOS. Here’s an example to whet your
appetite:
constUIAlertView=ObjC.use('UIAlertView');/* iOS */ObjC.schedule(ObjC.mainQueue,()=>{constview=UIAlertView.alloc().initWithTitle_message_delegate_cancelButtonTitle_otherButtonTitles_("Frida","Hello from Frida",ptr("0"),"OK",ptr("0"));view.show();view.release();});
Module.enumerateExports() now also enumerates exported variables and not
just functions. The onMatch callback receives an exp object where the
type field is either function or variable.
This release brings USB device support in the command-line tools, and
adds frida-ps for enumerating processes both locally and remotely.
For example to enumerate processes on your tethered iOS device:
$ frida-ps -U
The -U switch is also accepted by frida-trace and frida-discover.
Docs how to set this up on your iOS device will soon be added to the website.
However, that’s not the most exciting part. Starting with this release,
Frida got its first contribution since the HN launch.
Pete Morici dived in and contributed support
for specifying module-relative functions in frida-trace:
This release improves frida-trace with support for auto-generating,
loading and reloading function handlers from scripts on the filesystem.
Have a look at our Quick-start guide for a walkthrough.
Also new in this release is Py3k support, which is available from PyPI on
all platforms.
 oleavr
oleavr
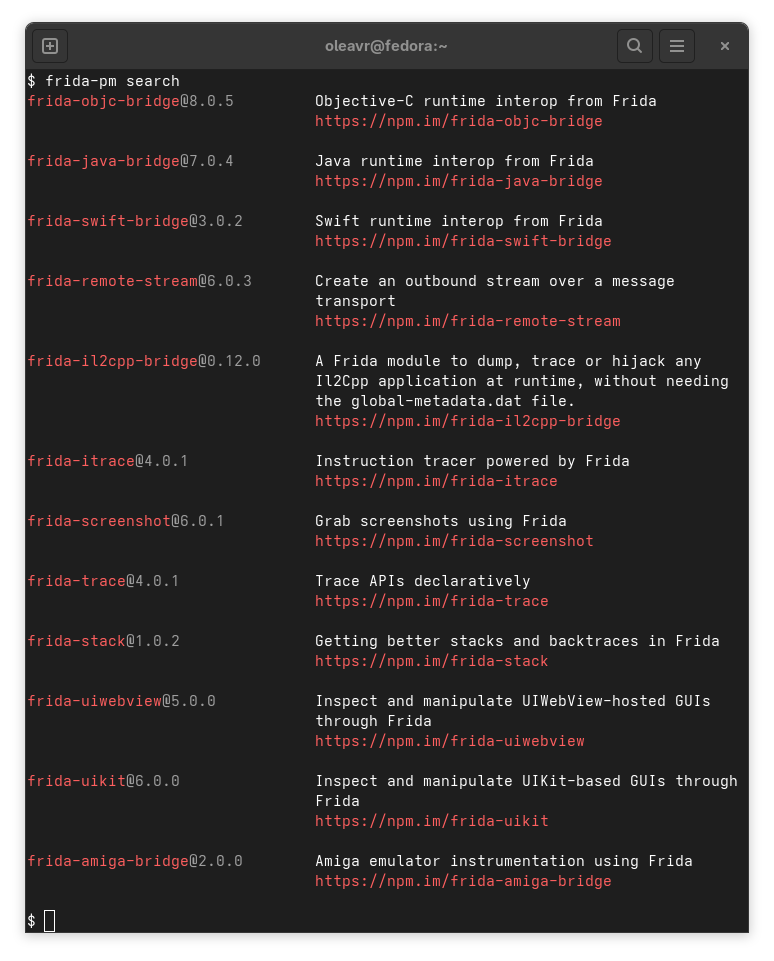
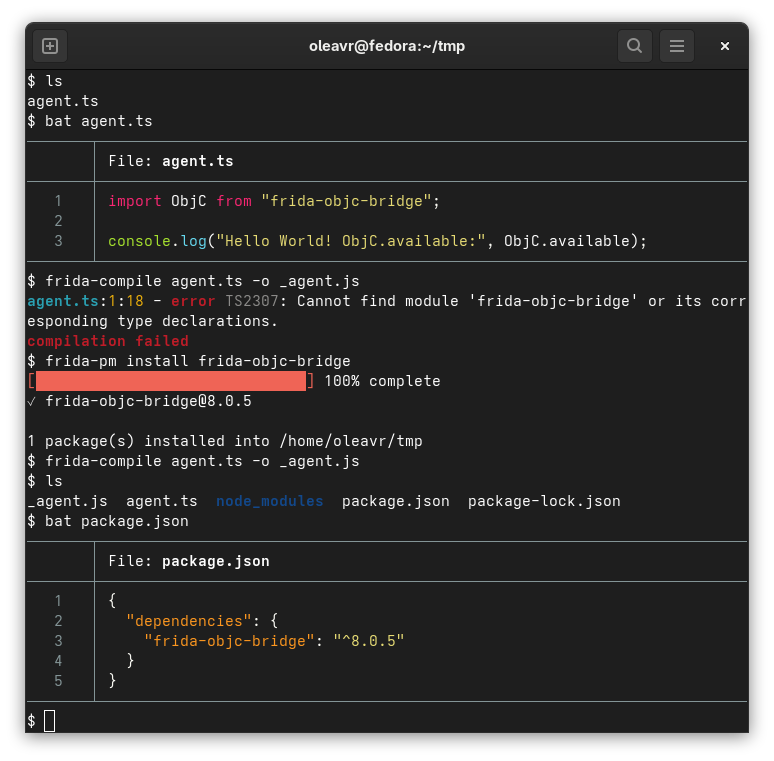









 hot3eed
hot3eed





")
")
")
")
")
")
")




 mrmacete
mrmacete





